一文弄懂GBDT原理和应用


GBDT是一种集成学习算法,属于Boosting类型,通过叠加多个决策树的预测结果得出最终的预测结果。
这个算法是很多算法的基石,比如生产中常用的XGBoost算法和LightGBM算法。
GBDT算法的原理和实现比较简单,本文接下来将进行详细阐述。
一、名词解释
集成学习:通过构建并结合多个机器学习模型来改善模型的性能。通过训练多个模型,并将它们的预测结果进行某种方式的结合,通常可以得到比单一模型更好的预测结果。
Bagging:是Bootstrap Aggregating的缩写,是一种通过结合多个模型的预测结果来减少模型方差的方法。在Bagging中,每个模型都是在原始数据集的随机子集上进行训练的,这些随机子集是通过有放回的抽样得到的。然后,所有模型的预测结果通过投票(对于分类问题)或平均(对于回归问题)的方式进行结合,典型的代表是随机森林。
Boosting:基本思想是三个臭皮匠赛过诸葛亮。算法思路是采用串行的方式训练基分类器,每一层在训练时,给前一层基分类器分错的样本更高的权重,最后把各层分类器的结果层层加权叠加得到最终的结果。
GBDT:是Gradient Boosting Decision Tree的缩写,是一种基于决策树的集成学习算法,也是一种迭代式的boosting算法。基本原理是迭代地训练决策树,每次训练都基于之前训练结果来进行优化。训练过程基于梯度下降的思想,使用了加法模型和函数优化方法。
二、GBDT算法原理详解
GBDT无论用于分类还是回归,基学习器使用的都是CART回归树。
对决策树原理和使用不太了解,可以看下本公众号之前的文章:决策树-ID3算法和C4.5算法、CART决策树原理(分类树与回归树)、Python中调用sklearn决策树、Python中应用决策树算法预测客户等级。
GBDT使用回归树的核心原因是每轮的训练是在上一轮训练模型的负梯度值基础之上训练的。这就要求每轮迭代的时候,真实标签减去弱分类器的输出结果是有意义的,即残差是有意义的。如果选用的弱分类器是分类树,类别相减是没有意义的。
1 GBDT算法原理理解简单案例
为了大家能直观地感受GBDT的算法流程,先看一个简单的例子。
我们应用GBDT算法预测客户的年龄,假设客户的真实年龄为40岁,通过训练弱学习器1(决策树1),得到客户的预测年龄为30岁,此时预测年龄和真实年龄差值为10岁(残差)。接着训练弱学习器2来拟合残差10岁,依次类推,直到残差值小于给定的阈值。
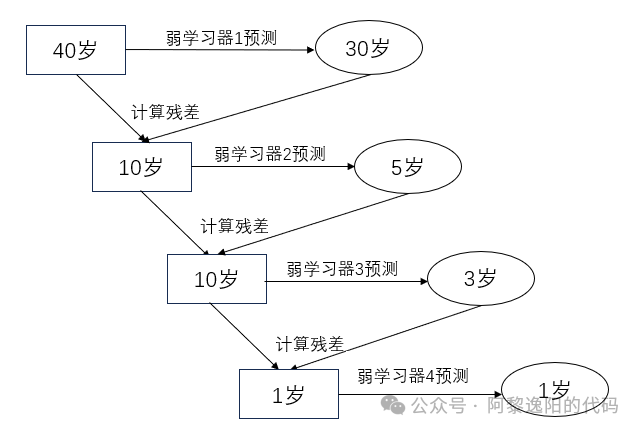
GBDT算法的核心是对残差进行预测,上图预测年龄的最终结果是:30+5+3+1=40岁。
这种思想有点类似我们考试对错题的梳理。首先做一张卷子,然后对卷子进行评估,把错题挑出来,对做错的题重点突破,再对错题进行一轮测试,然后把再次做错的题挑出来,进行重点突破,再对错题进行测试,以此类推,最终的得分是所有轮次得分的和。
2 GBDT算法原理公式推导
上面从感性的角度出发对GBDT原理进行了介绍,本节从理性的角度出发,对GBDT算法原理进行数学推导。
为了大家更轻松地理解后续公式推导,先介绍GBDT算法的基学习器和损失函数,且限定公式推导是不带权重的加法模型。
3.1 基学习器GBDT通过串行训练多棵决策树来生成集成模型,假设已将输入空间划分为J个单元R1,R2,…,RJ,并且在每个单元Rj上有一个固定的输出值cj,于是第M轮训练的回归树可表示为:当输入空间的划分确定时,可以用平方误差来表示回归树对于训练数据的预测误差,用平方误差最小的准则求解每个单元上的最优输出值。此时,I(x∈Rj)表示当训练样本属于Rj的值为1否则为0,cj表示对于属于Rj的样本y值求均值。前M轮训练的所有回归树表示如下:其中,M为树的棵树,T(x;θm)表示决策树,θm为决策树的参数。
3.2 损失函数
一般损失函数公式如下:L(y,f(x))。我们迭代训练多棵树的目的是使预测值和真实值差距越来越小,即损失函数的值越来越小。
3.3 前向分步算法+梯度提升
【1】核心目标
GBDT算法采用加法模型,一定会存在多个优化器不断迭代优化。我们要确保每增加一个基学习器,都要使得总体损失越来越小,即前m步训练得到的模型要比前m-1步的损失要小。则目标可以定义为:即
