用Python分析股市行情
原创
用Python分析股市行情
原创
mariolu
发布于 2024-03-22 08:49:25
发布于 2024-03-22 08:49:25
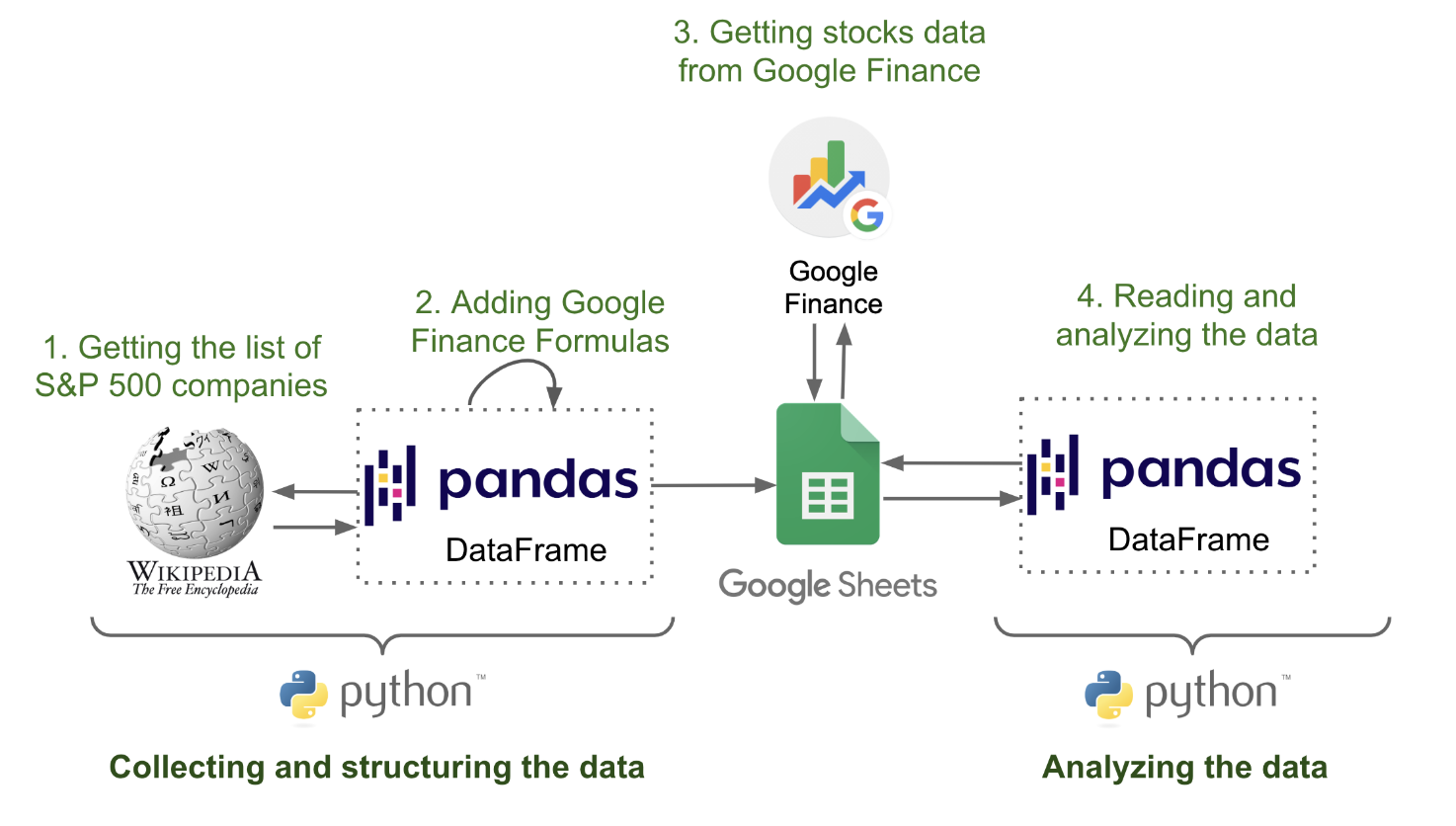
最近A股美股市场火爆,我们用Python实现一个股市分析程序。以美股S&P 500公司(头部500家公司)举例,A股也是类似,唯一不同的是找到合适的A股数据源。本教程的目的是介绍收集和分析股票数据的步骤。我们将使用 Python、Google Sheets 和 Google Finance。在第 1 部分中,我们将了解如何配置 Google Sheets,使用 Python进行交互。在第 2 节中,我们将了解如何使用 Google Finance 收集股票数据以及如何使用 Python 将这些数据存储在 Google Sheets 中。在第 3 节中,我们将了解如何从 Google Sheets 读取数据并使用 Python 和 Pandas 对其进行分析。
一、拉取S&P 500
1.1. 案例研究
在本教程中,我们将重点关注 S&P 500 公司。我们将收集以下数据:
- 3个不同日期的股价(1月1日、2月1日和3月1日)
