神经网络的激活函数全解析


1
激活函数是什么?
激活函数 是一个应用于神经网络神经元输出的 非线性变换 。它的基本形式是:
output = activation(weighted_sum_of_inputs + bias)通俗地说, 激活函数决定了神经元是否应该被“激活” ——即当前输入的综合信息是否足够重要,值得被传递到下一层。
一个生动的比喻 :
想象你是一个信息处理中心的员工,每天收到大量报告
你需要决定哪些报告值得进一步处理(激活),哪些可以忽略(不激活)
激活函数就是你的 判断标准 ——它根据报告的重要性(加权输入)来决定输出什么
2
为什么需要激活函数?——核心作用
1. 引入非线性
这是激活函数 最根本 的作用。如果没有激活函数,无论神经网络有多少层,最终的输出都只是输入的线性组合。用数学表达:
没有激活函数: 仍然是线性的
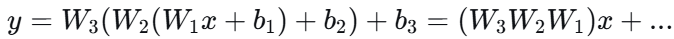
有激活函数: 引入非线性
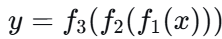
现实意义 :现实世界的问题几乎都是非线性的——图像识别、语音理解、自然语言处理,没有非线性,神经网络就只能解决线性可分的问题,能力非常有限。
2. 增强表达能力
通过堆叠非线性层,神经网络可以学习到越来越抽象的特征:
- 第一层可能学习边缘
- 第二层组合边缘形成形状
- 第三层组合形状形成物体部件
- 更深层识别完整物体
这个过程依赖于每层的非线性变换。
3. 控制梯度流动
激活函数的导数直接影响梯度在反向传播中的流动:
- 有些激活函数(如ReLU)在正区间保持梯度恒为1,缓解梯度消失
- 有些激活函数(如sigmoid)两端饱和,梯度接近0,不利于深层网络训练
4. 输出范围控制
某些激活函数将输出限制在特定范围内:
- sigmoid:输出(0,1),适合表示概率
- tanh:输出(-1,1),适合数据归一化
这对特定任务(如二分类)非常有帮助
3
常用的激活函数及其特点
我将按 经典 到 现代 的顺序,为你介绍最重要的几种激活函数。
1. Sigmoid(S型函数)
公式 :
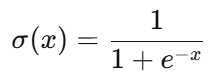
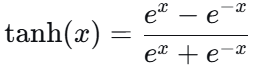
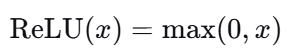
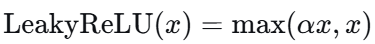
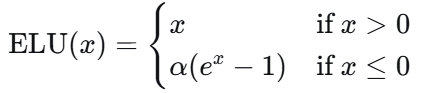
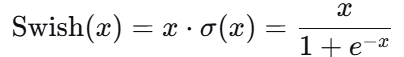

图像 :平滑的S型曲线,将任意实数映射到(0,1)之间。
特点 :
- ✅ 输出有界 :在(0,1)之间,适合表示概率
- ✅ 平滑可导 :处处可导,导数容易计算
- ❌ 梯度饱和 :当|x|很大时,梯度接近0,导致梯度消失
- ❌ 非零中心 :输出恒为正,导致后层输入偏正,影响梯度更新效率
- ❌ 计算量大 :涉及指数运算
使用场景 :
- 二分类问题的输出层(配合交叉熵损失)
- 早期神经网络(现代已较少在隐藏层使用)
2. Tanh(双曲正切)
公式 :
图像 :也是S型,但输出范围是(-1,1)。
特点 :
- ✅ 零中心 :输出均值为0,利于梯度传播
- ✅ 比sigmoid梯度更强 :在零点附近梯度为1
- ❌ 仍然存在梯度饱和 :两端趋于平缓,梯度消失
- ❌ 计算量大 :涉及指数运算
使用场景 :
- 早期RNN的常用激活函数
- 需要输出在(-1,1)范围的任务
- 某些生成模型(如GAN)中仍有应用
3. ReLU(修正线性单元)—— 现代神经网络的基石
公式 :
图像 :负数全压为0,正数保持不变。
特点 :
- ✅ 计算极简 :只需max(0,x),效率极高
- ✅ 缓解梯度消失 :正区间梯度恒为1
- ✅ 稀疏激活 :产生真正的稀疏表示(约50%神经元被激活)
- ✅ 收敛速度快 :比sigmoid/tanh快约6倍
- ❌ 神经元死亡 :如果参数更新导致某个神经元对所有输入都输出0,它的梯度将永远为0,无法恢复