【2】要解决的问题GBDT算法的目标是要确保每增加一个基学习器,都要使得总体损失越来越小。提升树算法采用前向分步算法,首先确定初始提升树f0(x)=0,则第m步的模型可表示为:其中fm-1(x)是前m-1轮训练得到的模型,通过损失函数极小化确定下一棵决策树的参数θm不同的损失函数,对应的凸优化问题不一样,希望找到一个通用的方法,求解一般性凸优化问题。
【3】将损失函数进行处理往我们的核心目标上靠
为了将损失函数往我们的核心目标上靠,我们把损失函数进行一阶泰勒展开。首先补充一阶泰勒展开公式:其中x0是常量。
从前文知,GBDT算法损失函数的公式如下:且
在第m轮迭代时,可以把fm(x)当成x,fm-1(x)当成x0,T(x;θm)当成Δx。则可进一步简化为:
我们回顾一下第m轮的训练目标:即
我们把一阶泰勒展开的损失函数变形可得到:当
时,第m-1轮的损失函数和第m轮的损失函数差值是完全平方,值大于等于0。即
假设说明叠加的第m棵树并没有带来损失的减少,从模型简洁的原则出发,此时不加这棵树是更好的选择,即终止训练即可。至此,可以整理第m步的训练公式:
将训练数据代入该公式,进而得到第m轮的训练数据集
【4】GBDT实现的步骤
①计算当前损失函数的负梯度进而得到第m轮的训练数据集。
②构造新的训练样本:
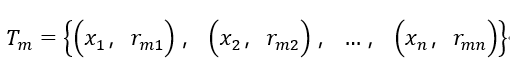
③让当前基学习器去拟合上述训练样本,得到T(x;θm),从而让模型在迭代过程中损失不断减少。
3.4 梯度提升树中梯度的理解
GBDT梯度提升树的损失函数定义为:L(y,f(xi)),它的梯度定义如下:若损失函数为平方损失函数,即
此时,对损失函数求负梯度得到:此时的负梯度就是残差y-f(xi),也就是说,当损失函数是平方损失函数时,负梯度就是残差。不过当损失函数不是平方函数时,负梯度只是残差的近似值,并不完全等于残差。3 GBDT算法流程
本节介绍GBDT算法流程,具体如下:
【1】输入:训练数据集
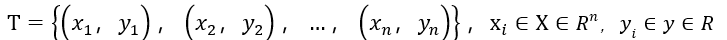
【2】输出:回归树f(x)。
【3】具体步骤:
(1)初始化
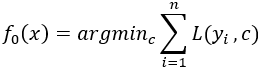
其中,c是常数。
(2)对m=1,2,…,M
a.对i=1,2,…,n,计算
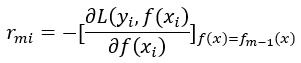
b.对rmi拟合一个回归树,得到第n棵树的叶节点区域Rmj,j=1,2,…,J
c.对j=1,2,…,J,计算
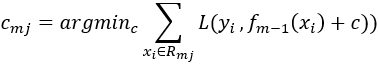
其中损失函数为L(y, f(x))。
d.更新
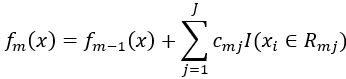
(3)得到回归树
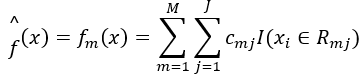
三、GBDT算法参数详解
GBDT算法分为分类梯度提升树和回归梯度提升树,在sklearn中可以直接调用。是一个功能强大的分类器,它有很多参数可以调整。
其基本调用语法如下:
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingRegressor
GradientBoostingClassifier(*, loss='deviance', learning_rate=0.1, n_estimators=100, subsample=1.0,
criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None,
max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, presort='deprecated',
validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
GradientBoostingRegressor(*, loss='ls', learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse', min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None,
random_state=None, max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False, presort='deprecated',
validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0) 主要参数详解:
loss:定义损失函数类型,分类模型和回归模型的损失函数不同。对于分类模型,包含{'deviance','exponential'},默认值deviance,对应逻辑回归对数似然损失,适用于二分类或多分类问题。exponential对应于AdaBoost损失,即指数损失函数。对于回归模型,包含{'ls', 'lad', 'huber', 'quantile'},默认值ls,指最小二乘回归。lad表示最小绝对偏差,huber表示两者的结合,quantile表示分位数损失。如果数据的噪音点不多,用默认的ls比较好,如果噪音点较多,则推荐用抗噪音的损失函数huber。
learning_rate:学习率,默认值0.1。
n_estimators:基学习器数量,即树的棵树,也就是弱学习器的最大迭代次数,默认值100。
subsample:拟合每个基学习器的样本比例,默认值为1,即全部样本用于训练。若值小于1,则表示随机从样本中抽取一定样本用于构建每轮的决策树,有助于减少过拟合,但是会增加样本的偏差,因此取值不能太低,推荐[0.5,0.8]之间。
criterion:指定在构建树时用于测量分裂质量的函数,包含 {'friedman_mse', 'mse', 'mae'}。friedman_mse是一个基于friedman的均方误差的改进版本,用于分类问题,它考虑了类的不平衡性,并尝试优化对数似然损失。mse指均方误差(Mean Squared Error),即预测值和真实值之差的平方的平均值。mae指平均绝对误差(Mean Absolute Error),即预测值与实际值之差的绝对值的平均值。对于GradientBoostingClassifier,该参数通常只接受friedman_mse作为其值。对于GradientBoostingRegressor,通常选用mse和mae。
min_samples_split:拆分内部节点所需的最小样本数,int或float,默认值为2。如果值为整数,表示节点分裂所需的最小样本数。如果值为浮点数(分数),则ceil(min_samples_split*n_samples)是拆分最小样本数,这个参数可以防止树过度适应训练数据。
min_samples_leaf:在每个叶子节点上必须有的最小样本数,int或float,默认值1。这个参数和min_samples_split一样,也是用来防止过拟合的。
min_weight_fraction_leaf:叶节点上样本权重的最小加权分数,默认值0。
max_depth:树的最大深度,默认值为3。如果设置为None,则节点会一直分裂到所有叶子都是纯的,或者直到所有的叶子都包含少于min_samples_split个样本。如果树太深,可能会导致过拟合,因此通常需要通过交叉验证来选择一个合适的值。
min_impurity_decrease:如果分裂导致的不纯度减少小于此值,则树节点将不会被分裂,默认值0。
min_impurity_split:节点被分裂所需的最小不纯度,默认值None。
init:初始化估计器对象,默认值None。如果为zero,则初始预测为0。
random_state:随机数生成器的种子,用于控制模型的随机性。如果设置为一个整数,则每次运行模型时都会得到相同的结果。如果设置为None,则每次运行模型时都会得到不同的结果。
max_features:在寻找最佳分裂时考虑的特征数量。 如果值为整数,比如5,则在每个节点分割时都会随机选择5个特征进行评估。如果值为浮点数,表示考虑的特征比列。比如0.5,表示每次分割时都会随机选择一半的特征进行评估。如果设置为‘auto’,则max_features=sqrt(n_features)。如果设置为'sqrt',则与‘auto’相同,即max_features=sqrt(n_features)。如果设置为‘log2’,则max_features=log2(n_features)。更大的max_features值将会使模型考虑更多的特征,从而可能提高模型的性能,但同时也会增加计算复杂度和过拟合的风险。
verbose:控制模型训练时的输出信息,如果设置为0,则不输出任何信息。如果设置为1,则会输出进度条和其他信息。
max_leaf_nodes:树上叶节点的最大数量,默认值None。