- 每家公司的已发行股票数量
- 公司经营所在的行业/部门(遵循 GICS 分类)
收集和结构化数据后,我们将使用Python库Pandas来分析数据。
1.2. 技术设置
我们将使用以下服务和库来收集和分析数据:
- 维基百科:我们将使用此维基百科页面来获取标准普尔 500 强公司列表。
- 谷歌财经:谷歌财经是谷歌托管的一个专注于商业新闻和金融信息的网站[1]。 Google Finance 没有我们可以在 Python 中直接使用的 API,但可以使用名为 GOOGLEFINANCE 的公式从 Google Sheets 访问它。我们将使用 Python 写下 GOOGLEFINANCE 公式。
- Goole Sheets:我们将使用 Google Sheets 作为后端来存储股票数据。为了直接从 Python 与 Google Sheets 交互,我们需要 3 个库:Google Auth、gspread和gspread-pandas。我们还需要配置 Google Sheets,使用 Python 访问电子表格。
- Python 和 Pandas:我们将使用 Python和 Pandas 来收集、存储和分析数据。
1.3. GCP 中的 Google 表格配置
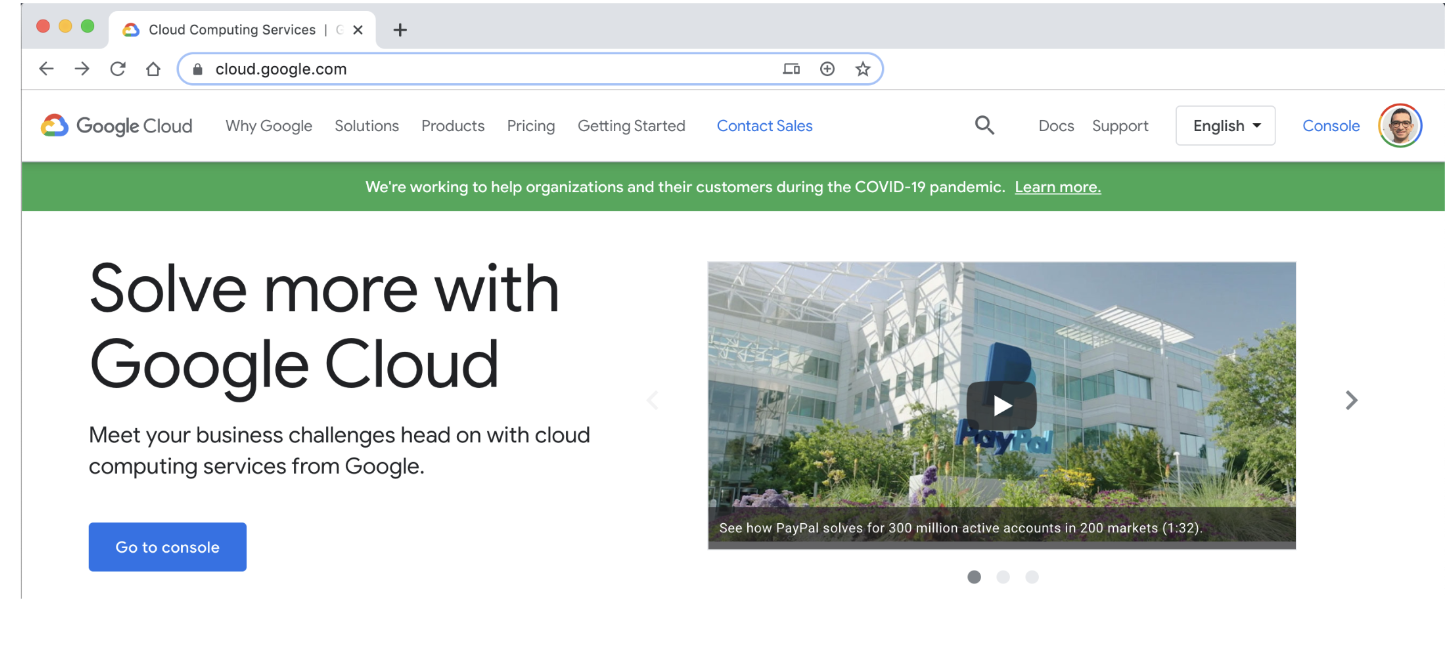
为了从 Python 访问 Google Sheets,我们需要来自 Google Cloud Platform (GCP) 的私钥,通过以下步骤获取该私钥。
- 步骤1:进入Google Cloud平台,使用Google帐户登录并点击
Console。
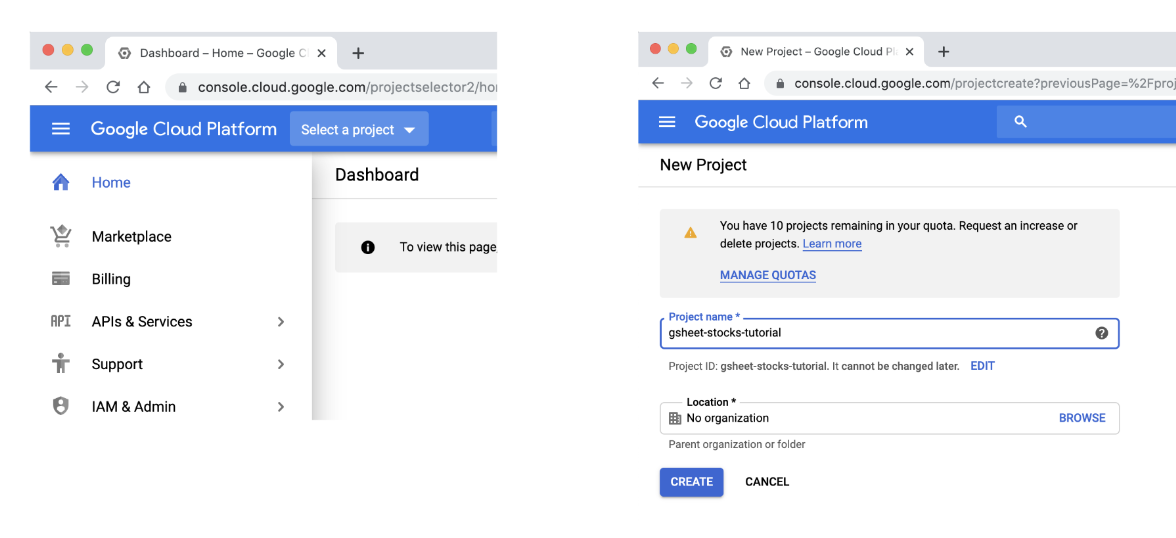
- 第二步:点击
Select a project>NEW PROJECT,输入项目名称,点击CREATE
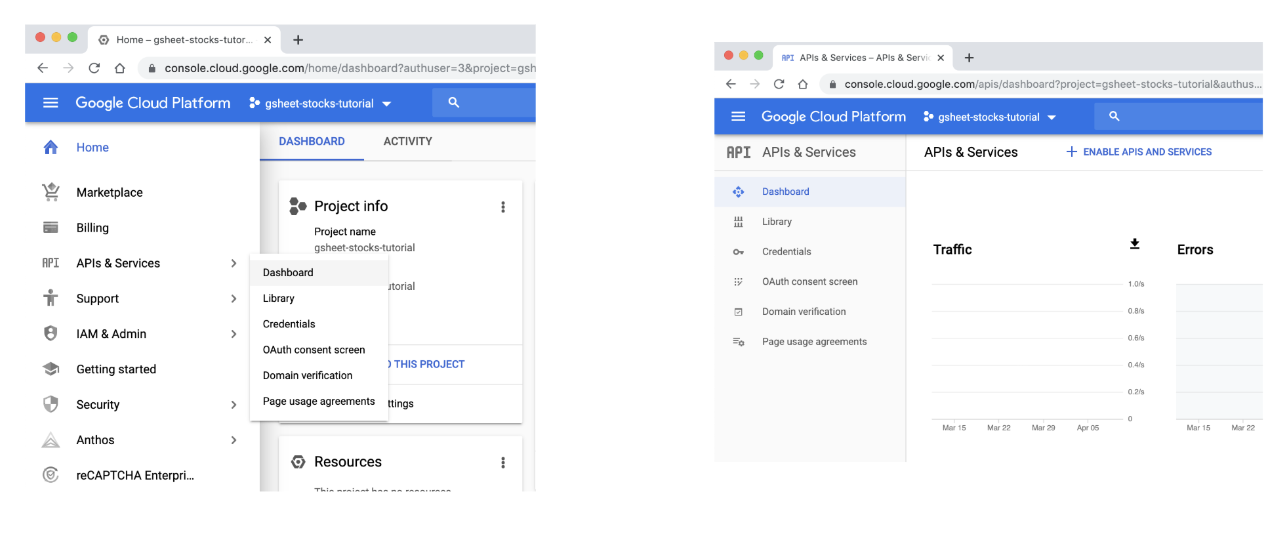
- 第三步:点击
APIs & Services>> 。DashboardENABLE APIS AND SEVICES
- 第 4 步:搜索 Google Drive API 和 Google Sheets API,然后单击
ENABLE
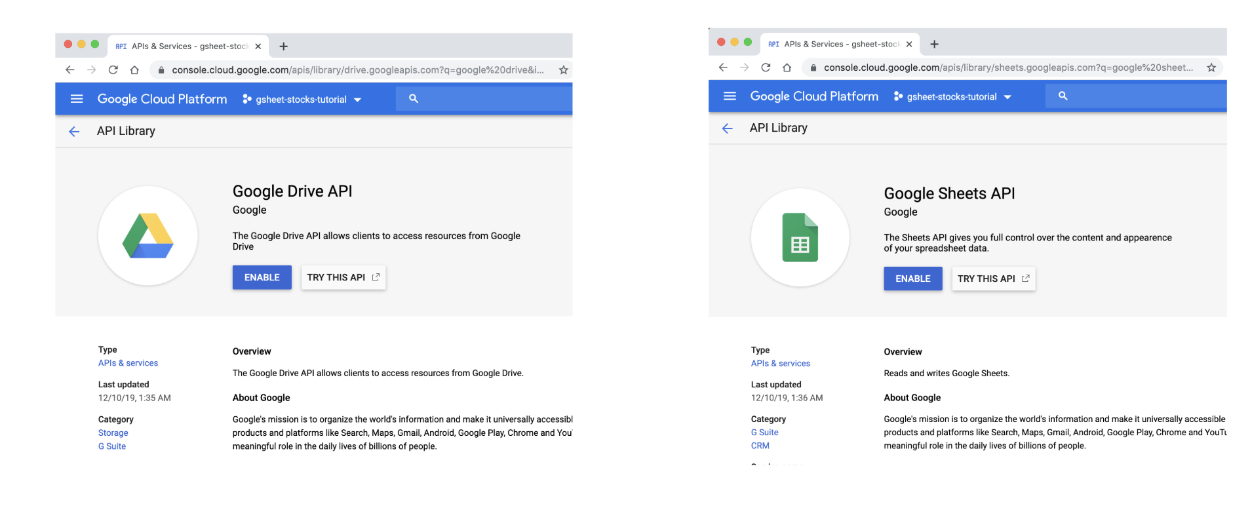
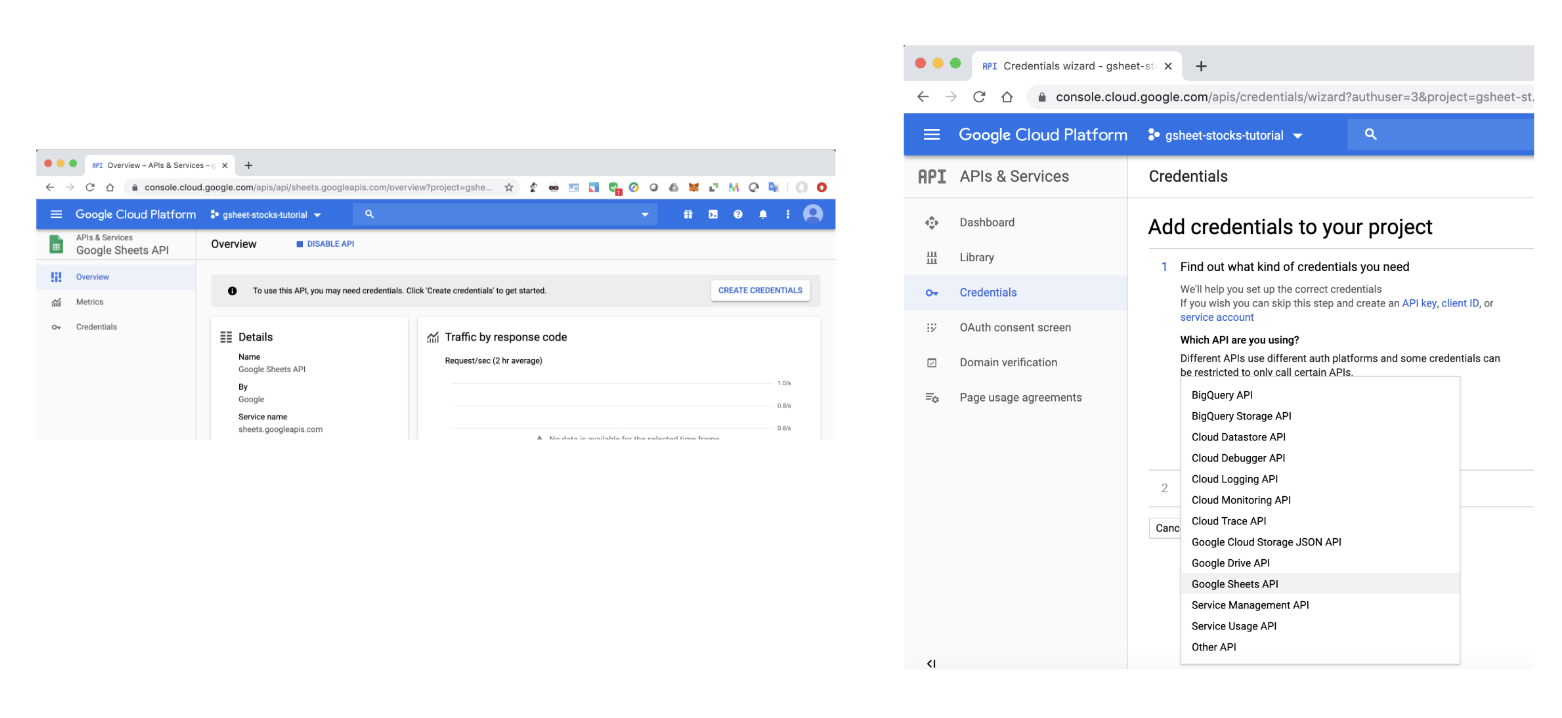
- 步骤 5:在 Google Sheets API 页面中,单击
MANAGE,CREATE CREDENTIALS然后选择Google Sheets API。
