[快速阅读六] 统计内存数据中二进制1的个数(SSE指令集优化版).

[快速阅读六] 统计内存数据中二进制1的个数(SSE指令集优化版).

用户1138785
发布于 2024-05-31 12:36:35
发布于 2024-05-31 12:36:35
关于这个问题,网络上讨论的很多,可以找到大量的资料,我觉得就就是下面这一篇讲的最好,也非常的全面:
统计无符号整数二进制中 1 的个数(Hamming Weight)
在指令集不参与的情况下,分治法速度最快,MIT HAKMEM 169 算法因为最后有一个mod取余操作,速度要稍微慢一点,256元素的查表算法速度要次之,当然,其实要建议那个256元素的表不要使用int类型,而是使用unsigned char类型的,尽量减少表的内存占用量,也意味着cache miss小一些。 16位的查表算法速度反而慢了不少,主要是因为他用while,即使我们把他展开,也需要8次数据组合,还是比16位的慢。其他的就不要说了,都比较慢。
在SSE4指令集能得到CPU的支持时,可以有一个直接的指令_mm_popcnt_u32可以使用,这个就可以加速很多了,一个常用的过程如下:
Amount = 0;
for (int Y = 0; Y < Length; Y++)
{
Amount += _mm_popcnt_u32(Array[Y]);
}
一千万的随机数据,用这个指令大概只要3.2毫秒多就可以处理完成,如果稍微改下代码,让他能并行化一点,如下所示:
Amount = 0;
for (int Y = 0; Y < Length; Y+=4)
{
int T0 = _mm_popcnt_u32(Array[Y + 0]);
int T1 = _mm_popcnt_u32(Array[Y + 1]);
int T2 = _mm_popcnt_u32(Array[Y + 2]);
int T3 = _mm_popcnt_u32(Array[Y + 3]);
Amount += T0 + T1 + T2 + T3;
}还可以提高到大约2.7ms就可以处理完。
其实,现在在运行的新的CPU基本上没有那个不支持SSE4的了,但是也不排除还有一些老爷机。因为SSE4最早是2008年发布的,如果CPU不支持SSE4,但是支持SSE3(2004年发布的),那是否有合适的指令集能加速这个过程呢,实际上也是有的。
我们这里喵上了统计无符号整数二进制中 1 的个数(Hamming Weight)一文中的16元素查表算法,原文中的代码为:
Amount = 0;
for (int Y = 0; Y < Length; Y++)
{
unsigned int Value = Array[Y];
while (Value)
{
Amount += Table16[Value & 0xf];
Value >>= 4;
}
}这个明显是不合适指令处理的,前面说了,这个可以展开,展开后形式如下:
Amount = 0;
for (int Y = 0; Y < Length; Y++)
{
unsigned int Value = Array[Y];
Amount += Table16[Value & 0xf] + Table16[(Value >> 4) & 0xf] + Table16[(Value >> 8) & 0xf] + Table16[(Value >> 12) & 0xf] +
Table16[(Value >> 16) & 0xf] + Table16[(Value >> 20) & 0xf] + Table16[(Value >> 24) & 0xf] + Table16[(Value >> 28) & 0xf];
}仔细观察他的意思就是提取内存的4位,然后根据4位的值来查16个元素的表,我在之前的多个文章里都有提高,16个元素的表(表内的值不能超过255)是可以借用一个_mm_shuffle_epi8指令进行优化的,一次性得到16个值。
_mm_shuffle_epi8是在SSE3就开始支持的,因此,这一改动可以将硬件的适应性提前4年。
具体的来首,就是我们加载16个字节数据,然后和0xF进行and操作,得到每个字节的低4位,然后进行shuffle,得到每个字节低4位的二进制中1的个数,然后在把原始字节数右移4位,再和0xF进行and操作,得到每个字节的高4位,然后进行shuffle,两次shuffle的结果相加,就得到了这16个字节数据的二进制中1的个数。 具体代码如下所示:
