图解Python numpy基本操作


本文很长,你忍一下。
Numpy是python的一个非常基础且通用的库,基本上常见的库pandas,opencv,pytorch,TensorFlow等都会用到。
Numpy的核心就是n维array,这篇文章将介绍一维,二维和多维array。
Python是一种非常有趣且有益的语言,我认为只要找到合适的动机,任何人都可以熟练掌握它。但是要记住的是,如果你只想着凭借python去找一份工作的话,不是不行,但是很难。python这种语言更适合已经有一份工作的人,多学一个技能。 可以从最简单也是最直观的数据分析学起来,并且试着从知乎知学堂出品的数据分析课开始。
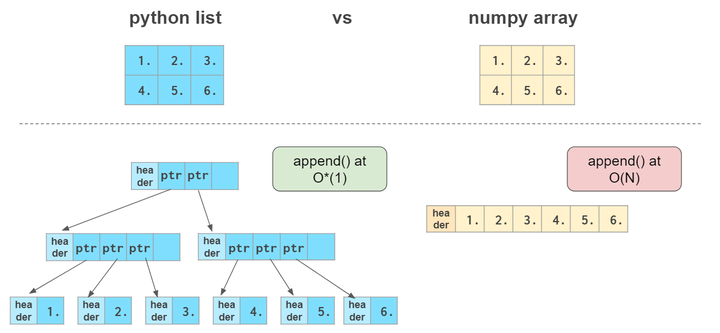
Numpy与List的异同点
他俩非常相似,同样都是容器,都能快速的取值的修改值,但是插入和删除会慢一点。

Numpy的优点
- 更紧凑,特别是多维数据
- 当数据可以向量化的时候比list更快
- 通常是同质化的,数据相同时处理更快,比如都是浮点型或者整数型
向量 Vector 或者一维向量 1D array
向量初始化
通过list转化,自动变成np类型,shape为(3,)

!注意,如果list里面的值类型不相同,那么dtype就会返回”object“
如果暂时没有想要转化的list,可以全用0代替

也可以复制一个已经存在的全0 向量

!注意,所有创建包含固定值vector的方法都有_like函数

还有经典的arange和linspace方法
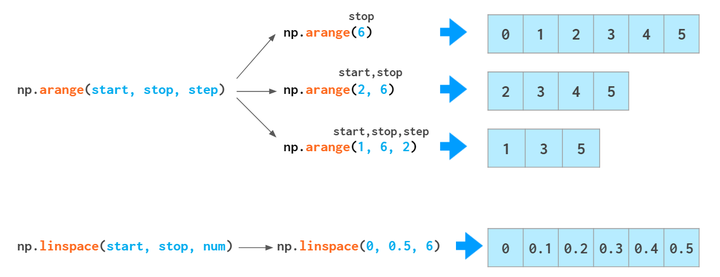
! arange方法对于数据类型敏感,比如arange(3),dtype 为int,如果你需要float类型,可以arange(3).astype(float)
生成随机array