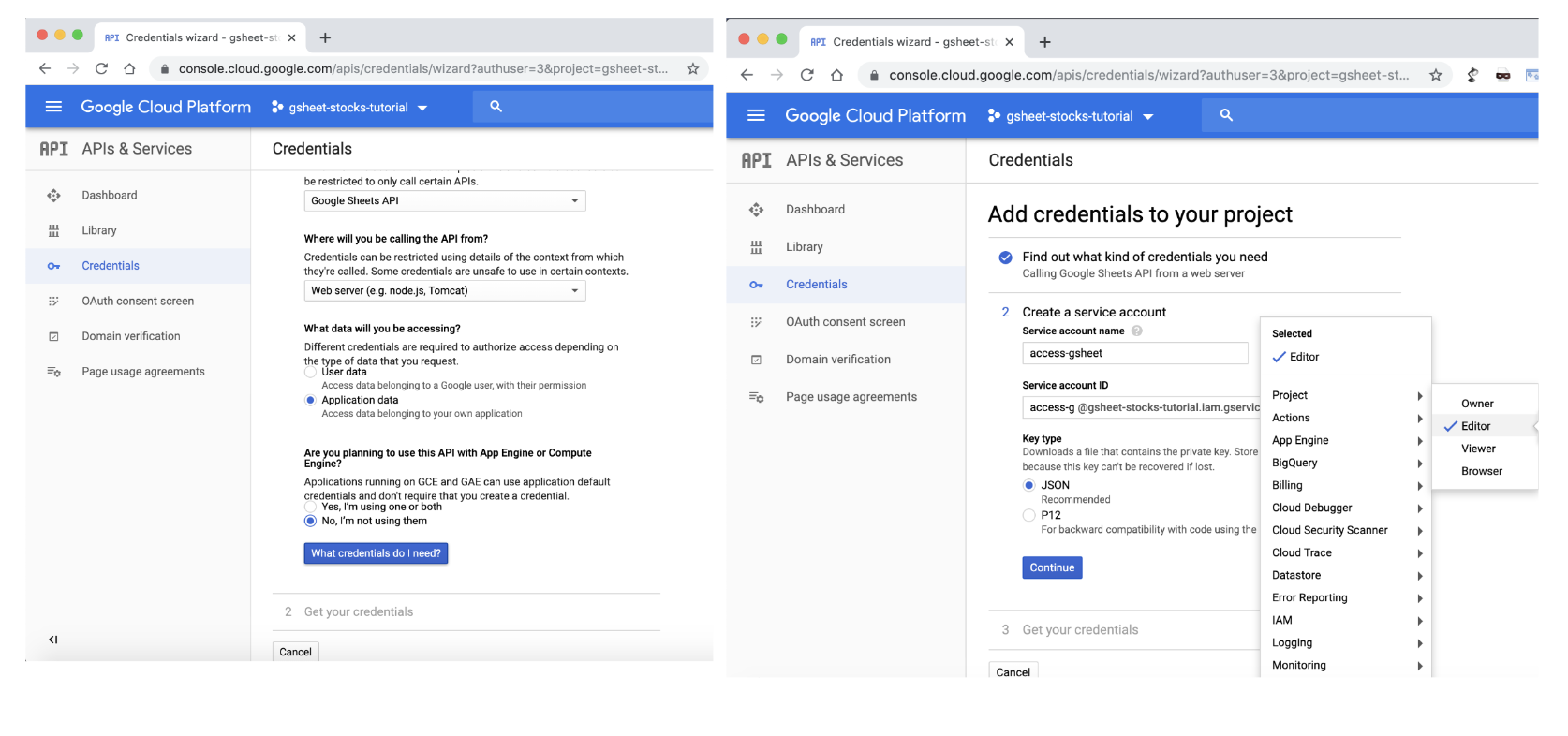
- 步骤 6:选择
Web sever,Application data然后JSON输入 API 密钥。单击Continue以下载 JSON 格式的私钥。
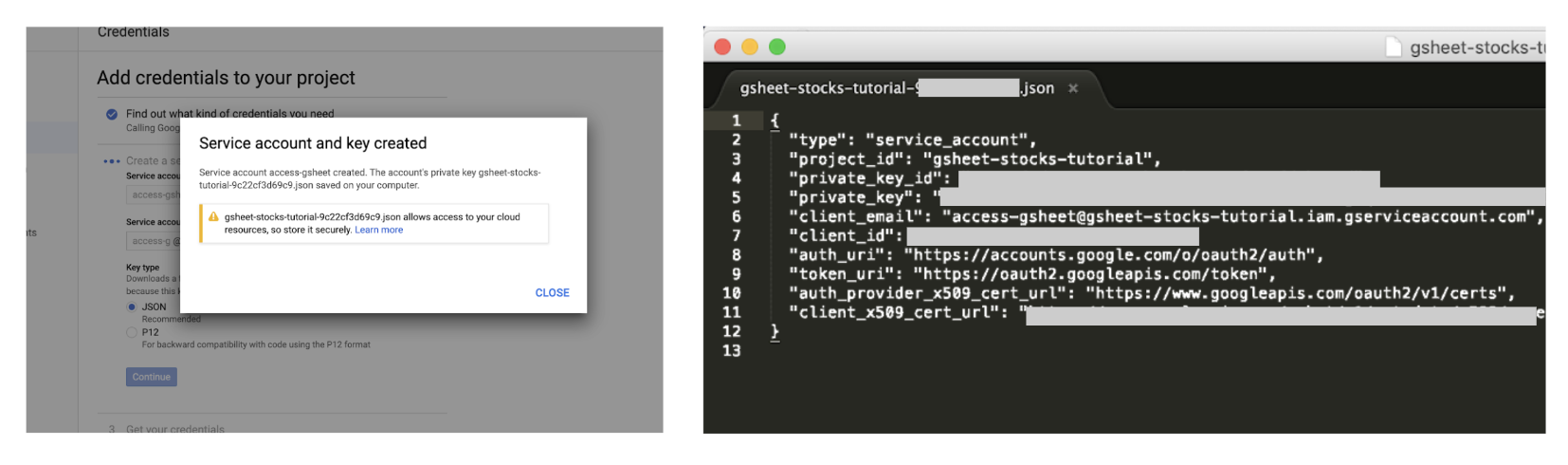
- 第 7 步:下载 JSON 文件后,将其保存在与 Jupyter Notebook 相同的文件夹中并复制信息
client_email。
1.4. Google 表格配置
最后一步,创建一个新的 Google 工作表并将其与client_email我们在上一步中创建的工作表共享。打开Google Drive,创建一个新的Google Sheet,将其名称更改为“stocks-data”。单击Share按钮,输入client_email并单击Send。
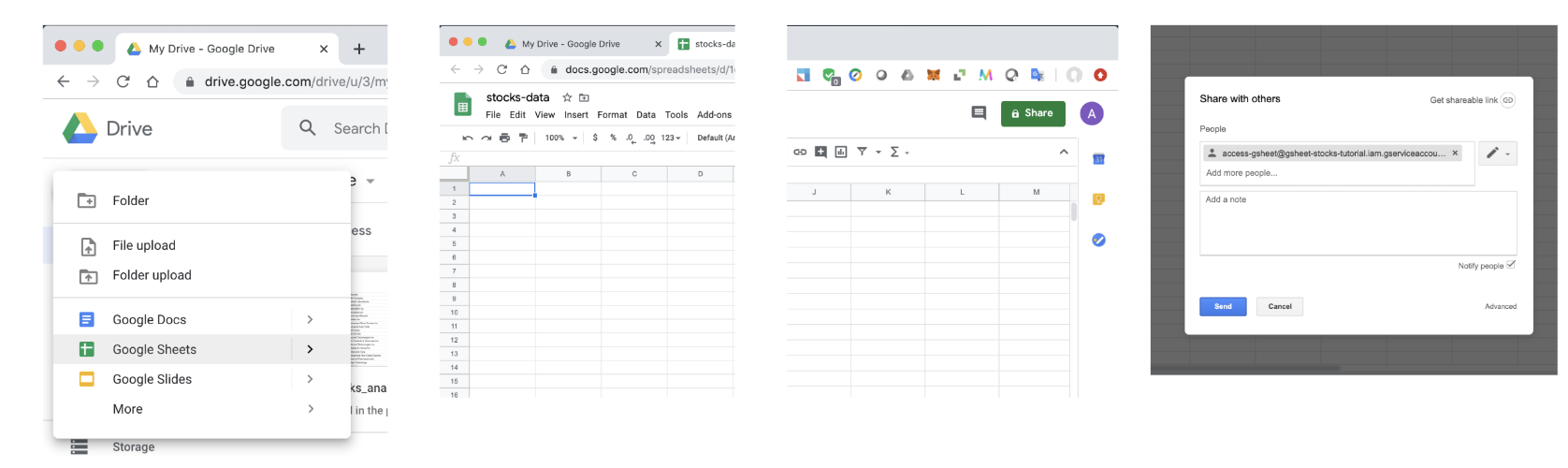
二. 收集和存储股票数据
从 Wikipedia 获取 S&P 500 公司列表
数据收集工作的第一步,获取 S&P 500 公司的名单。使用以下维基百科页面:https://en.wikipedia.org/wiki/List_of_S%26P_500_companies