__m128i Table = _mm_loadu_si128((__m128i*)Table16);
__m128i Mask = _mm_set1_epi8(0xf);
__m128i UsedV = _mm_setzero_si128();
for (int Y = 0; Y < Length; Y += 4)
{
__m128i Src = _mm_loadu_si128((__m128i*)(Array + Y));
__m128i SrcL = _mm_and_si128(Src, Mask);
__m128i SrcH = _mm_and_si128(_mm_srli_epi16(Src, 4), Mask);
__m128i ValidL = _mm_shuffle_epi8(Table, SrcL);
__m128i ValidH = _mm_shuffle_epi8(Table, SrcH);
UsedV = _mm_add_epi32(UsedV, _mm_add_epi32(_mm_sad_epu8(ValidL, _mm_setzero_si128()), _mm_sad_epu8(ValidH, _mm_setzero_si128())));
}
// 提取出前面的使用SSE指令计算出的总的有效点数
Amount = _mm_cvtsi128_si32(_mm_add_epi32(UsedV, _mm_unpackhi_epi64(UsedV, UsedV)));注意到这里的函数除了_mm_shuffle_epi8,其他的都是SSE2就已经能支持的了,其中_mm_sad_epu8可以快速的把16字节结果相加。
使用这个代码,测试上述1千万数据,大概只需要2.1ms就能处理完,比优化后的_mm_popcnt_u32还要快。
实际上,我还遇到一种情况,一个AMD的早期CPU,用CPUID看他支持的指令集,他是支持SSE4.2的,也支持SSE3,但是执行_mm_shuffle_epi8确提示不识别的指令,也是很奇怪,或者说如果遇到一个机器不支持SSE3,只支持SSE2,那是否还能用指令集优化这个算法呢(SSE2是2001年发布的)。
其实也是可以的,我们观察上面的不使用指令集的版本的,特别是分冶法的代码:
Amount = 0;
for (int Y = 0; Y < Length; Y++)
{
unsigned int Value = Array[Y];
Value = (Value & 0x55555555) + ((Value >> 1) & 0x55555555);
Value = (Value & 0x33333333) + ((Value >> 2) & 0x33333333);
Value = (Value & 0x0f0f0f0f) + ((Value >> 4) & 0x0f0f0f0f);
Value = (Value & 0x00ff00ff) + ((Value >> 8) & 0x00ff00ff);
Value = (Value & 0x0000ffff) + ((Value >> 16) & 0x0000ffff);
Amount += Value;
}这里就是简单的一些位运算和移位,他们对应的指令集在SSE2里都能得到支持的,而且这个改为指令集也是水到渠成的事情:
UsedV = _mm_setzero_si128();
for (int Y = 0; Y < Length; Y += 4)
{
__m128i Value = _mm_loadu_si128((__m128i*)(Array + Y));
Value = _mm_add_epi32(_mm_and_si128(Value, _mm_set1_epi32(0x55555555)), _mm_and_si128(_mm_srli_epi32(Value, 1), _mm_set1_epi32(0x55555555)));
Value = _mm_add_epi32(_mm_and_si128(Value, _mm_set1_epi32(0x33333333)), _mm_and_si128(_mm_srli_epi32(Value, 2), _mm_set1_epi32(0x33333333)));
