玄武(Xuanwu)给 白泽(Byzer) 插上云原生的翅膀

玄武(Xuanwu)给 白泽(Byzer) 插上云原生的翅膀

用户2936994
发布于 2023-03-01 17:01:05
发布于 2023-03-01 17:01:05
前言
之前我开发 Byzer-helm 的项目就觉得,要是 Kubernetes 上也有个类似 CDH 的管理工具就好了, 我可以通过界面的方式安装大数据/AI 类的应用。现在,这个产品有了,就是云原生数据底座玄武里的 Xuanwu Manager 。该工具未来会内置主流的大数据应用,用户也可以根据 Xuanwu Manager 的标准发布自己的应用。这样上面的租户/用户就可以一键启动已经发布的大数据应用了。
项目地址: GitHub - kyligence-xuanwu/document
接下来我们以 Byzer 为例,看看 Xuanwu 如何给 Byzer 插上云原生的翅膀。
玄武如何解决大数据在 Kubernetes 上的挑战
大数据体系的应用大部分都是分布式的,而且几乎必须支持的,然而分布式应用在 Kubernetes 上运行其实也面临挺多的问题。我们掰着手指一个一个来说说。
资源Gap计算
Kubernetes 因为良好的资源隔离能力,可以让分布式应用的运行性能更加稳定,加上 Remote Shuffle Service 加持,性能可以比在 Hadoop 里好个 20%,当然了,整体IT资源利用率也能得到 20% - 50% 的提升。不过这里面其实有个小细节,就是很多大数据应用都是基于 Java 开发的,声明的 JVM 内存(-Xmx)和实际容器限制的内存会有个Gap, 因为 JVM 以及应用都可能会用一些非堆内存,所以很容易被突然Killed掉。 Byzer 集成到玄武之后,其实就考虑了这个问题,默认给了一个较大的 Overhead, 通过玄武方便的模板能力,用户也可以在启动的时候按 instance 进行调整。
比如这里作为一个普通用户,我可以选择一个已经运行的应用,选择侧边的编辑按钮:
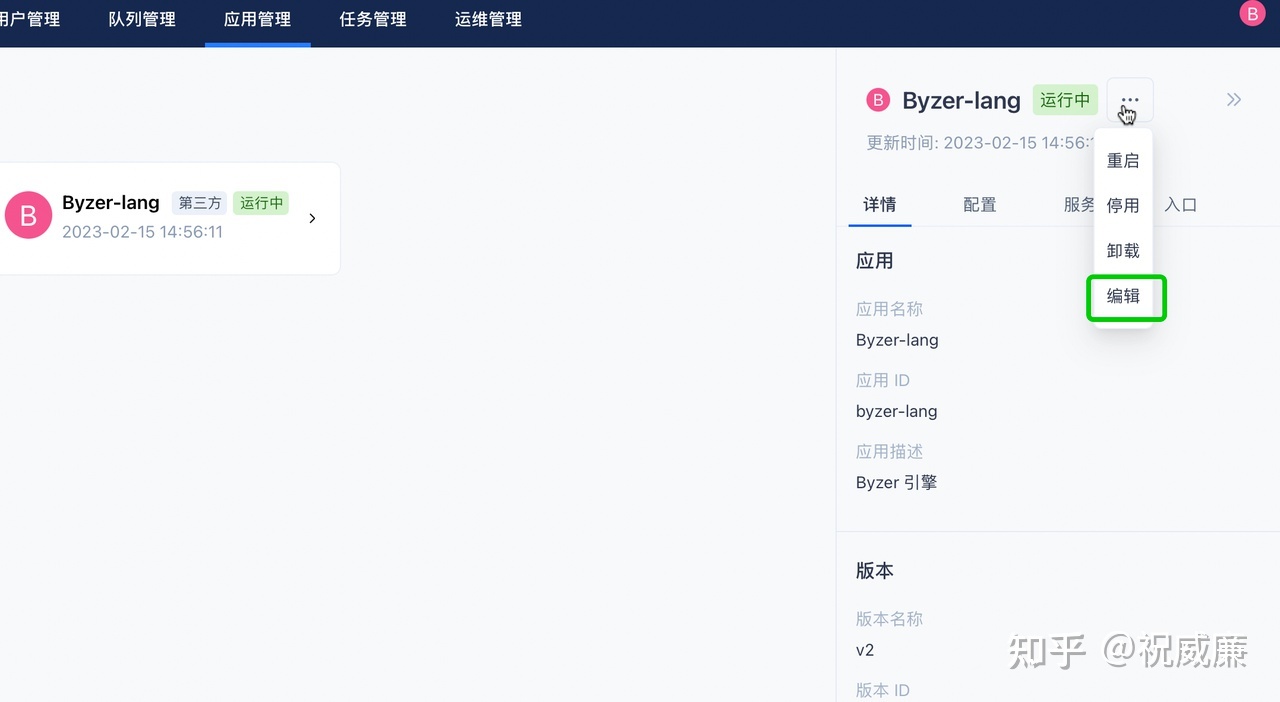
然后进行编辑,默认 Overhead 都设置为 0.4, 你根据实际需求修改:
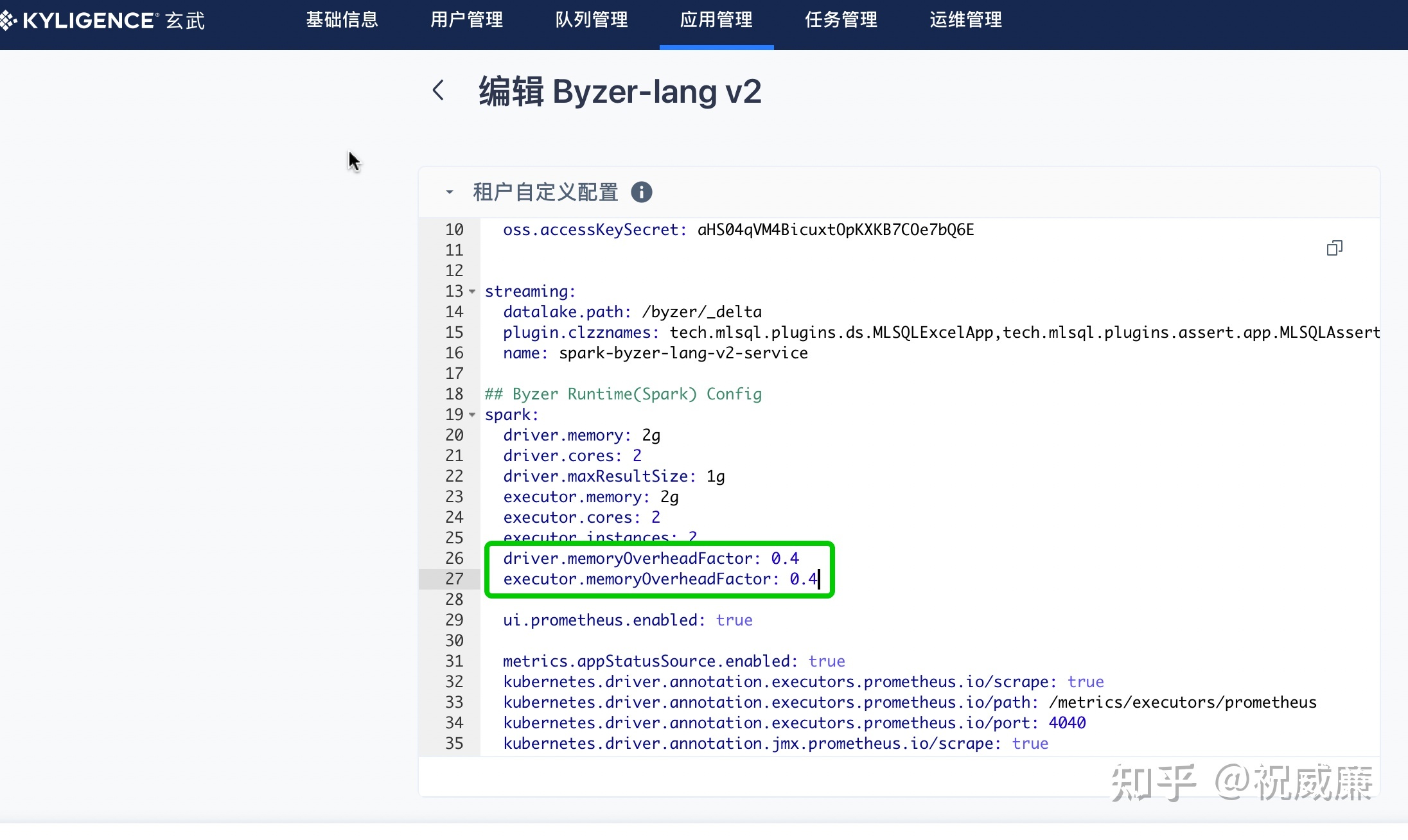
保存后点击重启即可生效。该配置仅影响该租户下的应用。
Remote Shuffle Service 支持
