生成一个范畴变量列表,其中分类计数是正态分布的。
生成一个范畴变量列表,其中分类计数是正态分布的。
提问于 2020-04-01 23:02:21
我的目标是生成一些由一组分类变量填充的1000行的合成数据(用pd.DataFrame对象表示)。
假设我有一个可以存在的所有可能的范畴变量的dict对象。
列表按优先级排序,其中'Aaa'是最高优先级,'NR'是最低优先级。
credit_score_types = {
'Aaa':0,
'Aa1':1,
'Aa2':2,
'Aa3':3,
'A1':4,
'A2':5,
'A3':6,
'Baa1':7,
'Baa2':8,
'Baa3':9,
'Ba1':10,
'Ba2':11,
'Ba3':12,
'B1':13,
'B2':14,
'B3':15,
'Caa':16,
'Ca':17,
'C':18,
'e, p':19,
'WR':20,
'unsolicited':21,
'NR':22
}带有中间值的dict对象key将表示正态分布的“峰值”。
在这种情况下,'Ba2'将是正态分布的“峰值”。
预期结果:
使用上述pd.DataFrame对象中的分类变量随机分配1000行的list (或长度为1000的已填充的dict )。范畴变量的分配将遵循正态分布。
'Baa2'将拥有最高的计数。
如果用每一次分类事件的计数来绘制条形图,我会观察到一个正态分布形状的图表(类似于下面)。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-04-02 01:30:10
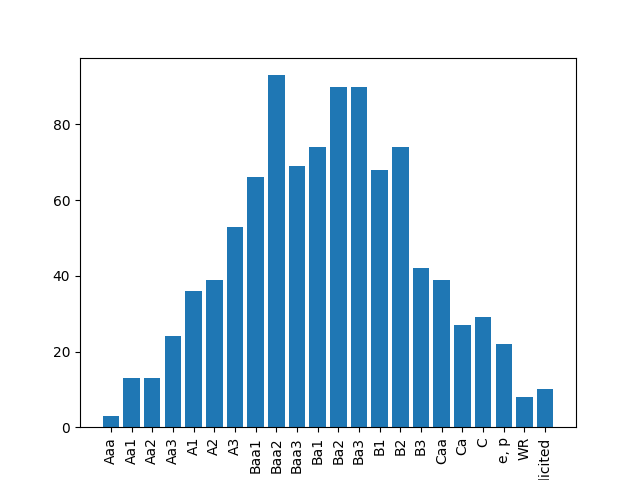
正态分布是连续的,不是绝对的。您可以考虑使用宽度为1.0的间隔绑定正态分布数据。“Baa2”的峰值为11,它实际上将计算区间10.5,11.5中的所有正态分布值,“Baa1”将计算间隔9.5,10.5中的所有值。‘'Aaa’将计算间隔中的所有值-0.5,0.5,等等.
import numpy as np
import matplotlib.pyplot as plt
credit_score_types = {
'Aaa':0,
'Aa1':1,
'Aa2':2,
'Aa3':3,
'A1':4,
'A2':5,
'A3':6,
'Baa1':7,
'Baa2':8,
'Baa3':9,
'Ba1':10,
'Ba2':11,
'Ba3':12,
'B1':13,
'B2':14,
'B3':15,
'Caa':16,
'Ca':17,
'C':18,
'e, p':19,
'WR':20,
'unsolicited':21,
'NR':22
}
# generate normally distributed data, fix random state
np.random.seed(42)
mu, sigma = credit_score_types['Ba2'], 5
X = np.random.normal(mu, sigma, 1000)
fig, ax = plt.subplots()
counts, bins = np.histogram(X, bins = np.linspace(-0.5, 22.5, 23))
# create a new dictionary of category names and counts
data = dict(zip(credit_score_types.keys(), counts))
ax.bar(data.keys(), data.values())
plt.xticks(rotation = 'vertical')
plt.show()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60985906
复制相关文章


![[422]linux查看CPU和内存使用率](https://ask.qcloudimg.com/http-save/yehe-4908043/4fbf2f87b44b2efd65e156a7df519df1.png)






相似问题
使用HTML控件创建文件上载控件
ASP.NET中的文件上载控件
asp.net/HTML文件上载控件不按预期上载多个文件
拖放文件上载,不使用asp.net中的文件上载控件
asp文件上载控件自定义文本
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
