这个Github宝藏仓库竟然收藏了这么多好东西?


Hello,大家好,我是大帅。一个热爱前端的老程序猿。今天要给大家介绍的是Github里一个宝藏仓库,仓库的名字叫 AwesomeSites
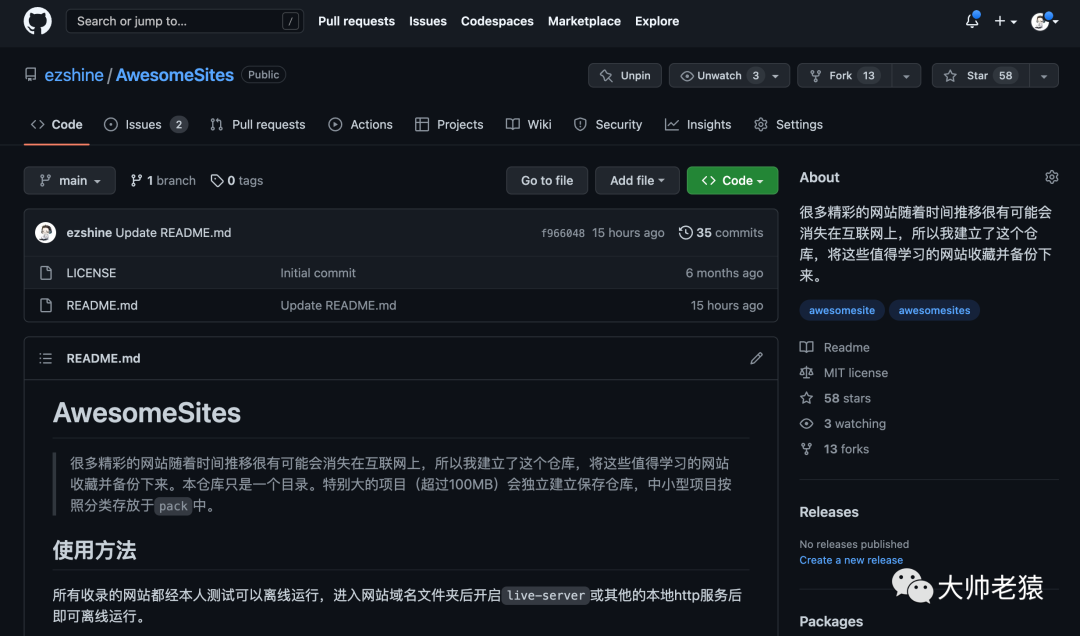
为什么大帅会建这么一个仓库呢?
因为随着时间的流逝,很多网站可能会由于各种原因下线,然后就再也无法访问了,对于一些非常精彩的网站作品而言,这是一个令人遗憾的事情。
所以我建立了这么一个仓库,来备份这些我认为值得体验和学习的网站。
在这个仓库里收录了非常多酷炫,有趣的体验型网站项目。并且都分门别类的归纳好了,分为汽车,电子商务,展览展示,游戏,企业/个人介绍,房间,太空等。


