VS2019自带的增强型指令集和自我优化的版本速度比较.

VS2019自带的增强型指令集和自我优化的版本速度比较.

用户1138785
发布于 2024-02-28 08:09:29
发布于 2024-02-28 08:09:29
去年年底把工程项目由VS的2015升级到2019版本,本以为直接配置下运行环境就可以了,但是一编译发现一大堆错误,所有的错误都指向一系列的指令集,比如_mm_exp_ps、_mm_log_ps、_mm_pow_ps等等,后面发现原来从2019版本开始,编译器已经自带了这些常用的函数,所以自己函数和系统的重名了,也就无法通过编译了。
这个时候只能把自己大函数名都适当的进行修改,再重新编译了.
我们在intel的关于指令集方面的官方网站也发现了一些信息: 比如_mm_exp_ps,其说明如下:
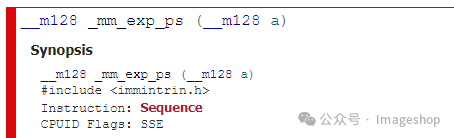
注意其中的Sequence说明这是由一些其他的指令组合而成的。
既然系统也提供了这类函数,那么他们的效率和精度和我们自己写的相比又有多大的差异和不同呢,一直想做个比较,今天就抽点时间做点测试.
我们先看看精度,以exp为代表,测试代码如下:
__m128 s = _mm_setr_ps(0, 3, 4, 6);
__m128 d1 = _mm_exp_ps(s);
__m128 d2 = _mm_fexp_ps(s);
for (int i = 0; i < 4; i++)
{
printf("%f %f %f \n", d1.m128_f32[i], d2.m128_f32[i], exp(s.m128_f32[i]));
}运行结果如下所示:
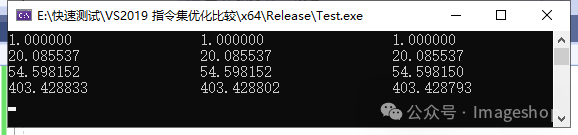
其中的_mm_fexp_ps的代码来自于github上的sse_mathfun文件里。
可见大家的精度上差不多,在某些情况下和标准的数学结果都有差异。 同样测试了sin,cos,log,pow等函数,精度也都差不多,说明大家的计算方法差异不大。
下面再测试下速度,测试代码如下所示:
LARGE_INTEGER nEndTime, nBeginTime, nFreq;
double time;
QueryPerformanceFrequency(&nFreq);
int Length = 100000;
float* Src = (float*)malloc(Length * sizeof(float));
float* Dest = (float*)malloc(Length * sizeof(float));
QueryPerformanceCounter(&nBeginTime);//获取开始时刻计数值
for (int Y = 0; Y < 10000; Y++)
{
for (int X = 0; X < Length; X += 4)
{
__m128 SrcV = _mm_loadu_ps(Src + X);
__m128 DstV = _mm_exp_ps(SrcV);
_mm_storeu_ps(Dest + X, DstV);
}
}
QueryPerformanceCounter(&nEndTime);//获取停止时刻计数值
time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) * 1000 / (double)nFreq.QuadPart;//(开始-停止)/频率即为秒数,精确到小数点后6位
printf("%f \n", time);
QueryPerformanceCounter(&nBeginTime);//获取开始时刻计数值
for (int Y = 0; Y < 10000; Y++)
{
for (int X = 0; X < Length; X += 4)
{
__m128 SrcV = _mm_loadu_ps(Src + X);
__m128 DstV = _mm_fexp_ps(SrcV);
_mm_storeu_ps(Dest + X, DstV);
}
}
QueryPerformanceCounter(&nEndTime);//获取停止时刻计数值
time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) * 1000 / (double)nFreq.QuadPart;//(开始-停止)/频率即为秒数,精确到小数点后6位
printf("%f \n", time);
free(Src);
free(Dest);不同的函数,测试耗时比较如下表:

综合比较起来,似乎自定义的函数含有较大的优势,所以可以自行取舍了。
另外,还注意到,在标准的SSE指令集里,没有针对整数的除法指令,而在VS2019自带的指令里,已经有了这些函数,当然他们也不是原生的指令,而是多个指令组合的。我们测试了其中的一个函数_mm_div_epi32,发现这个的速度并不理想,比自己写的要差一个档次,而且他对除零还是直接报错误,所以这个方面的东西还是自己弄比较好,比如我们自定的四个32位整数除法如下代码:
// 四个浮点数的除法a/b,如果b中某个分量为0,则对应位置返回0值
inline __m128 _mm_divz_ps(__m128 a, __m128 b)
{
//return _mm_blendv_ps(_mm_div_ps(a, b), _mm_setzero_ps(), _mm_cmpeq_ps(b, _mm_setzero_ps()));
return _mm_and_ps(_mm_div_ps(a, b), _mm_cmpneq_ps(b, _mm_setzero_ps()));
}
// 四个32位整数的除法,当某个除数为0时,返回0
inline __m128i _mm_divz_epi32(__m128i A, __m128i B)
{
return _mm_cvtps_epi32(_mm_divz_ps(_mm_cvtepi32_ps(A), _mm_cvtepi32_ps(B)));
}即使在除数确当不为0的情况下,系统自带的_mm_div_epi32函数也要比_mm_divz_epi32慢2倍以上,所以目前也不清楚这个是为什么。 当然,VS2019及其以上版本确实提供了很多原来没有指令集函数,如果想快速的实现某些功能,这些确实是一大利器。但是知道他们各自的特性对于做特定条件下的优化还是很有意义的。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-02-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号