带和不带滤波器的DAX计算函数
如果我们将CALCULATE函数与不带滤波函数一起使用,那么它的结果有什么不同?假设我们有这两种措施:
Measure1 = CALCULATE([X], 'FactTable'[Color]="Red")
Measure2 = CALCULATE([X], FILTER('FactTable', 'FactTable'[Color]="Red")更新
是否有一种方法可以通过使用其他函数(如Measure2或ALLSELECTED )来修改Measure1,以使其返回与Measure1完全相同的结果?
回答 4
Stack Overflow用户
发布于 2018-05-24 05:32:22
不仅结果如此,而且这两项措施取得这些结果的方式也不尽相同。
我创建了两个与您的示例类似的度量来测试这一点:
TestAvgNoFilter = CALCULATE([PrcAvg]; cal[ReadDate]=DATE(2018;05;23))
TestAvgFilter = CALCULATE([PrcAvg]; filter(cal; cal[ReadDate]=DATE(2018;05;23)))当我简单地将它们都扔到枢轴表中时,没有任何额外的字段或切片器,当然它们都显示出相同的结果:
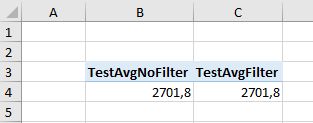
然而:
- 使用
FILTER会对性能产生重大影响,可以清楚地看到查询计划和存储引擎与公式引擎的使用情况。它创建了额外的临时表,它需要与来自报表/枢轴表本身(行、列、切片)的现有过滤器“交互”。在单个单元格中,您不会注意到简单平均值的任何情况,但是如果x度量本身是复杂的,并且存在许多“初始”过滤器,则计算时间上的差异可能很大。 FILTER保留初始过滤器上下文并进行迭代,而直接在CALCULATE中使用的过滤器表达式则忽略它。看看当我将ReadDate添加到pivot表时会发生什么:
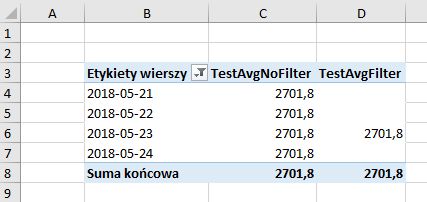
这正是没有FILTER的度量速度更快的原因:它不在乎列中的日期--它已经计算了一个“真”值,而使用FILTER的度量根据每一行的初始筛选器计算自己。
这两列中的结果都可以被认为是正确的--这完全取决于解释和如何命名度量;)。
作为一般规则,我建议您在不必使用FILTER时不要使用它。把它的能量留给真正需要的时候。
Stack Overflow用户
发布于 2018-05-24 08:04:31
这里的不同之处在于,CALCULATE允许简单的过滤器,这将取代现有的过滤器上下文。在您的示例中,CALCULATE将使用现有的筛选器上下文计算度量值[X],但它将删除FactTable[Color]的任何现有筛选上下文并将其替换为FactTable[Color] = Red.。
FILTER函数是一个迭代器,这意味着它一次遍历表(作为其第一个参数传入)一行,并计算每一行的表达式(第二个参数)。当您在FILTER中有一个CALCULATE函数时,它将把现有的过滤器上下文与FILTER的结果结合起来(而不是像简单的filter参数那样替换它)。
通常,只要有选择,就需要使用简单的过滤器,因为计算会更高效。但是,FILTER函数允许您进行更复杂的筛选,因此在简单过滤器不够的情况下,它仍然非常有用。
进一步阅读:过滤器()-什么时候,为什么,以及如何使用它
Stack Overflow用户
发布于 2018-06-05 01:53:55
DAX生成的自动筛选器函数的DAX语法代替逻辑表达式,要求在筛选器表达式中表示单个列。我们来举个例子-
Measure1 = CALCULATE([X], 'FactTable'[Color]="Red")上面的语法是在下面的语法中进行内部转换的,您可以以显式的方式从DAX度量中获得相同的行为。
Measure1 = CALCULATE([X], FILTER(ALL('FactTable'[Color]), 'FactTable'[Color]="Red"))因此,如果在Measure2值中使用最后一个函数,它将获取相同的结果。
https://stackoverflow.com/questions/50506030
复制





相似问题
Ionic Cordova在SplashScreen中缺少插件iOS
为什么Google Maps Cordova ionic angular只在Android上工作,在IOS上是空白的?
构建错误-Ionic Cordova在android上失败
Ionic cordova运行android --prod不工作
SplashScreen在Android Cordova 4.0.2上不起作用
领取专属 10元无门槛券
AI混元助手 在线答疑

洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