- ❌ 非零中心 :输出非负
使用场景 :
- 现代CNN和Transformer的默认选择
- 大多数隐藏层的首选激活函数
4. Leaky ReLU(带泄露的ReLU)
公式 :
通常 $\alpha=0.01$
特点 :
- ✅ 解决神经元死亡 :负数区间有微小梯度,让信息仍能流动
- ✅ 保留ReLU的优点 :计算简单、正区间梯度为1
- ❌ 超参数选择 :需要选择合适的 \alpha
使用场景 :
- 当ReLU出现大量死亡神经元时的替代方案
- 某些生成模型和强化学习任务
5. ELU(指数线性单元)
公式 :
$
ELU(x)=
\begin{cases}
x & \text{if } x>0 \\
\alpha(e^x-1) & \text{if } x\leq0
\end{cases}
$
特点 :
- ✅ 负值饱和 :负数区域逐渐饱和,对噪声更鲁棒
- ✅ 均值趋近于0 :加速收敛
- ✅ 避免神经元死亡
- ❌ 计算量稍大 :涉及指数运算
6. Swish / SiLU —— 近年来的新星
公式 :
特点 :
- ✅ 处处可导,光滑连续
- ✅ 无上界有下界 :正区间无界,负区间趋于0
- ✅ 自门控机制 :可以看作是输入乘以自身的sigmoid,让网络自行调节信息流动
- ✅ 在深层网络上表现优于ReLU
使用场景 :
- Google提出的激活函数,在ImageNet等大型任务上表现优异
- Transformer的一些变体(如GPT系列)在某些层使用
7. GELU(高斯误差线性单元)—— Transformer的标配
公式 :
特点 :
- ✅ BERT、GPT等Transformer模型的默认激活函数
- ✅ 结合了Dropout和ReLU的思想 :根据输入值的大小决定保留多少信息,输入越大保留越多
- ✅ 光滑且非单调 :在负区间有一个微小的凸起
- ✅ 性能优异 :在大量NLP任务上优于ReLU
使用场景 :
- 几乎所有现代Transformer模型 (BERT、GPT、ViT等)
- NLP和视觉Transformer的首选
4
激活函数对比一览表
激活函数 | 输出范围 | 计算复杂度 | 梯度消失问题 | 神经元死亡 | 零中心 | 主要应用场景 |
|---|---|---|---|---|---|---|
Sigmoid | (0,1) | 高 | ❌ 严重 | ❌ | ❌ | 二分类输出层 |
Tanh | (-1,1) | 高 | ❌ 严重 | ❌ | ✅ | 早期RNN |
ReLU | [0,∞) | 极低 | ✅ 缓解 | ❌ 有风险 | ❌ | CNN、通用隐藏层 |
Leaky ReLU | (-∞,∞) | 低 | ✅ 缓解 | ✅ 解决 | ❌ | 避免神经元死亡时 |
ELU | (-α,∞) | 中等 | ✅ 缓解 | ✅ 解决 | ✅ | 需要负值的场景 |
Swish/SiLU | (-0.28,∞) | 中等 | ✅ 缓解 | ✅ 解决 | ❌ | 深层网络、大模型 |
GELU | (-0.17,∞) | 中等 | ✅ 缓解 | ✅ 解决 | ❌ | Transformer、NLP |
5
如何选择激活函数?
通用原则
- 首选ReLU :对于大多数深度网络,ReLU是安全、高效的起点
- 如果出现神经元死亡 :尝试Leaky ReLU或ELU
- 如果构建Transformer :直接用GELU(这是标准配置)
对于输出层 :
- 二分类:Sigmoid
- 多分类:Softmax(可视为sigmoid的多类推广)
- 回归:不用激活函数(或恒等映射)
对于RNN :
- 简单RNN:Tanh
- LSTM/GRU:内部使用Sigmoid和Tanh的组合
在机器人应用中的考量
- 实时性要求高 :ReLU计算最快,适合边缘设备
- 需要处理连续控制信号 :输出层可能用Tanh(输出-1到1)或不用激活函数
- 大模型部署 :Transformer相关模块优先考虑GELU
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号