【Python爬虫五十个小案例】微博热点爬取小案例~
原创
【Python爬虫五十个小案例】微博热点爬取小案例~
原创
小馒头学Python
发布于 2024-12-05 14:55:16
发布于 2024-12-05 14:55:16
今日推荐
在文章开始之前,推荐一篇值得阅读的好文章!感兴趣的也可以去看一下,并关注作者!
今日推荐:运维:推荐四款非常好用的截图工具
文章链接:https://cloud.tencent.com/developer/article/2473806
通过这篇文章,你将能够深入了解并介绍四种好用的截图工具,帮助你更快的处理文档,处理任务,例如FastStone Capture支持多种图像格式输出,满足用户在不同场合下的使用需求。更为便捷的是,它支持快捷键操作,大大提高了工作效率。无论是日常办公还是个人创作,FastStone Capture都能成为用户的得力助手,轻松应对各种截图需求
引言
微博热搜是反映社会热点的重要风向标,包含了最新的事件动态和社会趋势。爬取微博热搜数据,不仅有助于深入理解社交媒体的传播规律,还可以为热点预测和舆论分析提供支持。本篇教程将从基础环境配置到代码实现,带你一步步完成微博热搜爬虫
项目的必要性
- 数据分析需求:微博热搜数据可以用于热点事件分析、关键词提取、情感分析等。
- 舆论研究价值:研究热搜数据背后的传播规律和社会关注点,对媒体运营和品牌营销有重要参考价值。
- 个人学习提升:实现一个完整的爬虫项目,能够提升 Python 编程能力和数据处理能力。
环境配置
Python 环境
推荐版本:Python 3.7+
安装方式:访问 Python 官网 下载适合的安装包并安装。
依赖库安装
执行以下命令安装项目所需依赖库:
pip install requests beautifulsoup4 pandas matplotlib开发工具
- 推荐使用 VSCode、PyCharm 或 Jupyter Notebook,这里我采用Pycharm
爬取微博热搜的技术原理
数据来源分析
微博热搜榜可以通过以下网址访问:微博热搜榜。
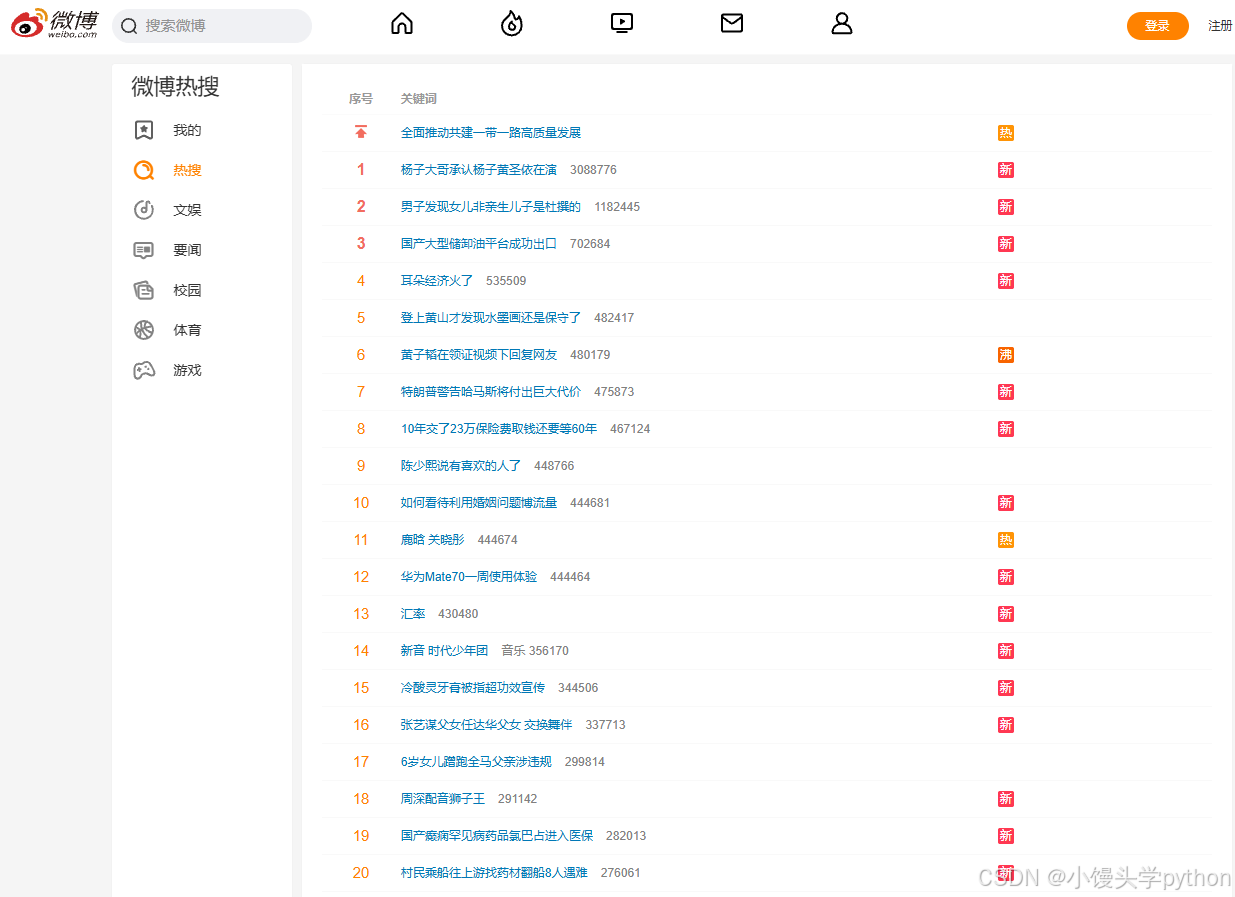
页面核心元素结构
- 页面的核心元素结构是一个 HTML 表格,用于展示热搜数据。该表格包含多个行,每一行展示一条热搜记录。每条热搜记录包括以下几个关键字段:
- 排名(Ranking):热搜词条的排名,通常按热度排序,表示该词条在当前时间段内的搜索热度。
- 关键词(Keyword):当前的热搜词条或关键字。
- 热度(Heat):热搜词的热度值,可能会显示为一个数字或百分比,反映该热搜词的受欢迎程度。
这些数据通常会以 <tr> 标签(表格行)封装,每一行中会包含 <td> 标签(表格单元格)展示排名、关键词和热度值。
链接路径
热搜关键词通常会链接到相应的搜索结果页面或专题页面,链接的路径是相对路径。例如,如果链接为 /search?q=热搜词,这时我们需要拼接完整的网页 URL。在代码中,这个拼接过程可以通过将相对路径和基础 URL 合并来实现,确保每个热搜关键词都可以链接到正确的页面。
HTTP 请求原理
为了获取目标网页的内容,我们需要通过发送 HTTP 请求来访问该页面。Python 的 requests 库提供了一个简单易用的接口,用于向目标服务器发送 HTTP 请求并获取响应。通常,HTTP 请求包含以下几个步骤:
- 发送请求:通过 requests.get() 方法发送 GET 请求。该请求包含目标 URL、请求头(如 User-Agent)等信息。
- 响应数据:服务器会返回网页的 HTML 内容,该内容通常包含网页的所有元素(如 HTML 标签、文本、图片、脚本等)。
- 处理异常:需要确保在发送请求时能够处理可能的异常(如网络错误、请求超时、响应状态码不为 200 等),确保程序的健壮性。为了模拟浏览器访问,避免被目标网站屏蔽,我们需要在 HTTP 请求中添加 User-Agent。User-Agent 是浏览器发送的请求头之一,它告诉服务器请求是来自哪种浏览器或设备。通过设置 User-Agent,我们能够伪装成正常的浏览器请求,从而减少被目标网站识别为爬虫的风险。
数据解析与提取
获取到网页的 HTML 内容后,我们可以使用 BeautifulSoup 来解析网页。BeautifulSoup 是一个 Python 库,它可以帮助我们快速而方便地从 HTML 文档中提取出我们需要的数据。
- 解析 HTML 内容:使用 BeautifulSoup 将 HTML 文档转换为可操作的对象。可以选择不同的解析器,通常我们使用默认的 html.parser。