以 Byzer 为例(基于Spark的应用),分布式计算最大的IO瓶颈其实是 Shuffle,如果不使用 Remote Shuffle Service, 那么会使用 Kubernetes 本地盘,但是直接使用Kubernetes 本地盘,不经过一些特殊的配置,无论存储大小,还是性能可能都是不匹配的,第二是如果在云上,还会因为IO太高导致应用被杀死。在 Xuanwu Manager 中,你可以在发布平台应用的时候直接配置 Remote Shuffle Service 地址,实现所有租户都默认支持 RSS。
当然,如果平台应用发布的时候默认不使用RSS, 你也可以在租户层面使用玄武生成的配置添加到自己的应用的启动参数里:
spark:
rss.master.address: 10.1.2.146:9097
serializer: org.apache.spark.serializer.KryoSerializer
rss.shuffle.writer.mode: hash
rss.push.data.replicate: true
shuffle.service.enabled: false
sql.adaptive.localShuffleReader.enabled: false
sql.adaptive.enabled: true
sql.adaptive.skewJoin.enabled: true这样就让 Byzer 集成了RSS 的能力。
监控/日志查看能力
Byzer-lang 运行起来其实仅仅是万里长征第一步。最重要的是,我们需要能够监控和查看 Byzer 的日志,指标等信息。 在 Xuanwu Manager 中,一旦某个租户把 Byzer-lang(各类Spark应用都是一样的) 运行起来后,你就可以在 任务管理 中看到对应的 Spark UI, 日志,指标监控。
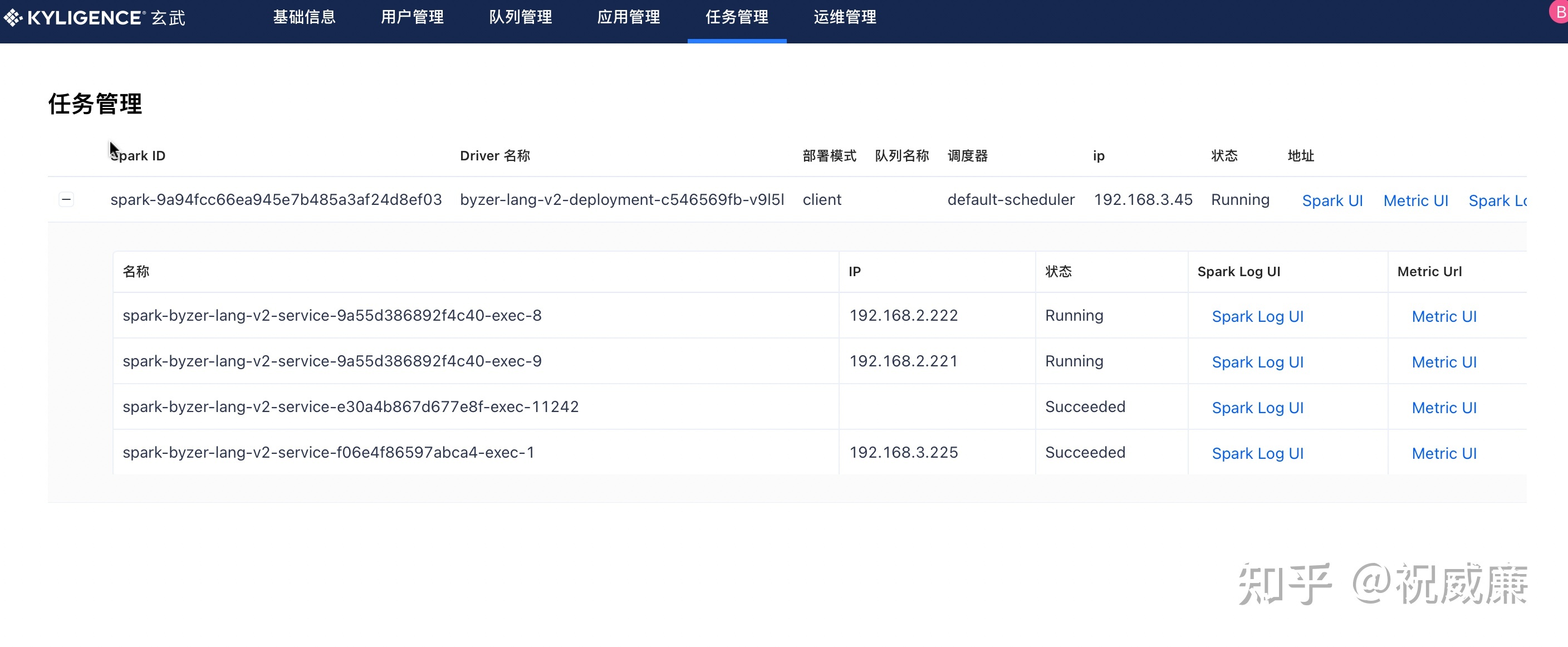
通过这个页面你可以查看应用的大部分信息,帮助你排查和监控应用。比如Spark UI, Pod 信息,Log信息, Promethus信息等。传统如果用户自己搭建会其实是蛮有工作量的一件事情。
调度能力
我们知道 Kubernetes 其实主要是面向服务化应用。而传统大数据体系里,尽管现在也在越来越多的转型成服务,但依然有非常多的任务型的作业。