【教程】制作 iOS 推送证书
原创

【教程】制作 iOS 推送证书
如需向 iOS 设备推送数据,您首先需要在消息推送控制台上配置 iOS 推送证书。iOS 推送证书用于推送通知,本文将介绍消息推送服务支持的证书类型,并引导您制作 iOS 推送证书。
证书类型
消息推送服务仅支持 Apple Push Service 类型的证书。有关苹果证书类型及相关介绍,请参见 苹果证书类型。
Apple Push Service 易和 iOS Development 类型的证书混淆。使用 iOS Development 证书会导致消息推送大量失败。下面将介绍如何通过 MAC Key Store 和消息推送控制台区分这两类证书。

MAC Key Store
双击已有的 .p12 证书,将证书导入 MAC 钥匙串中,您将看到证书名称等信息:

其中:
- iPhone Developer:苹果开发证书。消息推送不支持。
- Apple Push Service:生产环境苹果推送证书。消息推送支持。
- Apple Development IOS Push Services:开发环境苹果推送证书。消息推送支持。
消息推送控制台
在消息推送控制台导入证书后,您将看到以下证书信息:
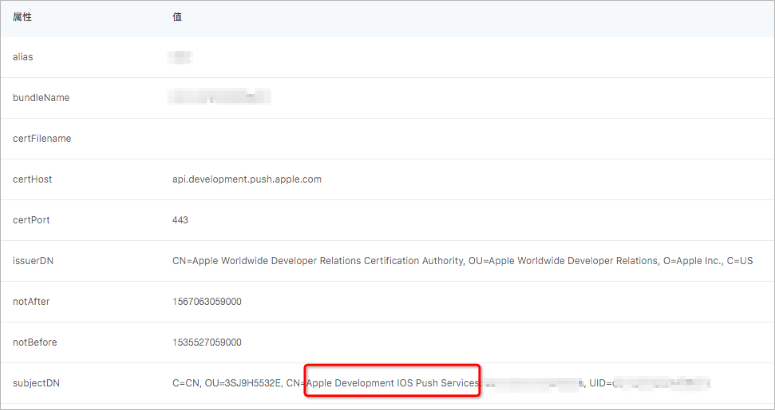
如上图所示,subjectDN 属性:
- Apple Development IOS Push Services:开发环境苹果推送证书。消息推送支持。
- Apple Push Service:生产环境苹果推送证书。消息推送支持。

