通过geom_bar w绘制每个组的平均值
通过geom_bar w绘制每个组的平均值
提问于 2019-02-06 05:59:11
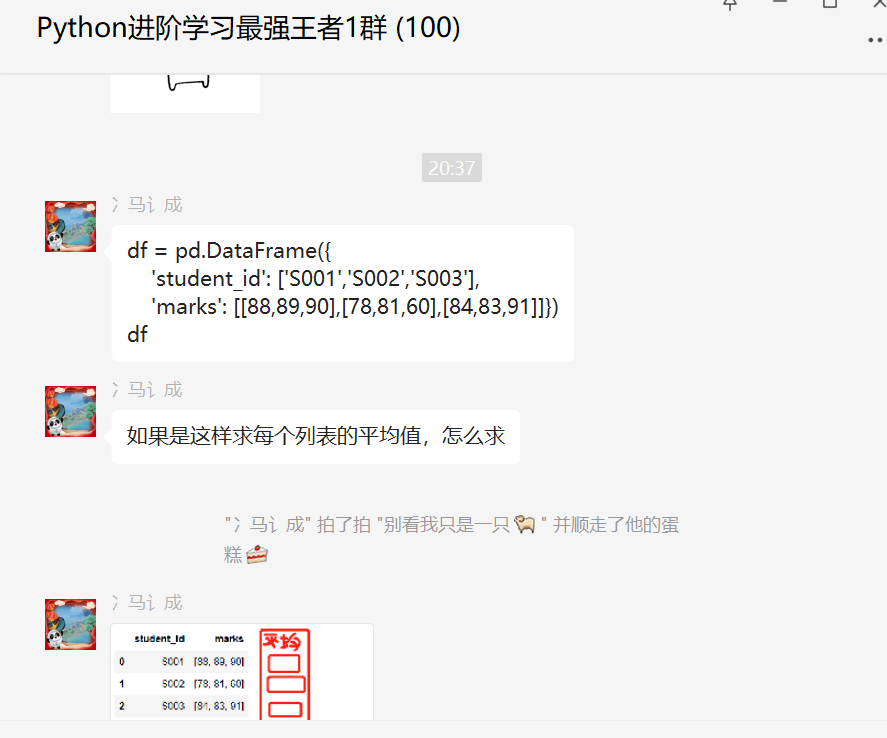
我有一个包含三列的数据框架:一个因子(在这里表示书中的一个章节)、一个数字ID (表示句子在书中出现的位置)和一个值(表示书中的字数)。它看起来像这样:
sentence.length
# A tibble: 5,368 x 3
Chapter ID Length
<fct> <dbl> <dbl>
1 1 1 294
2 1 2 19
3 1 3 77
4 1 4 57
5 1 5 18
6 1 6 18
7 1 7 27
8 1 8 56
9 1 9 32
10 1 10 25
# ... with 5,358 more rows我有一个与我想要的非常接近的图。
ggplot(data,aes(x=ID,y=Length,fill=Chapter)) +
geom_bar(stat='identity')

我想补充的是,在每一组上,都有一条水平线,表示该组的平均值。
这段代码是从另一个问题修改而来的,它让我更接近
stat_summary(fun.y = mean, aes(x = 1, yintercept = ..y.., group = Chapter), geom = "hline")但是这些线延伸到整个图上;有没有一种方法只在图的相关部分绘制平均线?我怀疑这里的问题是我的数据恰好被排序,使得group对应于图的连续部分;但是图本身的美学并没有要求这样做。
一种更接近的方法是使用geom_smooth而不是stat_summary;geom_smooth(method='lm',se=FALSE)使我非常接近。但不是线性回归,我真的只想要组的平均值(这里是每个章节的句子长度平均值)。

有没有更好/更简单的方法?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-02-06 07:39:02
我不确定这是否是最简单的方法,但它是有效的:

library(tidyverse)
library(wrapr)
df %.>%
ggplot(data = ., aes(
x = ID,
y = Length,
fill = Chapter
)) +
geom_col() +
geom_segment(data = group_by(., Chapter) %>%
summarise(
mean_len = mean(Length),
min_id = min(ID),
max_id = max(ID)
),
aes(
x = min_id,
xend = max_id,
y = mean_len,
yend = mean_len
),
color = 'steelblue',
size = 1.2
)使用%.>%管道,您可以向下传递df以在geom_segment函数中对其进行汇总。您可以通过.在%.>%之后访问df。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54547460
复制相关文章





![python求平均值的怎么编写,python 怎么求平均值[通俗易懂]](https://ask.qcloudimg.com/http-save/yehe-8223537/9d0a8c05763138544dc208708a44873b.jpg)



点击加载更多
相似问题
ggplot2 :使用geom_bar绘制平均值
按月绘制geom_bar组并显示计数
dplyr返回每个组的全局平均值,而不是每个组的平均值
geom_bar():绘制总观测值中子组的频率
T每个组的平均值
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