- 查找目标数据:通过 CSS 选择器或标签查找方法定位到网页中的目标数据。例如:
使用 find_all() 方法查找所有的 <tr> 标签,每一行数据就代表一个热搜项。
使用 find() 或 find_all() 方法找到特定的标签,如 <td> 来提取排名、关键词和热度信息。
- 数据清洗与提取:提取目标数据后,通常需要对其进行清洗和格式化。例如,将关键词去除多余的空格,提取热度值中的数字部分,处理可能出现的缺失数据等。HTTP 请求原理通过 requests 库发送 HTTP 请求获取页面内容。为避免被目标网站屏蔽,需要设置 User-Agent 模拟浏览器访问
数据解析与提取
使用 BeautifulSoup 解析 HTML 内容,通过 CSS 选择器定位目标数据
代码实现
代码结构与模块划分
文件名&功能
- weibo_scraper.py 爬取数据的核心逻辑
- data_handler.py 数据清洗与保存功能
- visualization.py 数据可视化与展示
数据爬取实现
import requests
from bs4 import BeautifulSoup
def fetch_weibo_hot_search():
url = "https://s.weibo.com/top/summary?cate=realtimehot"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
table = soup.find("table", class_="table")
rows = table.find_all("tr")[1:] # 跳过表头
data = []
for row in rows:
cols = row.find_all("td")
rank = cols[0].text.strip()
keyword = cols[1].text.strip()
link = "https://s.weibo.com" + cols[1].a["href"]
heat = cols[2].text.strip() if len(cols) > 2 else "N/A"
data.append({"排名": rank, "关键词": keyword, "热度": heat, "链接": link})
return data数据清洗与保存
import pandas as pd
def save_to_csv(data, filename="weibo_hot_search.csv"):
if not data:
print("无数据保存")
return
df = pd.DataFrame(data)
df.to_csv(filename, index=False, encoding="utf-8-sig")
print(f"数据已保存至 {filename}")主程序
if __name__ == "__main__":
data = fetch_weibo_hot_search()
save_to_csv(data)数据可视化
import pandas as pd
import matplotlib.pyplot as plt
def visualize_data(filename="weibo_hot_search.csv"):
df = pd.read_csv(filename)
df = df[df["热度"] != "N/A"] # 过滤无热度数据
df["热度"] = df["热度"].astype(int) # 转换为数值类型
# 绘制热搜热度前10
top_10 = df.head(10)
plt.figure(figsize=(10, 6))
plt.barh(top_10["关键词"], top_10["热度"])
plt.xlabel("热度")
plt.ylabel("关键词")
plt.title("微博热搜热度前10")
plt.gca().invert_yaxis() # 反转Y轴显示顺序
plt.show()
visualize_data()以上内容仅供参考,若有需求请联系我
结语
通过本教程,我们从环境搭建、代码实现到数据展示与分析,完整实现了一个微博热搜爬取项目。
本项目不仅可以作为学习爬虫的入门案例,还可扩展为更复杂的热点分析系统。如果你有任何疑问或建议,欢迎留言讨论!

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号