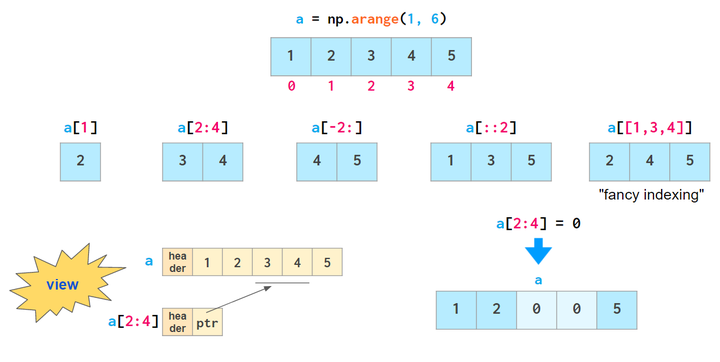
向量索引
基础的向量索引操作,只是展示部分数据,而不改变数据本身
布尔操作
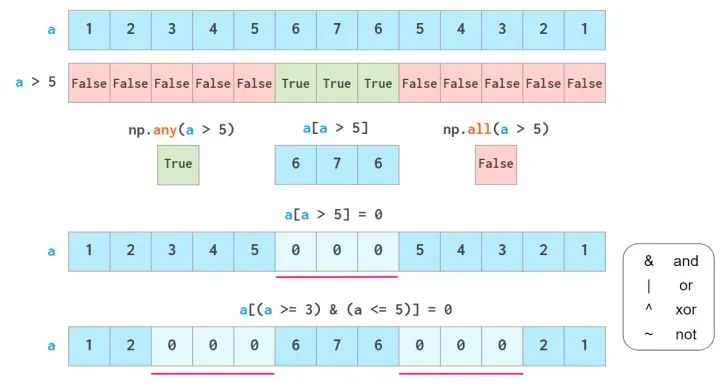
也可以用.where 和clip代替上面的方法
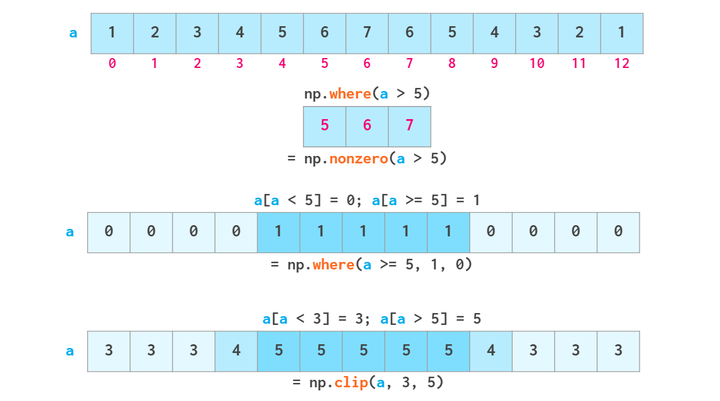
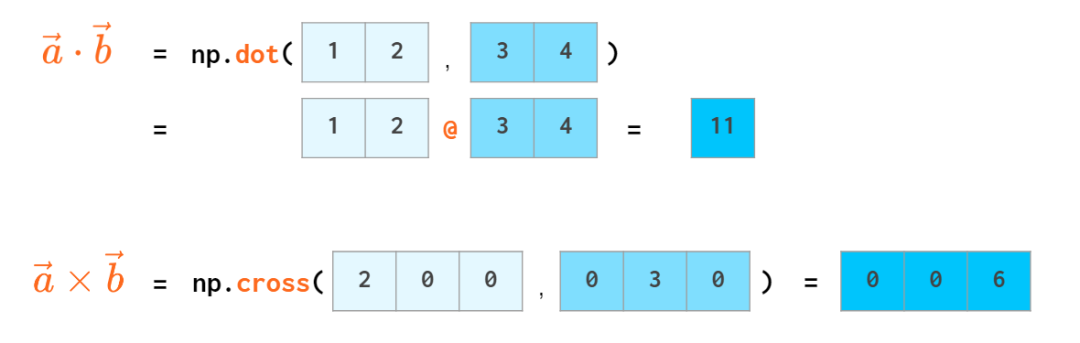
向量操作
numpy的优势就是把vector当做数做整体运算,避免循环运算
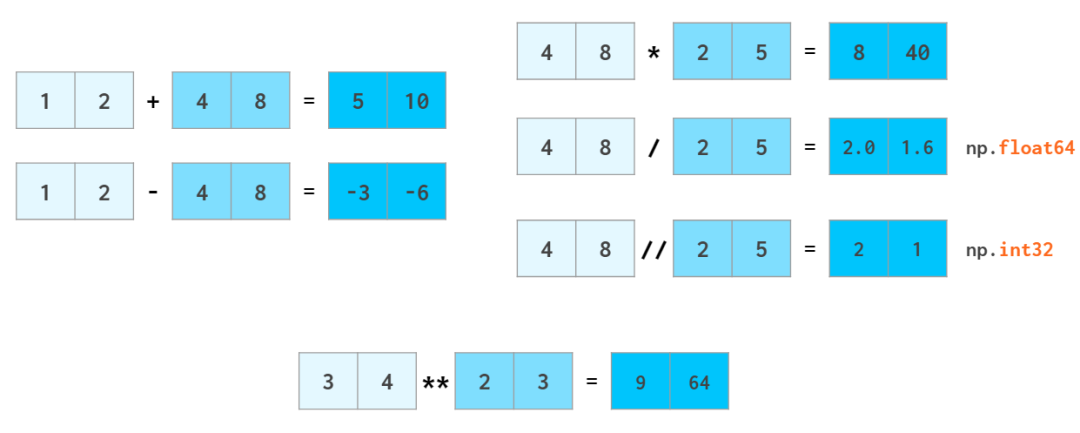
- - * /无所不能
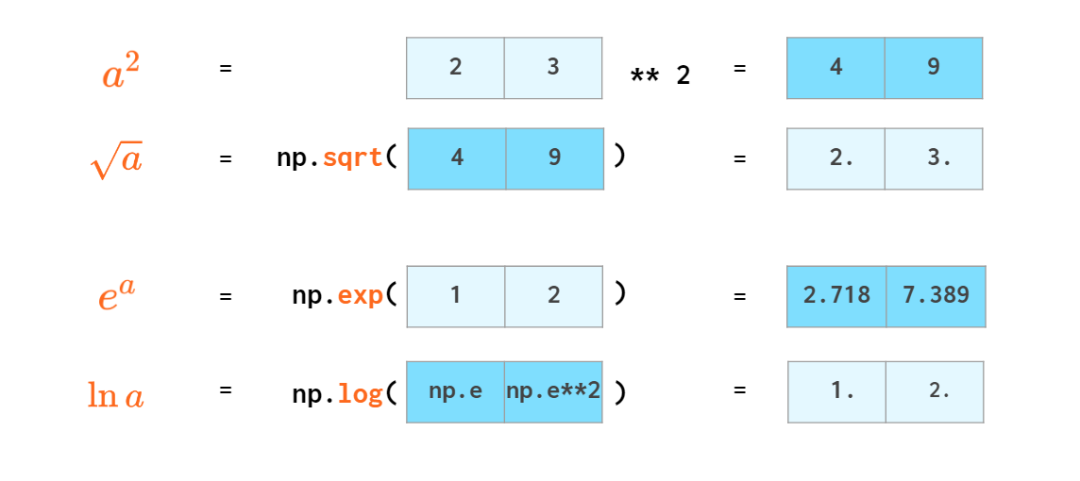
复杂的数学运算不在话下
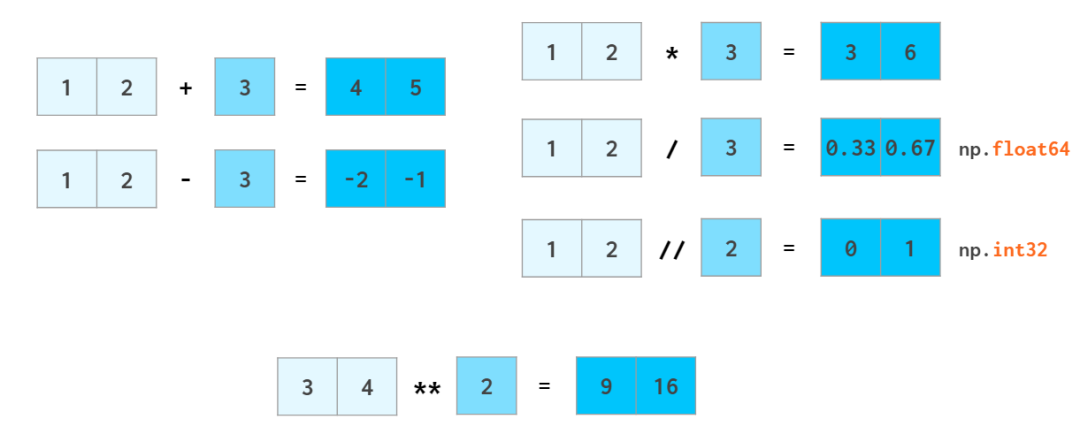
标量运算
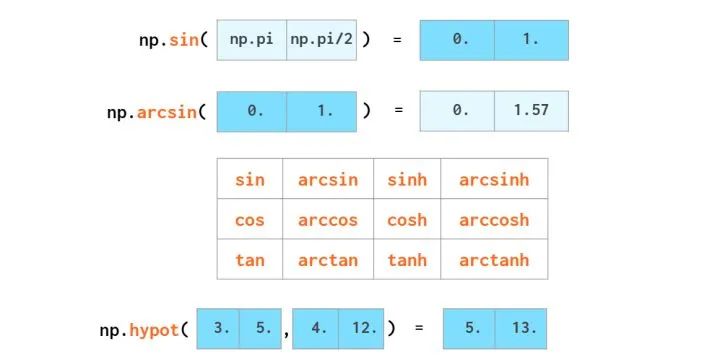
三角函数
整体取整