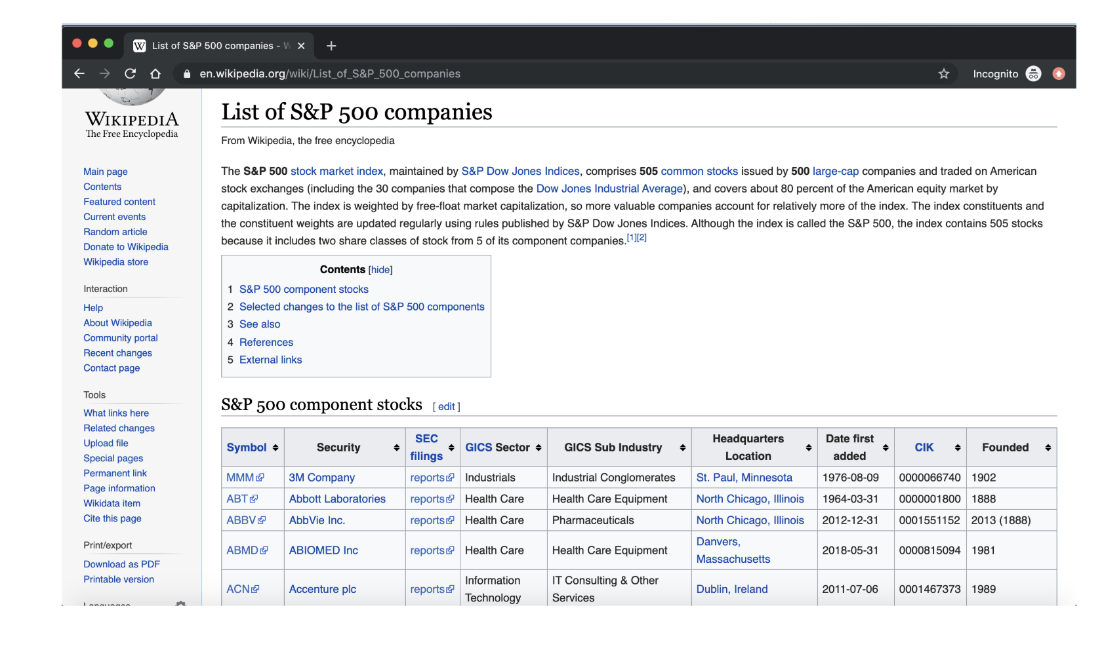
可以用Pandas读取页面,提取包含 S&P 500 公司的表并将它们存储到 Dataframe 中Pandas。
%matplotlib inline
import pandas as pd
import gspread
from google.oauth2.service_account import Credentials
from gspread_pandas import Spread, Client
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
url = 'https://en.wikipedia.org/wiki/List_of_S%26P_500_companies'
stocks_df = pd.read_html(url, header=0)[0]
stocks_df.head()象征 | 安全 | 美国证券交易委员会备案文件 | GICS 部门 | GICS子行业 | 总部地点 | 首次添加日期 | CIK | 成立 | |
|---|---|---|---|---|---|---|---|---|---|
0 | MMM | 3M公司 | 报告 | 工业 | 工业集团 | 明尼苏达州圣保罗 | 1976-08-09 | 66740 | 1902年 |
1 | ABT | 雅培实验室 | 报告 | 卫生保健 | 保健器材 | 伊利诺伊州北芝加哥 | 1964年3月31日 | 1800 | 1888年 |
2 | ABBV | 艾伯维公司 | 报告 | 卫生保健 | 药品 | 伊利诺伊州北芝加哥 | 2012-12-31 | 1551152 | 2013 (1888) |
3 | ABMD | 艾比奥梅德公司 | 报告 | 卫生保健 | 保健器材 | 马萨诸塞州丹弗斯 | 2018-05-31 | 815094 | 1981年 |
4 | 乙腈 | 埃森哲公司 | 报告 | 信息技术 | IT 咨询及其他服务 | 爱尔兰都柏林 | 2011-07-06 | 1467373 | 1989年 |
我们需要的最重要的数据是:
- Symbol: 股票代码
- Security: 公司名称
- GICS Sector: 公司按照全球行业分类标准 (GICS) 运营的部门
- GICS Sub Industry: 公司按照全球行业分类标准 (GICS) 运营的子行业.