warm_start:如果设置为True,则使用上一次调用的解决方案来初始化添加更多的树,否则完全重新开始。
validation_fraction:验证集比例,默认值0.1。
n_iter_no_change:在提前停止之前,没有改进所需的迭代次数,默认值None。
tol:优化的容忍度,用于提前停止,默认值1e-4。
ccp_alpha:复杂度参数(特定用于回归问题),用于最小成本复杂度剪枝。增加alpha会增加剪枝的程度,从而可能导致更小、更简单的树。
alpha:只有GradientBoostingRegressor中有,当我们使用huber损失或分位数损失时,要指定分位数的值,默认是0.9,如果噪音点较多,可以适当降低这个分位数的值。
四、GBDT算法在车贷领域的应用
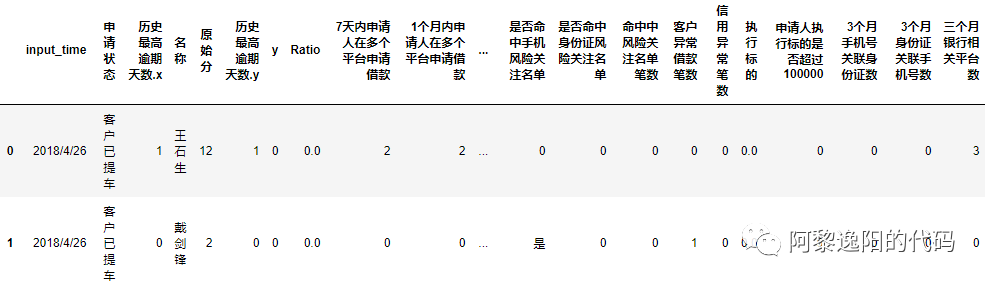
项目背景:由于公司发展车贷业务,需要判断新进来的申请人有多大的概率会逾期,根据逾期的概率和资金的松紧程度决定是否放贷。 现在有一批历史上是否违约的客户样本数据(由于数据涉及安全问题,也是职业操守要求,故此数据不是原始数据,是经过处理的)。 想根据这批历史数据训练GBDT模型,得到模型结果,预测未来新申请的客户逾期概率。从而决定新申请人是通过、转人工核验还是拒绝。 1 导入基本库并设置文件存放路径 首先导入基本库,并设置数据的存放的地址,代码如下: import os import numpy as np import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import RandomForestRegressor os.chdir(r'F:\公众号\88_GBDT') 2 导入待建模的数据 用pandas库导入待建模的csv格式数据。 data = pd.read_csv('testtdmodel.csv', sep=',', encoding='gb18030') 注:由于数据中存在中文,如果不使用encoding对编码进行申明会报如下错误: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 2: invalid start byte 把endcoding的值设置为gb18030或gbk可以解决此类问题,成功导入数据。 3 看下数据基本情况 3.1 用head函数看下数据表头和前几行数据 我选择看前两行的数据,如果括号里为空默认展示前五行的数据,可以根据需要把2改为你想展示的行数。也可以用tail函数展示后几行数据。 data.head(2) 结果:
3.2 用value_counts函数观测因变量y的数据分布 在信贷中,有些客户因为忘记了还款日期、或者资金在短期内存在缺口(不是恶意不还),可能会导致几天的逾期,在催收后会及时还款。 故一般不把历史逾期不超过x天(根据公司的实际业务情况和数据分析结果得出)的客户定义为坏客户(这里的坏不是坏人的意思,纯粹指逾期超过x天的客户)。 在本文把逾期超过20天的客户标签y定义为1(坏客户),没有逾期和逾期不超过20天的客户标签y定义为0(好客户)。 data.y.value_counts() 得到结果:
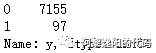
本文总计样本数量为7252,其中7155个样本是好客户,97个样本是坏客户。说明0和1的分布很不均匀,我们统计一下占比:
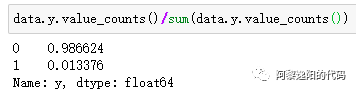
发现0的占比达到了98.6%,1的占比不到2%,这是典型的样本不均衡问题。 如果我们把所有的客户都预测成好客户,模型可以达到98.6%的准确率。但是这个结果是毫无意义的,因为模型没起到区分逾期和非逾期客户的作用,没有达到建模的目的。 实际中很多问题可能都是数据分布不均匀的,比如患病的人数和不患病的人数、欺诈商户和正常商户、逾期的客户和不逾期的客户等等。 不过这些都是正常现象,想一想如果逾期客户数超过了不逾期的人数,公司早就倒闭了。 那么建模的目的就是想把钱尽可能多地贷给能按期还钱的客户,尽可能多地拒绝可能会逾期的客户。这样公司的钱才能挣得更多的利息,产生更少的坏账,总收益才能最大化。 