
如何从PCA分析中提取行样本
如何从PCA分析中提取行样本
提问于 2018-06-04 02:24:09
我正在运行ggbiplot包来对我的数据进行PCA分析。数据被组织为行名作为示例的名称,4列包含数据。
但是有很多行,超过1000行。
在运行ggbiplot时,我得到如下所示的图形,它很好地分隔了我的数据[
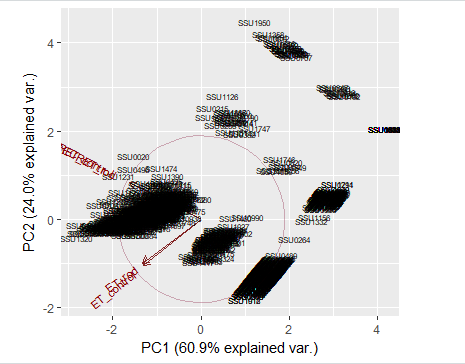
正如您所看到的,示例名称粘在一起,因此不易识别,我想提取包含这9个组的每个示例的行名,以了解分离这些数据的内容。一种方法是使用X和Y轴的确定范围提取数据。
有什么办法可以得到吗?ggbiplot正在处理一个"prcomp“类文件。
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-06-13 21:32:46
PCA帮助显示沿主轴的最大方差方向的数据。因此,检测集群变得更容易(就像在您的双情节中那样)。
但是要标识特定集群的数据点/行,需要运行群集算法。由于您的数据似乎有不重叠的集群,任何聚类算法都应该这样做。但是,由于您已经知道您需要多少个集群,并且对沿着主轴的集群中心有一定的了解,我建议采用运行K-均值算法(k =9作为分析),它将为您提供一个整数向量,指定哪个数据点属于这9个集群中的哪个。
它应该很容易工作,即使你运行一个K-意味着直接对PCA的分数,因为你有初步猜测的中心从上述双图。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/50678396
复制









相似问题
PCA分析
多因素PCA分析提取最大载荷值
如何在PCA实现后提取行名?
命名PCA图中的样本
检查样本空间中是否存在一个样本(来自PCA或其他聚类分析)
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者