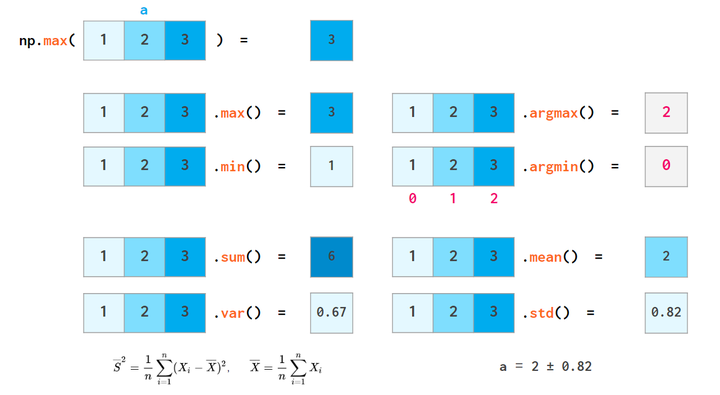
numpy还可以做基础的统计操作,比如max,min, mean, sum等
排序操作

查找操作
numpy不像list有index函数,通常会用where等操作
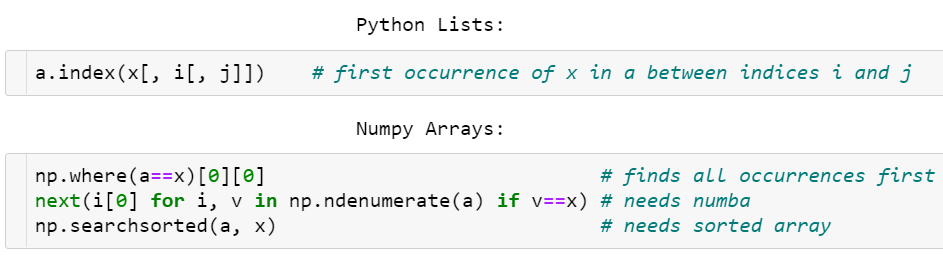
其中有三种方法:
- where,难懂且对于x处于array末端很不友好
- next,相对较快,但需要numba
- searchsorted,针对于已排过序的array
二维array,也称matrix矩阵
初始化,注意「双括号」
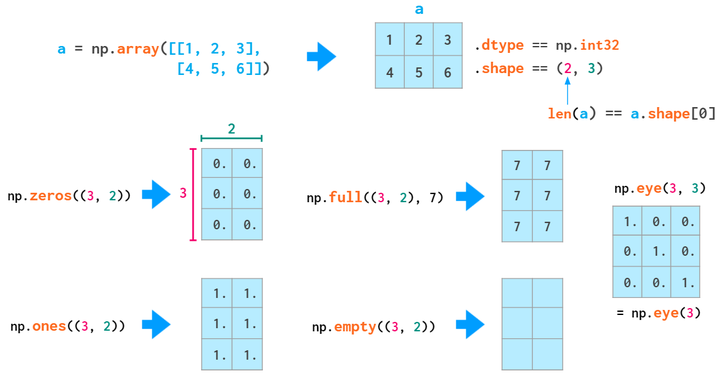
随机matrix,同一维类似