4 创建和训练分类GBDT模型由于y的数量比较少本文就不区分训练集和测试集了,直接用全量数据训练GBDT模型,代码如下: columns_model = ['1个月内借款人身份证申请借款平台数','7天内关联P2P网贷平台数','3个月内关联P2P网贷平台数','3个月手机号关联身份证数','3个月内申请人关联融资租赁平台数','二度风险名单个数','是否命中身份证风险关注名单','原始分','一度风险名单个数'] X_train = data[columns_model] #生成入模自变量 y_train = data['y'] #生成入模因变量 # 创建GBDT分类器实例 gbdt = GradientBoostingClassifier(n_estimators=100, max_depth=4, random_state=42) # 使用训练数据进行训练 gbdt.fit(X_train, y_train) # 使用测试数据进行预测 y_pred = gbdt.predict_proba(X_train) 模型参数说明: n_estimators为100,即GBDT中用到100棵决策树做为基模型。 max_depth为4,即限制每棵树的深度为4。 random_state设置为整数,则每次运行模型时都会得到相同的结果。 由于篇幅原因,本文不对调参进行详细说明,后续文章分专题进行讲解。 用训练结果绘制KS曲线,看下模型效果,代码如下: import numpy as np import matplotlib.pyplot as plt import matplotlib matplotlib.rcParams["font.sans-serif"] = ["SimHei"] def ks_plot(predictions, labels, cut_point=100): good_len = len([x for x in labels if x == 0]) # 所有好客户数量 bad_len = len([x for x in labels if x == 1]) # 所有坏客户数量 predictions_labels = list(zip(predictions, labels)) good_point = [] bad_point = [] diff_point = [] # 记录每个阈值点下的KS值 x_axis_range = np.linspace(0, 1, cut_point) for i in x_axis_range: hit_data = [x[1] for x in predictions_labels if x[0] <= i] # 选取当前阈值下的数据 good_hit = len([x for x in hit_data if x == 0]) # 预测好客户数 bad_hit = len([x for x in hit_data if x == 1]) # 预测坏客户数量 good_rate = good_hit / good_len # 预测好客户占比总好客户数 bad_rate = bad_hit / bad_len # 预测坏客户占比总坏客户数 diff = good_rate - bad_rate # KS值 good_point.append(good_rate) bad_point.append(bad_rate) diff_point.append(diff) ks_value = max(diff_point) # 获得最大KS值为KS值 ks_x_axis = diff_point.index(ks_value) # KS值下的阈值点索引 ks_good_point, ks_bad_point = good_point[ks_x_axis], bad_point[ks_x_axis] # 阈值下好坏客户在组内的占比 threshold = x_axis_range[ks_x_axis] # 阈值 plt.plot(x_axis_range, good_point, color="green", label="好企业比率") plt.plot(x_axis_range, bad_point, color="red", label="坏企业比例") plt.plot(x_axis_range, diff_point, color="darkorange", alpha=0.5) plt.plot([threshold, threshold], [0, 