Value = _mm_add_epi32(_mm_and_si128(Value, _mm_set1_epi32(0x0f0f0f0f)), _mm_and_si128(_mm_srli_epi32(Value, 4), _mm_set1_epi32(0x0f0f0f0f)));
Value = _mm_add_epi32(_mm_and_si128(Value, _mm_set1_epi32(0x00ff00ff)), _mm_and_si128(_mm_srli_epi32(Value, 8), _mm_set1_epi32(0x00ff00ff)));
Value = _mm_add_epi32(_mm_and_si128(Value, _mm_set1_epi32(0x0000ffff)), _mm_and_si128(_mm_srli_epi32(Value, 16), _mm_set1_epi32(0x0000ffff)));
UsedV = _mm_add_epi32(UsedV, Value);
}
// 提取出前面的使用SSE指令计算出的总的有效点数
//Amount = _mm_cvtsi128_si32(_mm_add_epi32(UsedV, _mm_unpackhi_epi64(UsedV, UsedV)));
Amount = UsedV.m128i_u32[0] + UsedV.m128i_u32[1] + UsedV.m128i_u32[2] + UsedV.m128i_u32[3];这里唯一要注意的就是最后从UsedV 变量得到Amount的过程不能用之前shuffle那一套代码了,因为这里的UsedV的最高位里含有了符号位,所以要换成下面哪一种搞法。
我们注意到,编译运行这个代码后,我们得到的耗时大概是5.2ms,但是同样的数据,前面的分冶法对应的C代码也差不多是5.5ms左右,速度感觉毫无提高,这是怎么回事呢,我们尝试反汇编C的代码,结果发现如下片段:
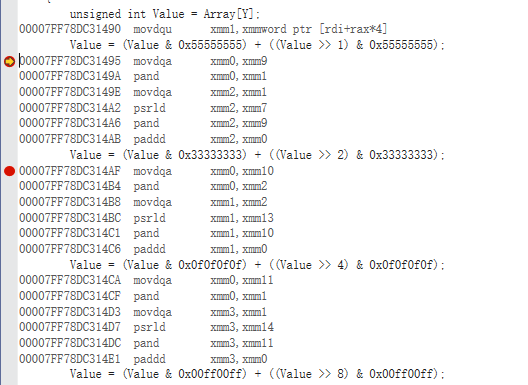
注意到pand psrld paddd等指令没有,那些就对应了_mm_and_si128 _mm_srli_epi32 _mm_add_epi32等等,原来是编译器已经帮我们向量化了,而且即使在设置里设置 无增强指令 (/arch:IA32) 选项,编译器也会进行向量化(VS2019)。

所以我暂时还得不到这个和纯C比的真正的加速比。
但是,在编译器没有这个向量化能力时,直接手工嵌入SSE2的指令,还是能有明显的加速作用的,不过也可以看到,SSE2的优化速度还是比SSE3的shuffle版本慢一倍的,而sse3的shuffle确可以比SSE4的popcount快30%。
以前我一直在想,这个算法有什么实际的应用呢,有什么地方我会用到统计二进制中1的个数呢,最近确实遇到过了一次。
具体的应用是,我有一堆数据,我要统计出数据中符合某个条件(有可能是多个条件)的目标有多少个,这个时候我们多次应用了_mm_cmpxx_ps等函数组合,最后得到一个Mask,这个时候我们使用_mm_movemask_ps来得到一个标记,我们看看_mm_movemask_ps 这个函数的具体意思:
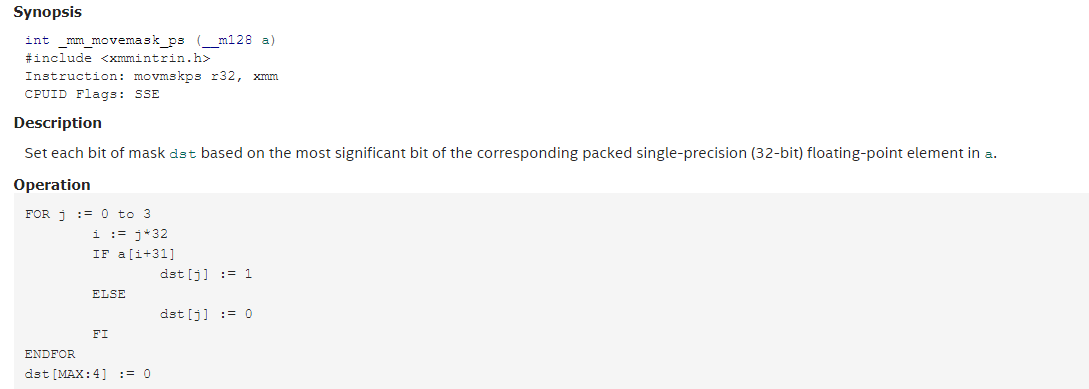
他返回的是一个0到15之间的整形数据,很明显我们可以把他保存到一个unsigned char类型的变量里,这样,在计算完一堆数据后,我们就得到了一个mask数组,这个时候我们统计下数组里有多少个二进制1就可以得到符合条件的目标数量了。 当然,这里和前面的还不太一样,这个usnigned char变量的高4位一直为0,还可以不用处理的,还能进一步加速。
当然,如果系统支持AVX2,那还可以进一步做速度优化。这个就不多言了。
最后,列一下各个算法的耗时比较数据吧:
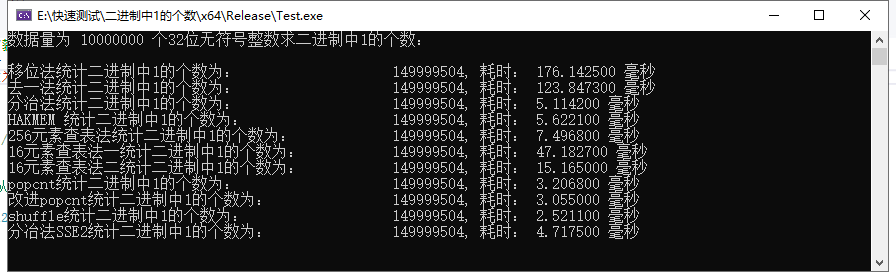
相关测试代码地址: 数据流二进制中1的个数统计
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-05-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号