索引操作,不改变matrix本身

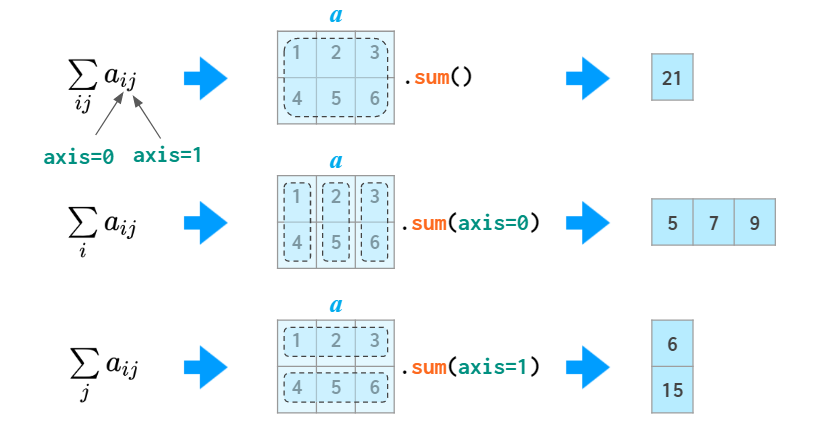
Axis 轴操作,在matrix中,axis = 0 代表列, axis = 1 代表行,默认axis = 0
matrix算术 + - * / 和 ** 都可
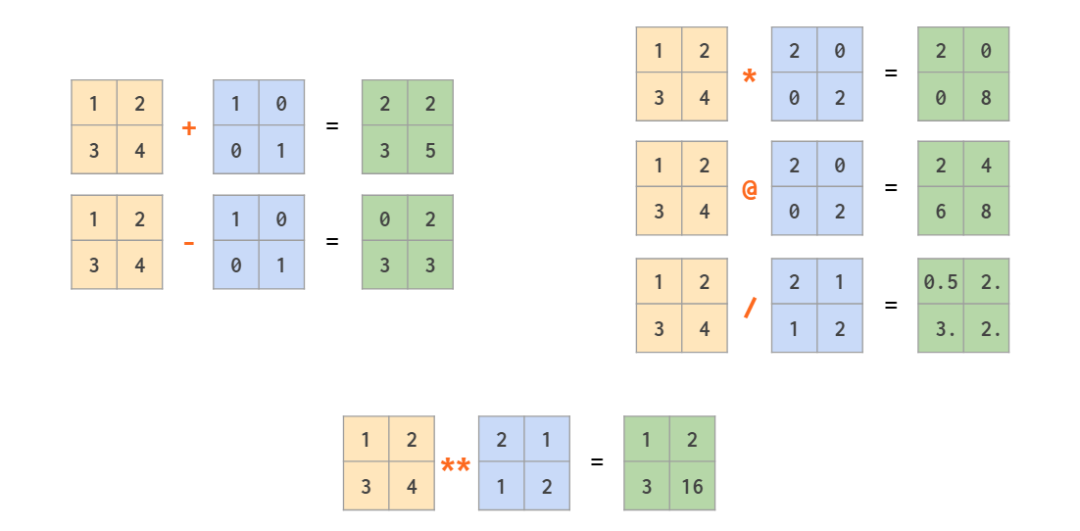
也可以matrix与单个数,matrix与vector,vector与vector进行运算