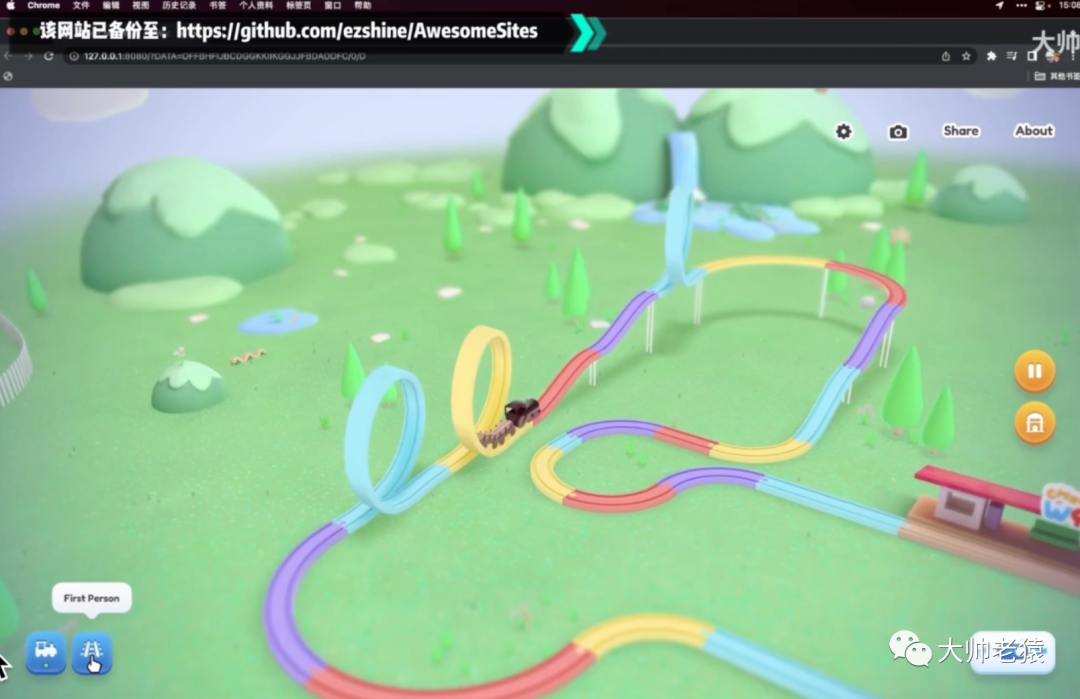
比如在我之前给大家分享过的登月体验网站,积木小火车网站等等,未来这个仓库还会持续更新,喜欢的小伙伴别忘了点个star哦。
现在我来演示一下这个仓库的使用方法。
首先进入打开这个仓库的链接
https://github.com/ezshine/AwesomeSites
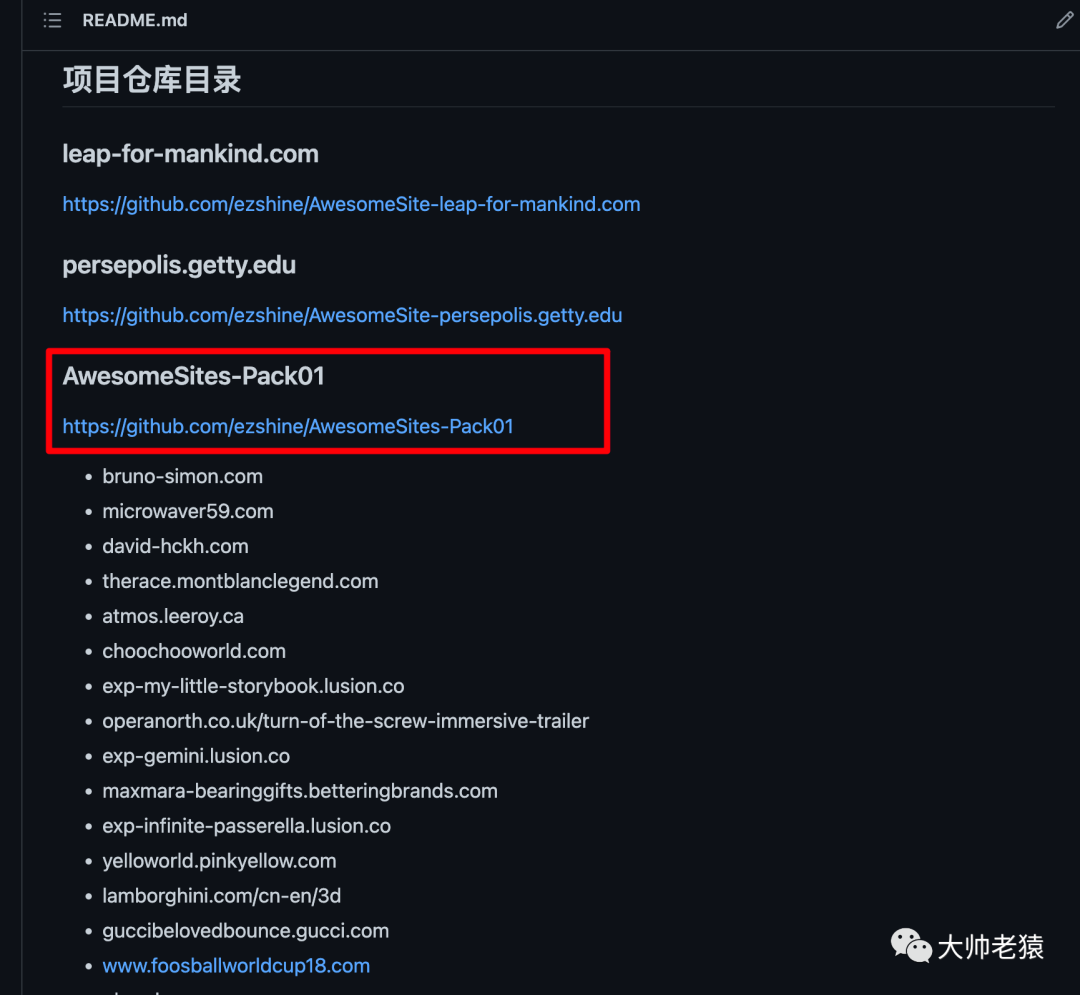
然后选择打开其中一个子仓库,将其克隆下来。
进入到分类下网站文件夹,然后打开终端,记得要安装一下live-server这个本地http服务。接着我们在网站文件夹下启动live-server。
那么这个网站就在本地运行起来了。