这对 Kubernetes 的应用调度能力有较大的挑战,在吞吐,调度速度等方面都存在制约,此外,传统大数据还有租户的概念,方便按部门,组织进行资源的切分,而Kubernetes 原生的调度的控制是针对应用的,所以这里其实有蛮多不match的地方。 玄武为此开发了单独的调度器去满足这些大数据体系相关的需求,配合原生的 Kubernetes,真正能够覆盖Web服务和大数据作业的需求。
比如在玄武中可以看到资源池和租户概念:
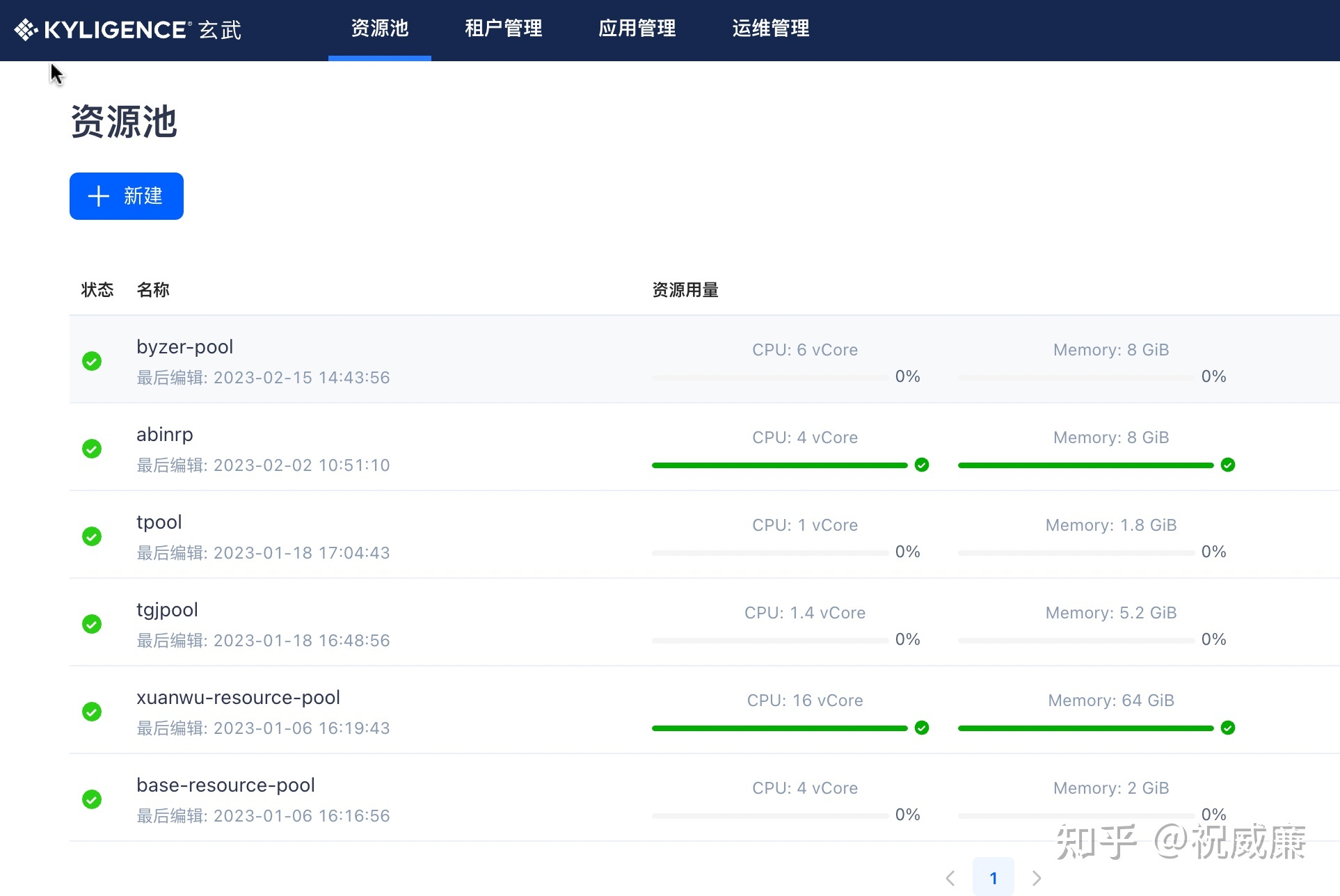
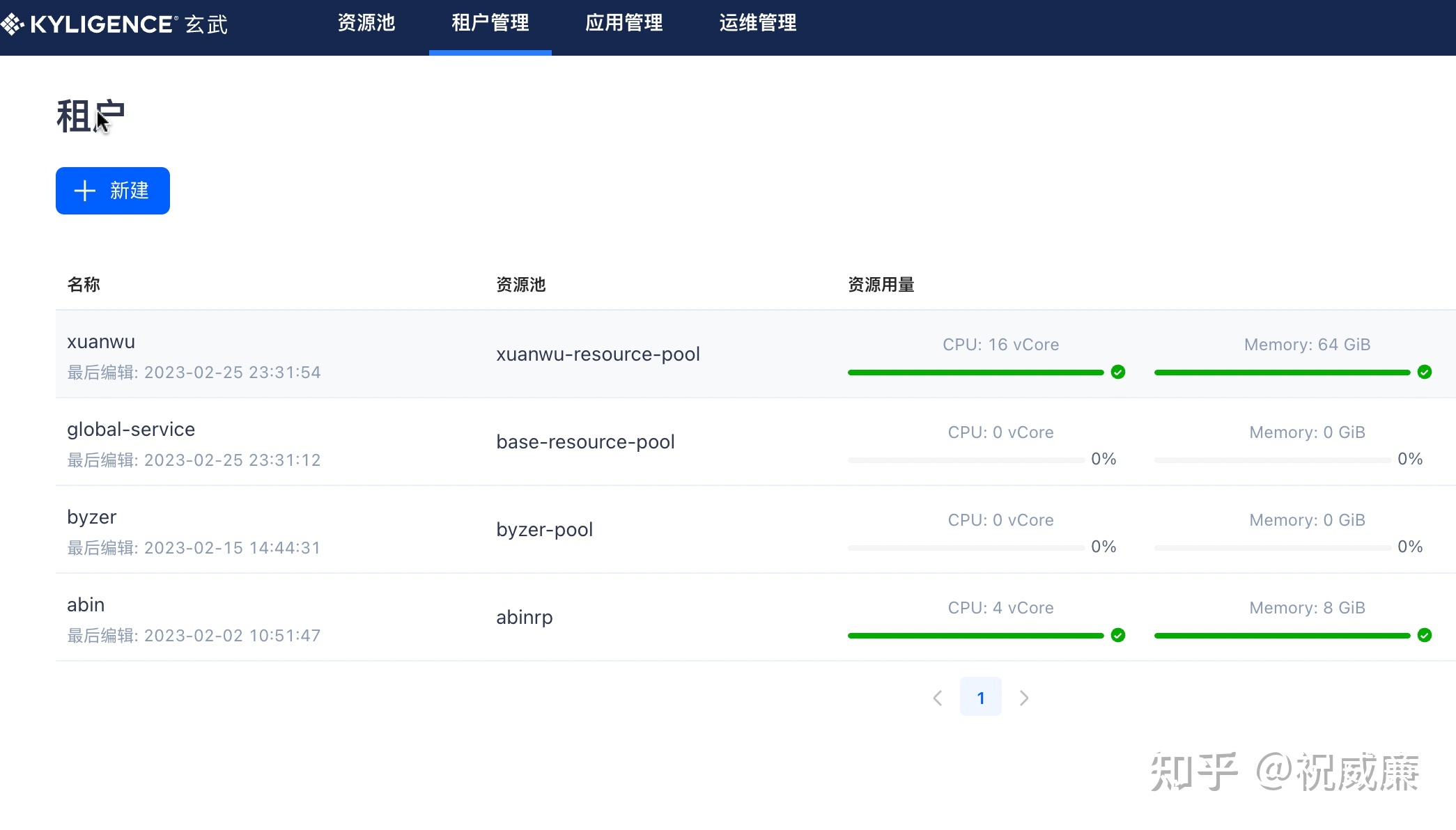
价值
用户安装完 Xuanwu Manager,就相当于有个 大数据应用的 App Store。 可以很轻松组件起一个服务于用户场景的大数据应用 Pipeline。 比如通过三次点击分别安装Apache Kylin, Byzer-lang, Byzer Notebook 用户其实就已经可以打开 Web 就开始 ETL/AI, 数据分析和BI相关的工作了,极致的简单高效。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-02-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号