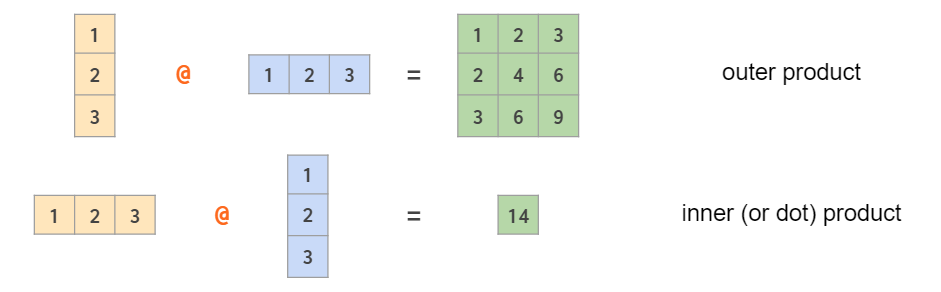
行向量 列向量
二维的转置如下,一维的也就是vector转置为自己本身
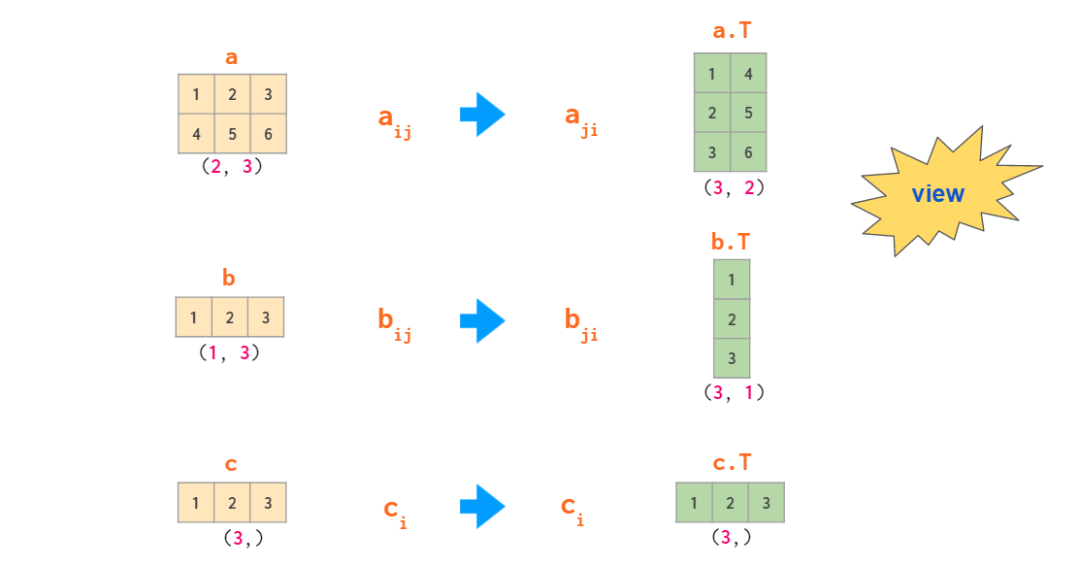
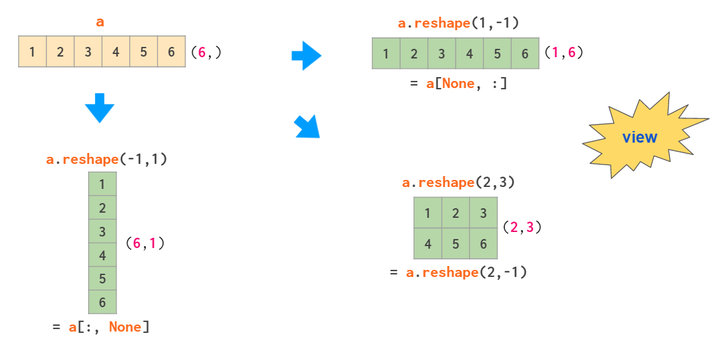
reshape改变形态
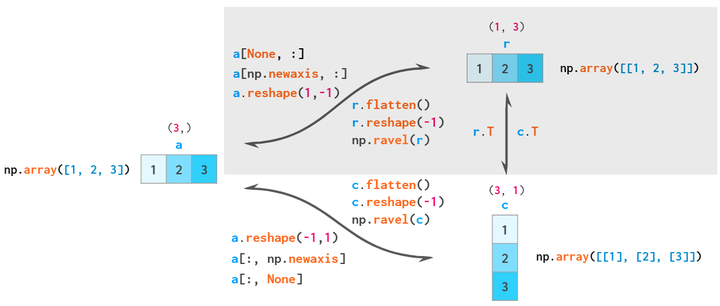
自此,三种向量,一维array,二维列vector,二维行向量
矩阵操作
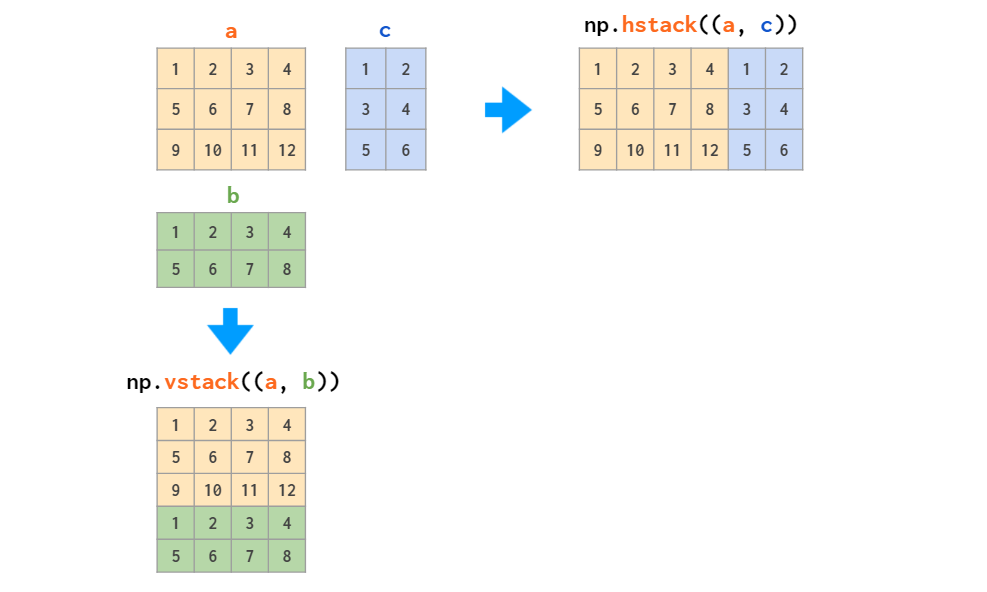
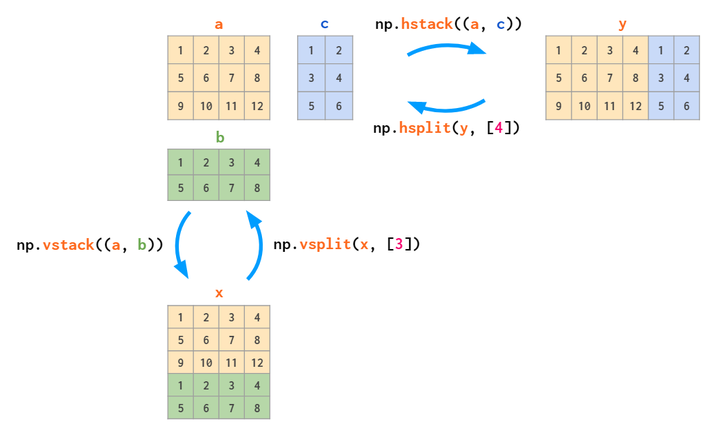
合并matrix,hstack横向,vstack纵向,也可以理解为堆叠
