如何在Spyder的DataLoader控制台上使用PyTorch
提问于 2019-09-26 00:31:40
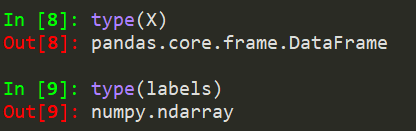
我检查了本教程,却想不出用我的DataLoader训练ANN的方法。当迭代我的DataLoader时,会弹出一个cmd提示符并立即关闭它自己,然后什么都不会发生。我的原始数据都是np.arrays。
import torch
from torch.utils import data
import numpy as np
class Dataset(data.Dataset):
'Characterizes a dataset for PyTorch'
def __init__(self, datax, labels):
'Initialization'
self.labels = torch.tensor(labels)
self.datax = torch.tensor(datax)
self.len = len(datax)
def __len__(self):
'Denotes the total number of samples'
return self.len
def __getitem__(self, index):
'Generates one sample of data'
# Load data and get label
X = self.datax[index]
y = self.labels[index]
return X, y
params = {'batch_size': 64,
'shuffle': True,
'num_workers': 1}
training_set = Dataset(datax=X, labels=labels)
training_generator = data.DataLoader(training_set, **params)
for x in training_generator:
print(1)我试了很多次,看了一眼命令提示符,上面写着
OMP: Info #212: KMP_AFFINITY: decoding x2APIC ids.
OMP: Info #210: KMP_AFFINITY: Affinity capable, using global cpuid leaf 11 info
OMP: Info #154: KMP_AFFINITY: Initial OS proc set respected: 0
OMP: Info #156: KMP_AFFINITY: 4 available OS procs
OMP: Info #157: KMP_AFFINITY: Uniform topology
OMP: Info #179: KMP_AFFINITY: 1 packages x 2 cores/pkg x 2 threads/core (2 total cores)
OMP: Info #214: KMP_AFFINITY: OS proc to physical thread map:
OMP: Info #171: KMP_AFFINITY: OS proc 0 maps to package 0 core 0 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 1 maps to package 0 core 0 thread 1
OMP: Info #171: KMP_AFFINITY: OS proc 2 maps to package 0 core 1 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 3 maps to package 0 core 1 thread 1
OMP: Info #250: KMP_AFFINITY: pid 10264 tid 2388 thread 0 bound to OS proc set 0
OMP: Info #250: KMP_AFFINITY: pid 10264 tid 3288 thread 1 bound to OS proc set 2
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-09-26 00:38:08
我就是这样做的:
class myDataset(Dataset):
'''
a dataset for PyTorch
'''
def __init__(self, X, y):
self.X = X
self.y = y
def __getitem__(self, index):
return self.X[index], self.y[index]
def __len__(self):
return len(self.X)然后,您可以简单地添加到加载程序中:
full_dataset = myDataset(X,y)
train_loader = DataLoader(full_dataset, batch_size=batch_size)而且,X,y只是numpy数组。
对于培训,您可以使用for循环访问数据:
for data, target in train_loader:
if train_on_gpu:
data, target = data.double().cuda(), target.double().cuda()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58112658
复制






腾讯云开发者