我们可以开始查看一些统计数据。例如列表中的公司数量。
#公司数量
len ( stocks_df )输出:
505我们的名单中有 505 家公司,而不是 500 家……这是因为有些公司具有双重股权结构,并且在名单中多次上市。我们可以通过在其证券名称中搜索“Class”一词来获取这些公司的列表。
stocks_df[stocks_df['Security'].str.contains("Class")]输出[27]:
象征 | 安全 | 美国证券交易委员会备案文件 | GICS 部门 | GICS子行业 | 总部地点 | 首次添加日期 | CIK | 成立 | |
|---|---|---|---|---|---|---|---|---|---|
24 | 谷歌 | Alphabet 公司 A 类 | 报告 | 通讯服务 | 互动媒体与服务 | 加利福尼亚州山景城 | 2014-04-03 | 1652044 | 1998年 |
25 | 谷歌 | Alphabet Inc C 级 | 报告 | 通讯服务 | 互动媒体与服务 | 加利福尼亚州山景城 | 2006-04-03 | 1652044 | 1998年 |
148 | 迪斯卡 | Discovery Inc. A 级 | 报告 | 通讯服务 | 广播 | 马里兰州银泉 | 2010-03-01 | 1437107 | 南 |
149 | 光盘 | Discovery Inc. C 级 | 报告 | 通讯服务 | 广播 | 马里兰州银泉 | 2014-08-07 | 1437107 | 南 |
203 | 福克萨 | 福克斯公司 A 级 | 报告 | 通讯服务 | 电影与娱乐 | 纽约,纽约 | 2013-07-01 | 1308161 | 南 |
204 | 狐狸 | 福克斯公司 B 级 | 报告 | 通讯服务 | 电影与娱乐 | 纽约,纽约 | 2015-09-18 | 1308161 | 南 |
340 | 国家气象局 | 新闻集团A级 | 报告 | 通讯服务 | 出版 | 纽约,纽约 | 2013-08-01 | 1564708 | 南 |
第341章 | 国家气象局 | 新闻集团B级 | 报告 | 通讯服务 | 出版 | 纽约,纽约 | 2015-09-18 | 1564708 | 南 |
第457章 | UAA | 安德玛 A 级 | 报告 | 非必需消费品 | 服装、配饰和奢侈品 | 马里兰州巴尔的摩 | 2014-05-01 | 1336917 | 南 |
第458章 | UA | 安德玛 C 级 | 报告 | 非必需消费品 | 服装、配饰和奢侈品 | 马里兰州巴尔的摩 | 2016-04-08 | 1336917 | 南 |
我们有 10 家具有双层股权结构的公司上榜。如果考虑到这一点,我们可以看到列表中有 500 家的公司。
我们还可以按行业和子行业查看公司数量。
stocks_df['GICS Sector'].value_counts()输出:
工业71
信息技术 71
财务 66
非必需消费品 64
医疗保健 60
必需消费品 33
房地产 31
公用事业 28
材料 28
能源 27
通讯服务 26
名称:GICS 扇区,dtype:int64子行业中:
stocks_df['GICS Sub Industry'].value_counts()输出:
医疗保健设备 19
电力公司 13
半导体 13
工业机械 13
包装食品和肉类 12
..
房地产服务 1
摩托车制造商 1
多行业控股 1
酒店及度假村房地产投资信托基金 1
药品零售1
名称:GICS 子行业,长度:128,dtype:int642.1 添加来自 Google 财经的股票数据
现在有了 S&P 500 公司的列表,可以将 Google Sheets 公式添加到 DataFrame 中,该公式将从 Google Finance 中获取每家公司的股票价格和已发行股票数量。一旦我们将 Pandas DataFrame 保存在 Google Sheet 中,这些公式就会被执行。
可以在此处找到 GOOGLEFINANCE 公式的文档:https ://support.google.com/docs/answer/3093281
我们首先添加 3 个不同日期的股票价格:1 月 1 日、2月 1 日和 3 月 1 日。
stocks_df["Price_1_1"] = stocks_df["Symbol"].apply(lambda x: '=INDEX(GOOGLEFINANCE("' + x + '","price", "1/1/2024"),2,2)')
stocks_df["Price_2_1"] = stocks_df["Symbol"].apply(lambda x: '=INDEX(GOOGLEFINANCE("' + x + '","price", "2/1/2024"),2,2)')
stocks_df["Price_3_1"] = stocks_df["Symbol"].apply(lambda x: '=INDEX(GOOGLEFINANCE("' + x + '","price", "3/1/2024"),2,2)')接下来,我们添加公式来计算每家公司的已发行股票数量。可以使用这些数据和股票价格来计算公司在 3 个不同日期的市值。
stocks_df["Shares"] = stocks_df["Symbol"].apply(lambda x: '=GOOGLEFINANCE("' + x + '","shares")')我们首先创建一个变量,其中包含从 Google Cloud Platform 获取的凭据。
在[32]中:
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
credentials = Credentials.from_service_account_file('./gsheet-stocks.json', scopes=scope)接下来,我们在称为 的变量中读取空的谷歌工作表spread。
client = Client(scope=scope, creds=credentials)
spread = Spread("stocks_analysis", client=client)我们定义要保留的变量列表。