反向操作hsplit和vsplit
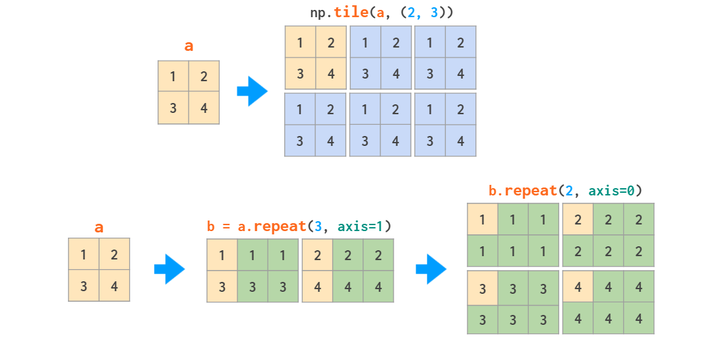
matrix的复制操作,tile整个复制,repeat可以理解为挨个复制
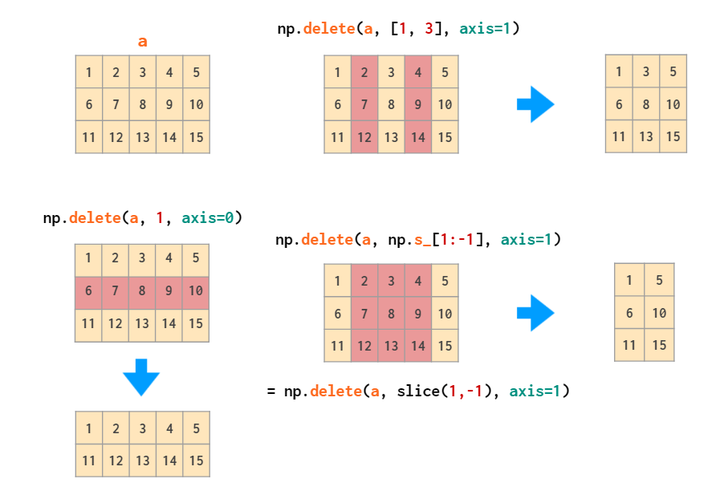
delete删除操作
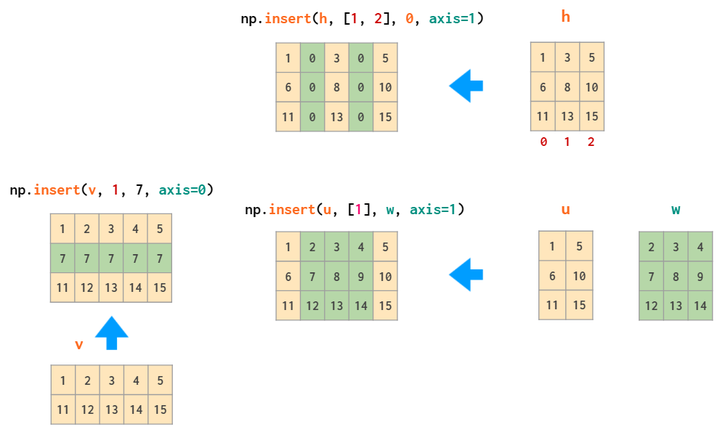
删除的同时也可以插入
append操作,只能在末尾操作
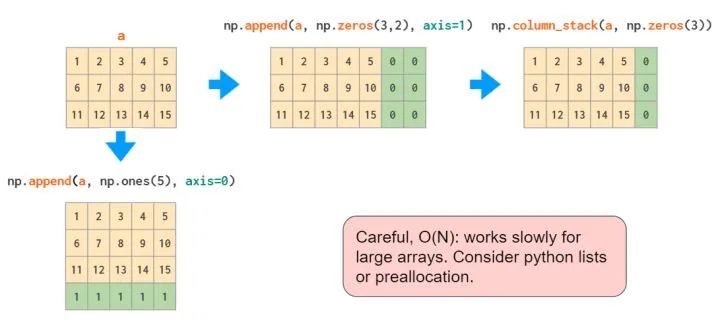
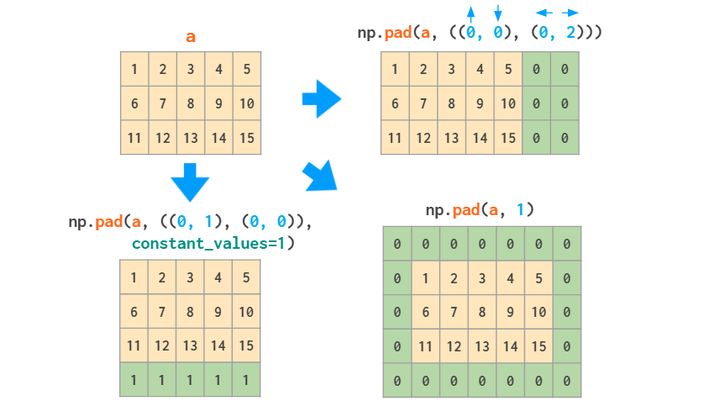
如果只增加固定值,也可以用pad
网格化
c和python都很麻烦,跟别说再大点的数了