如上图所示,subjectDN 属性 iPhone Developer 表明是苹果开发证书,消息推送不支持。
制作证书
创建苹果 App ID
- 在苹果开发平台,单击左侧导航栏 App IDs,然后单击右上角 + 按钮。
- 填写基础信息。 App ID Description > Name App ID Suffix > Bundle ID: Bundle ID 需要具备唯一性。
- 勾选 Push Notifications 能力。
- 单击 Continue 后,单击 Register 完成创建。
使用appuploder制作 .p12文件
- 进入 appuploader中的证书制作模块。
- 创建证书。选择 新建> 证书填写 。。。。
- 在打开的 证书信息 窗口中,根据实际情况填写邮件地址和常用名称等相关信息。
.p12文件制作成功。
创建证书
- 在苹果 App IDs 页面中,选中自己的 iOS App ID,单击 Edit。
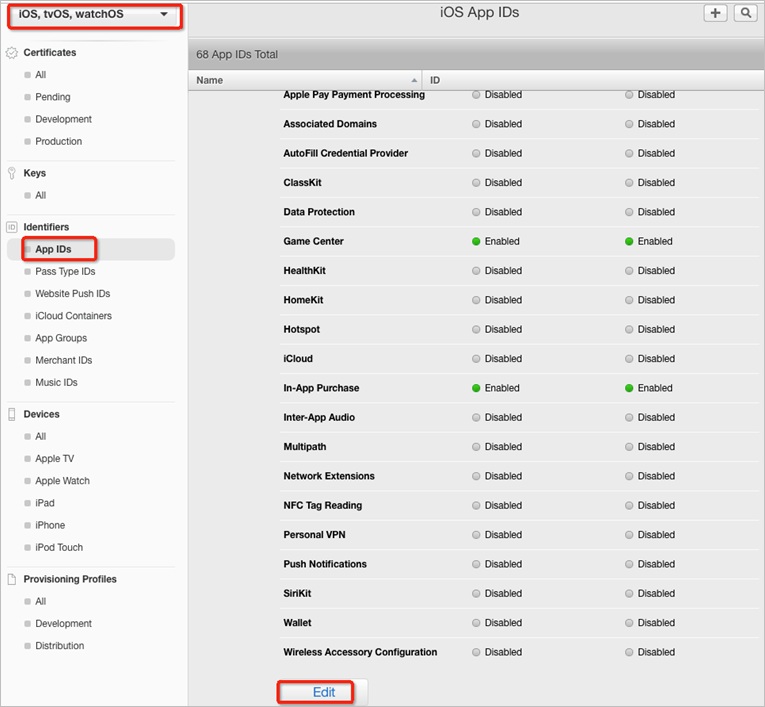
- 单击 Development SSL Certificate 或 Production SSL Certificate 卡片中的 Create Certificate,开始创建开发或生产环境下的证书。
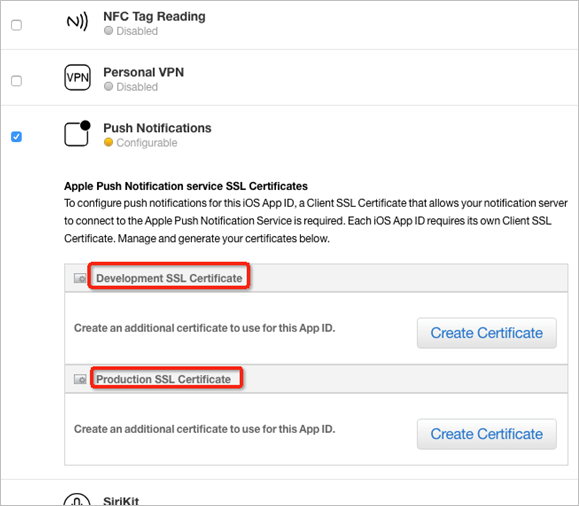
- 在创建证书时,可以使用appuploder制作证书,创建即可得到.p12证书,无需.cer转换.p12
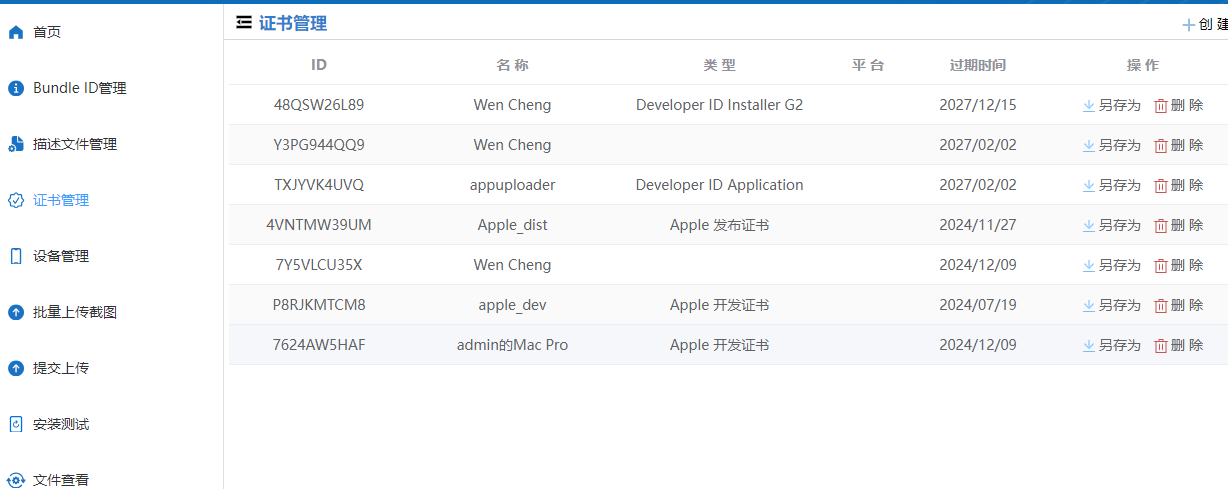
- 证书创建成功后,您将看到以下页面。单击 另存为,您将得到
.p12文件。 - 找到刚刚导入的证书,右键单击,选择 导出 功能。导出成功后您将获得
.p12证书。 - 至此您已获得了
.p12证书,可以前往消息推送控制台的 设置 > 渠道配置 页面配置 iOS 推送证书。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号