1], linestyle="--", color="black", alpha=0.3, linewidth=2) plt.scatter([threshold], [ks_good_point], color="white", edgecolors="green", s=15) plt.scatter([threshold], [ks_bad_point], color="white", edgecolors="red", s=15) plt.scatter([threshold], [ks_value], color="white", edgecolors="darkorange", s=15) plt.title("KS={:.3f} threshold={:.3f}".format(ks_value, threshold)) plt.text(threshold + 0.02, ks_good_point + 0.05, round(ks_good_point, 2)) plt.text(threshold + 0.02, ks_bad_point + 0.05, round(ks_bad_point, 2)) plt.text(threshold + 0.02, ks_value + 0.05, round(ks_value, 2)) plt.legend(loc=4) plt.grid() plt.show() ks_plot(y_pred[:,1], y_train) 得到结果:
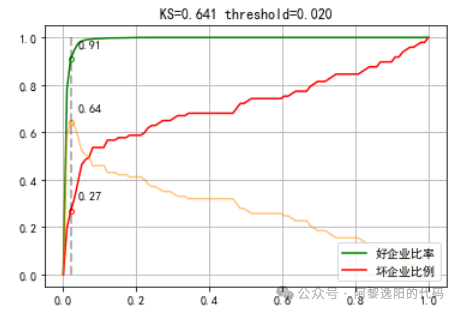
可以发现分类GBDT模型的KS值为0.641。为了看得更清楚,用toad包打印一下KS表,代码如下: import toad d1 = toad.metrics.KS_bucket(y_pred[:, 1], y_train,bucket=20,method='quantile') d1 得到结果:
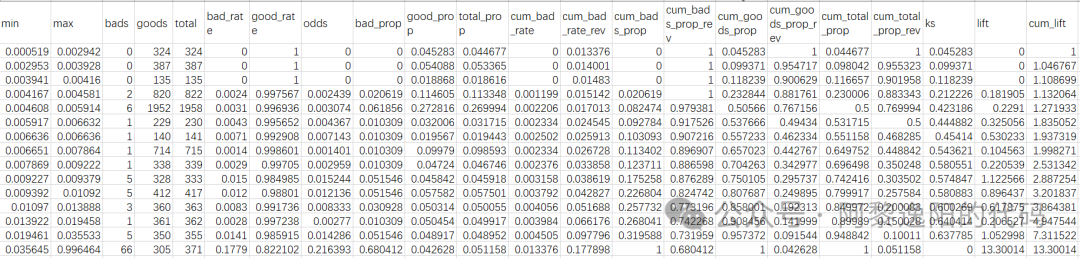
从上表知KS值为0.64,且当预测概率大于0.0356时,能抓到66个坏客户,这一箱的lift为13.3。 5 创建和训练回归GBDT模型 上一节用分类GBDT模型训练了数据,为了对比,这一节用回归GBDT模型训练数据。 代码如下: gbdt2 = GradientBoostingRegressor(n_estimators=100, max_depth=4, random_state=42) # 使用训练数据进行训练 gbdt2.fit(X_train, y_train) # 使用测试数据进行预测 y_pred2 = gbdt2.predict(X_train) ks_plot(y_pred2, y_train) 得到结果:
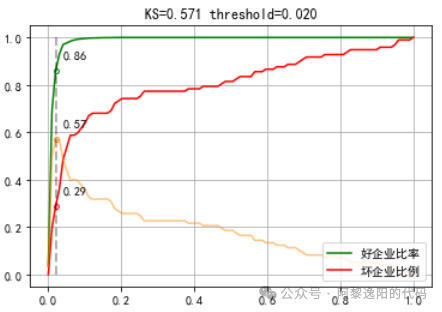
可以发现,应用分类GBDT和回归GBDT训练数据得到的结果相差较大,KS 从原来的0.64降到了0.57。 用toad包看下ks表,代码如下: d2 = toad.metrics.KS_bucket(y_pred2, y_train,bucket=20,method='quantile') d2 得到结果:
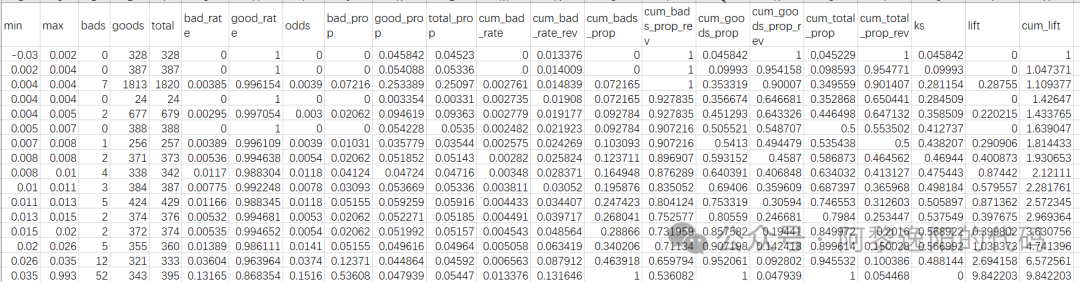
从上表可以发现分20箱时KS值变成了0.568,和KS图中的0.57不一样。 这是由于分箱数量不一致导致的,感兴趣的可以测试调整下分箱数,当设置为10时,结果就一致了。 机灵的小伙伴应该发现了,如果单看KS去评价模型好坏的话。在模型算法和参数没有做任何调整的前提下,分箱个数也会导致KS值变化。 至此,GBDT原理和实现已讲解完毕,如想了解更多建模内容,可以翻看公众号中“风控建模”模块相关文章。 后续会详细介绍XGBoost和LightGBM的原理和应用,敬请期待。 参考文献 https://scikit-learn.org.cn/view/628.html https://www.cnblogs.com/cgmcoding/p/13577727.html https://vimsky.com/examples/usage/python-sklearn.ensemble.GradientBoostingClassifier-sk.html
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号