熊猫:将列中的列表展开为不同的行
熊猫:将列中的列表展开为不同的行
提问于 2015-11-01 05:01:07
我有一个有大量列的数据集,其中包含多个值(从google导入,这些列允许多个选择)。我一开始就把它们作为列表导入。
现在,我想根据这些列中的一些值来分析数据,即
df = pd.DataFrame(dict(a=[(1,2),(2,3),(1,)], b=[(1,3),(2,5),], c=['a','b','c']))
a b c
0 (1, 2) (1, 3) a
1 (2, 3) (2, 5) b
2 (1) () c我想绘制一个条形图,其中X将是不同于列a和b的不同值(它们共享相同的一组选项),而Y将是拥有该选项的行的总数:
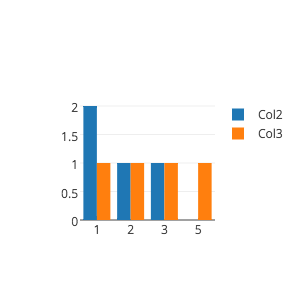
回答 2
Stack Overflow用户
回答已采纳
发布于 2015-11-01 05:33:40
您可以通过对列进行求和(基本上是连接内容),然后对它们调用pd.value_counts来做到这一点。例如(稍微修改dataframe定义,这样它就不会引发错误):
df = pd.DataFrame(dict(a=[(1,2),(2,3),(1,)],
b=[(1,3),(2,5),()],
c=['a','b','c']))
counts = pd.DataFrame({col: pd.value_counts(df[col].sum())
for col in ['a', 'b']})
counts.plot(kind='bar')
(先前对问题原文的答复):
您可以使用一个映射获取2在a中的所有行。
>>> df = pd.DataFrame(dict(a=[[1,2],[2,3],[1,3]], b=['a','b','c']))
>>> df
a b
0 [1, 2] a
1 [2, 3] b
2 [1, 3] c
>>> df[df.a.map(lambda L: 2 in L)]
a b
0 [1, 2] a
1 [2, 3] b您可以使用一个groupby和一个filter来完成类似的任务,但首先必须将a值转换为元组,以便它们是可选的(并且可以是组键):
>>> df.groupby(df.a.map(tuple)).filter(lambda group: 2 in group.name)
a b
0 [1, 2] a
1 [2, 3] b获得这些结果之一后,可以使用(例如result['a'] = 2 )替换a列中的值。
Stack Overflow用户
发布于 2015-11-01 05:34:06
我们可以使用布尔索引来过滤记录,在列2中不包含'a'。
df = pd.DataFrame(dict(a=[[1,2],[2,3],[5,6]], b=['a','b','c']))
df
Out[16]:
a b
0 [1, 2] a
1 [2, 3] b
2 [5, 6] c
df[df.a.apply(lambda x: 2 in x)]
Out[17]:
a b
0 [1, 2] a
1 [2, 3] b页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/33462401
复制相关文章






点击加载更多
相似问题
将熊猫数据帧中的列表展开为其他行
熊猫-将数组展开为列
如何使用Python熊猫将某些列展开为行
熊猫Dataframe:将包含列表的行展开为多行,并为所有列建立索引
将字符串值的熊猫列列表展开为多个列。
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

社区富文本编辑器全新改版!诚邀体验~
全新交互,全新视觉,新增快捷键、悬浮工具栏、高亮块等功能并同时优化现有功能,全面提升创作效率和体验
腾讯云开发者