虽然这些项目,我备份的不是源码,代码不具备可读性,也就不适合新手学习。
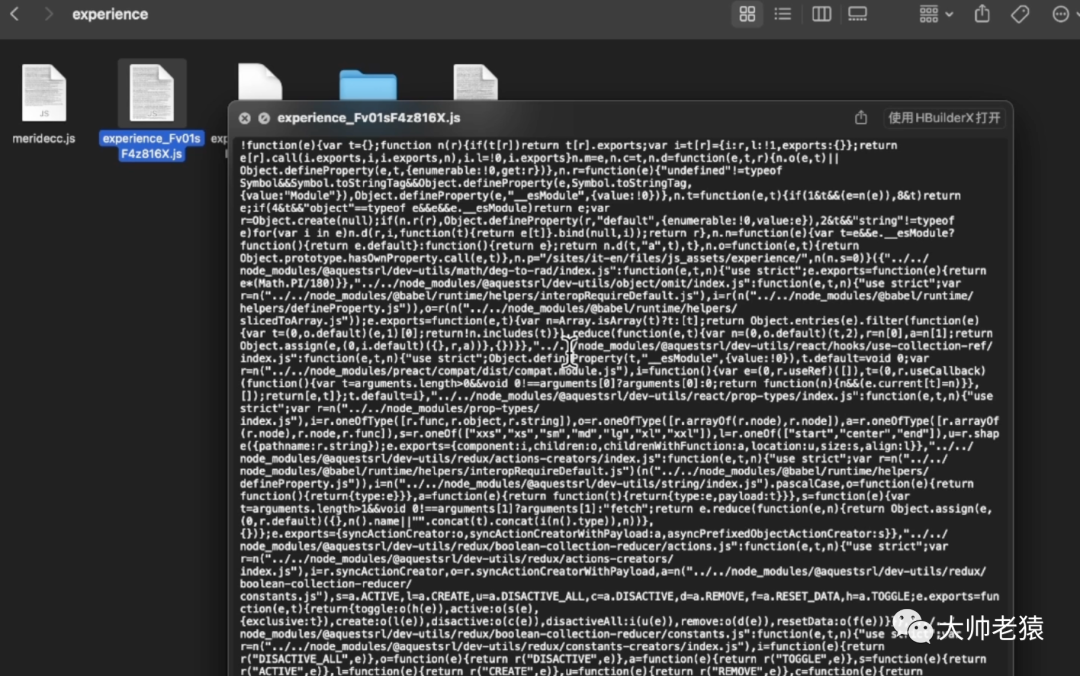
但是像图片,视频,模型等静态资源,我们都可以拿到并且使用。
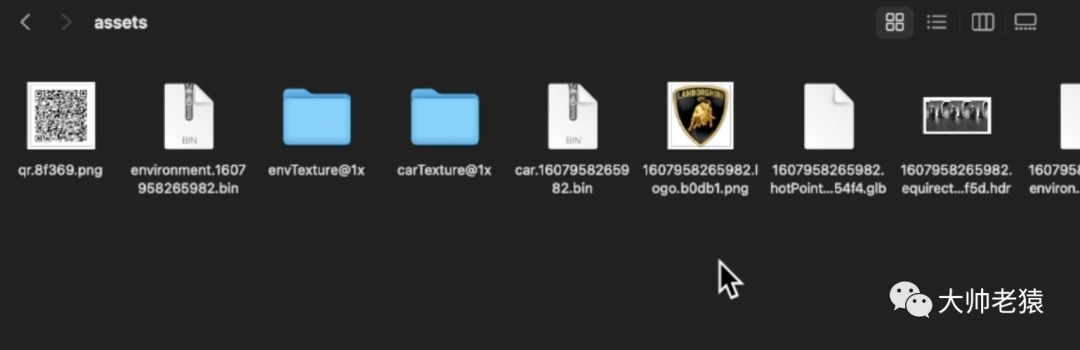
当然,不建议大家使用这些可能存在版权风险的资源去做商业项目,但是做一些课件,毕设,或者是演示demo等非盈利性的内容时,还是没问题的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-11-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号