在[34]中:
cols_to_keep = ["Symbol", "Security", "GICS Sector", "GICS Sub-Industry",
"Price_1_1", "Price_2_1", "Price_3_1", "Shares"]最后一步是将 DataFrame 保存到 Google Sheets。
在[35]中:
spread.df_to_sheet(stocks_df[cols_to_keep])如果我们访问 Google Sheets,我们可以看到数据已正确存储。
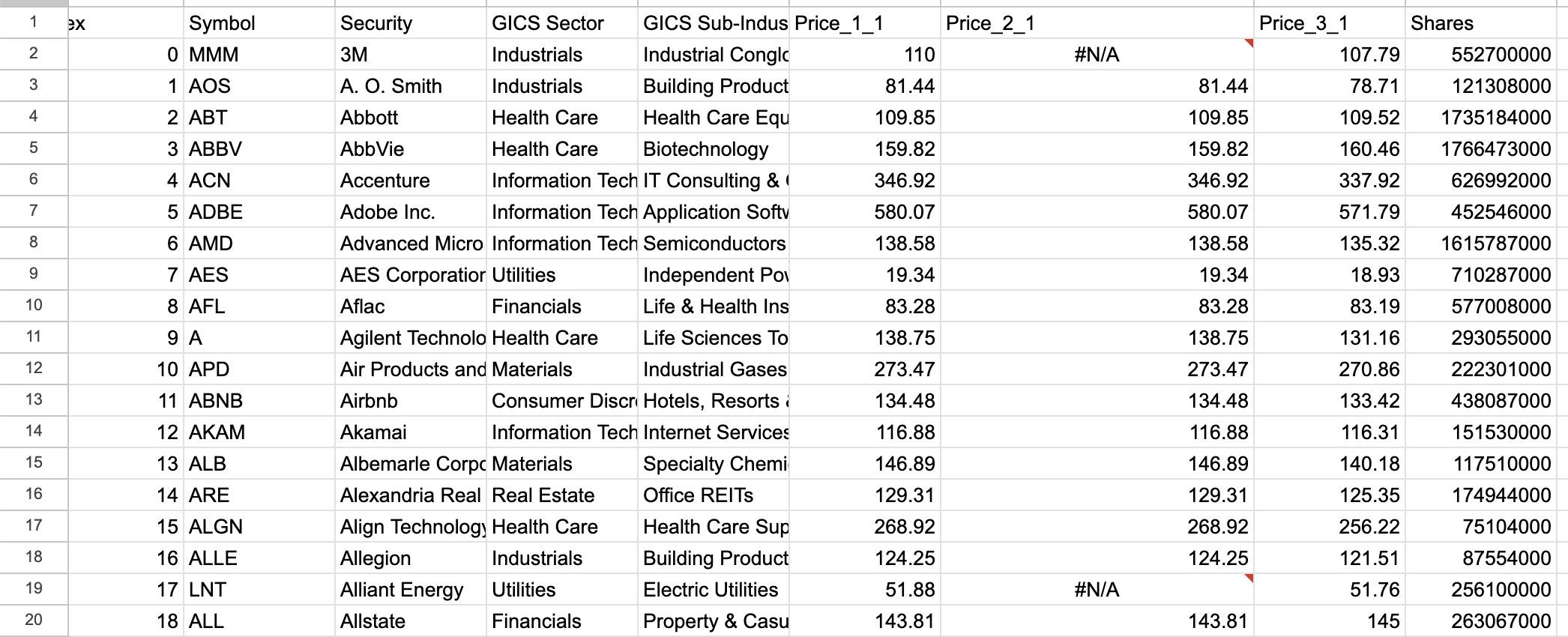
三. 分析数据
3.1.读取数据
我们首先将 Google Sheets 中的数据读取到新的 DataFrame 中。
stocks_df = spread.sheet_to_df()stocks_df.head()我们可以看到 DataFrame 包含股票价格和股票数量的实际值。
我们需要将股票价格和已发行股票数量的数据类型从 更改string为numeric。
stocks_df[["Price_1_1", "Price_2_1", "Price_3_1", "Shares"]] = \
stocks_df[["Price_1_1", "Price_2_1", "Price_3_1", "Shares"]].apply(pd.to_numeric)3.2.添加市值数据和股价变化百分比
添加市值数据
接下来,我们将添加 3 个不同日期的市值。
在[53]中:
stocks_df["Marketcap_1_1"] = stocks_df["Price_1_1"] * stocks_df["Shares"]
stocks_df["Marketcap_2_1"] = stocks_df["Price_2_1"] * stocks_df["Shares"]
stocks_df["Marketcap_3_1"] = stocks_df["Price_3_1"] * stocks_df["Shares"]添加股票价格变化百分比:
# Percentage Change from January 1st to Febuary 1st
stocks_df["PercentageChange_2_1_1_1"] = (stocks_df["Price_2_1"] - stocks_df["Price_1_1"]) / stocks_df["Price_1_1"]*100
# Percentage Change from Febuary 1st to March 1st
stocks_df["PercentageChange_3_1_2_1"] = (stocks_df["Price_3_1"] - stocks_df["Price_2_1"]) / stocks_df["Price_2_1"]*100
# # Percentage Change from January 1st to March 1st
stocks_df["PercentageChange_3_1_1_1"] = (stocks_df["Price_3_1"] - stocks_df["Price_1_1"]) / stocks_df["Price_1_1"]*1003.3.分析数据
标准普尔 500 指数总市值的变化
sum(stocks_df["Marketcap_3_1"] - stocks_df["Marketcap_1_1"]) / 10**9输出:
-335.2435168827201按行业划分的总市值变化
(stocks_df.groupby("GICS Sector").sum()["Marketcap_2_1"] - stocks_df.groupby("GICS Sector").sum()["Marketcap_1_1"]).sort_values() / 10**9( stocks_df .groupby ( "GICS 行业" ) .sum ( )[ "Marketcap_3_23" ] -stocks_df .groupby ( " GICS 行业" ) .sum ( ) [ "Marketcap_1_1" ] ) .排序值() / 10 ** 9 输出:
GICS 部门
信息技术-1592.206753
财务-1518.712229
工业-1087.991664
医疗保健-1031.715099
非必需消费品 -793.938427
通讯服务-734.977458
能量-710.786571
必需消费品 -450.846959
房地产-265.205780
材料-264.696109
公用事业-262.613530
数据类型:float64公司按股价变动百分比排名
stocks_df.sort_values(by=["PercentageChange_3_1_1_1"])[["Security", "PercentageChange_3_1_1_1"]].head(5)stock_df 。sort_values ( by = [ "PercentageChange_4_9_1_1" ])[[ "安全性" , "PercentageChange_4_9_1_1" ]] 。头( 5 )输出:
Security | PercentageChange_3_1_1_1 | |
|---|---|---|
index | ||
485 | Waters Corporation | -6.919847 |
252 | Insulet | -6.910239 |
171 | Enphase | -6.560500 |
151 | Dollar General | -6.515702 |
41 | Aptiv | -6.299213 |
print(sum(stocks_df["PercentageChange_3_1_1_1"] < 0))
print(sum(stocks_df["PercentageChange_3_1_1_1"] > 0))输出
397
102只有 102家公司 从1.1日到3.1日是上涨的
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号