采用类似MATLAB会更快点
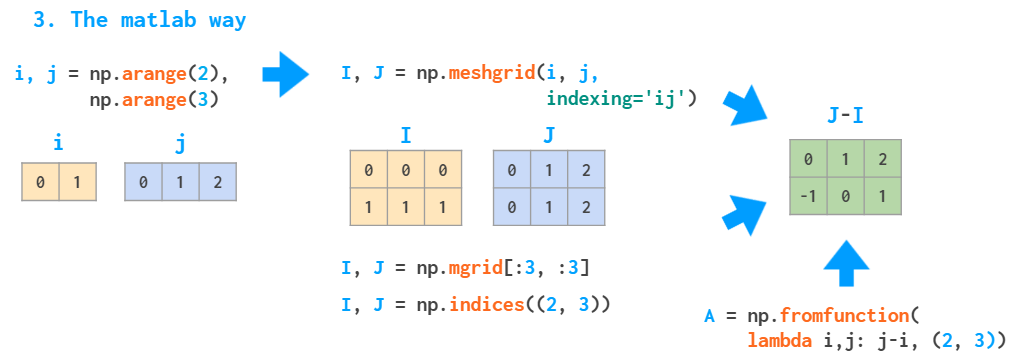
当然numpy有更好的办法

matrix统计
sum,min,max,mean,median等等
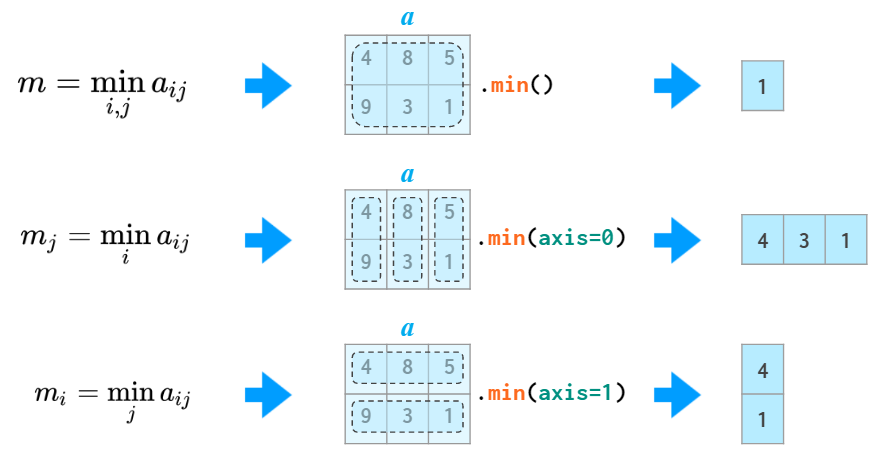
argmin和argmax返回最小值和最大值的下标
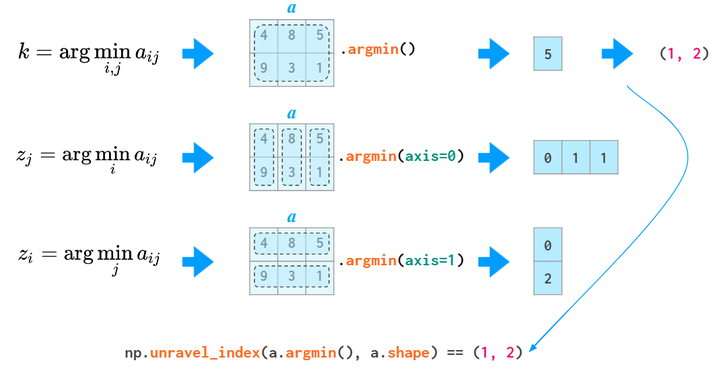
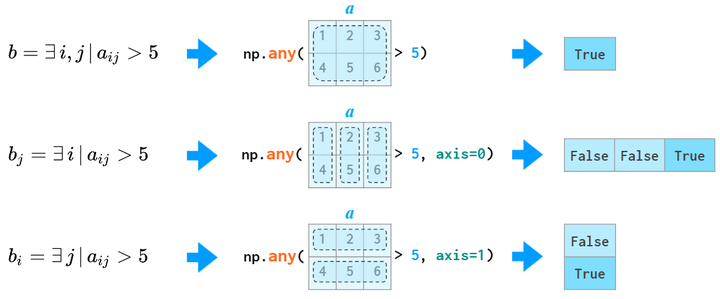
all和any也可以用
matrix排序,注意axis

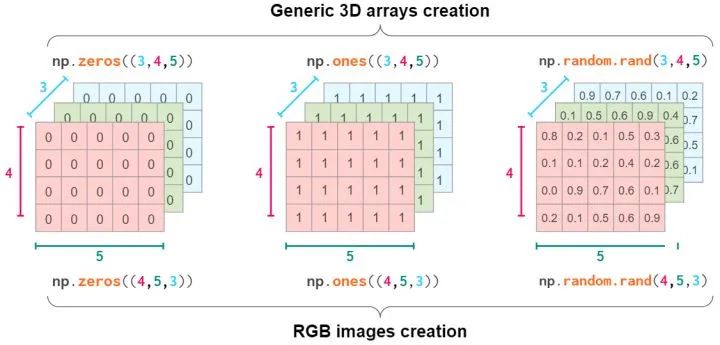
3D array或者以上
初始化,reshape或者硬来
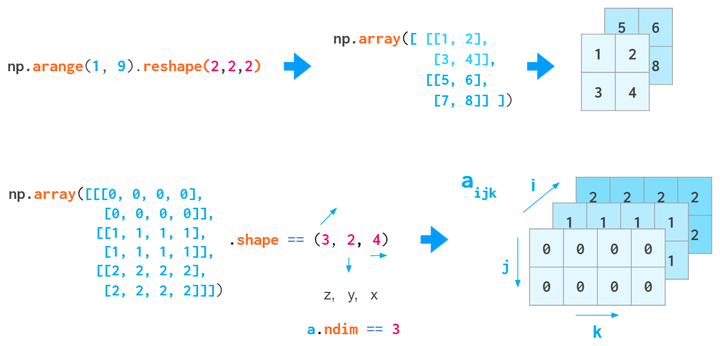
可以考虑把数据抽象成一层层的数据
就像RGB值的图像一样
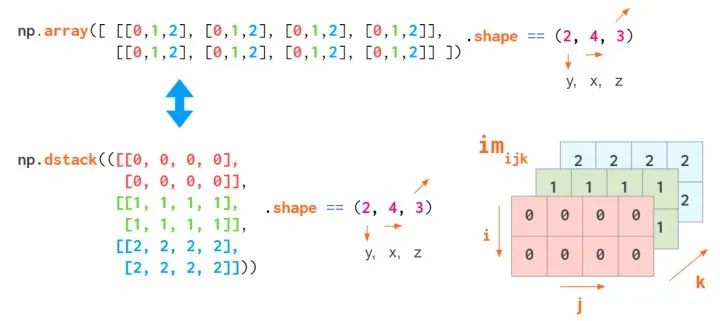
跟1D和2D类似的操作,zeros, ones,rand等
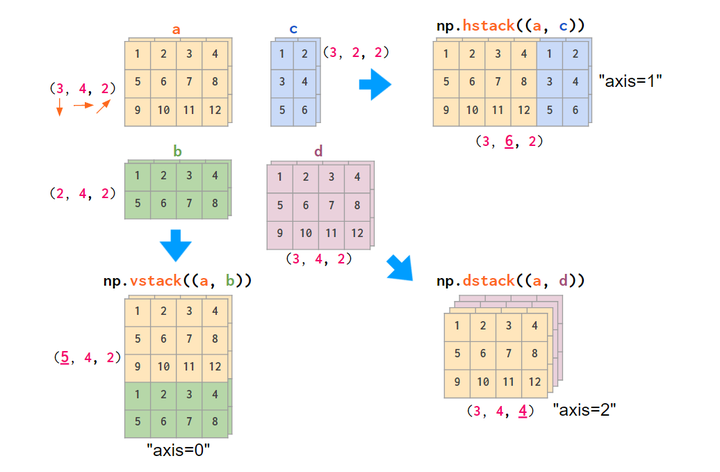
vstack和hstack照样可以用,现在多了一个dstack,代表维度的堆叠
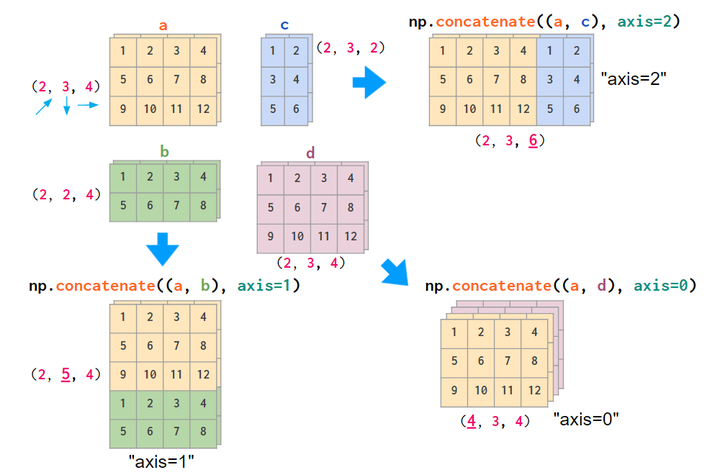
concatenate也有同样的效果
总结:
本文总结了numpy对于1D,2D和多维的基本操作。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号