用Golang实现K-NN算法
原创

K近邻算法用来对观察数据打标签/分类。通过和已打标样本对比 两者距离,跟哪个样本近就标注该观察数据应该归为什么标签。这通常也是机器学习的一个基础入门算法。

比如说图片这个例子, 这里有5000个28x28像素点阵的灰阶 (0-255) 手写体图像 ,画了数字0到 9。这是部分的示例。
5000个数字图像包括了训练集。并且我们会有一些新的手写体图像,这些还未进行分类打标签。这些未分类图像我们所知的只是灰阶像素点阵。算法工作是通过找到未分类图像在训练集中和哪个样本最接近。最合理的预测就是最接近的图像就是拥有那个样本的标签(所谓的物以类聚)。这也就是预测未知数据。
最接近的方法,就是我们去查找未分类图像和每个样本图片去比较。挨个像素比较,然后汇总所有像素点的比较结果。总体来看,汇总结果差异越小,那么就是越像那个分类。
标准测量差异方法叫做 Euclidean策略。假设两个vectors x⃗, y⃗,向量长度是28 × 28 = 784。包含了8-bit 非负数0…255, 然后定义距离就是
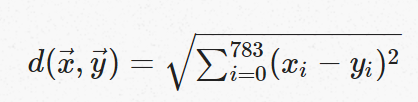
这个问题我们同时给了500个图像来分类, 并且他们是验证集。在跑完所有的验证集的500个数据, 来计算预测准确率 (这里已知标签, 假装不知道他们是如何分类的),
CSV文件包含了训练集和验证集。 每一行对应一个图像. 第一栏是标签, 后面的784栏是每个像素点的灰阶数字.
这里描述的k-近邻分类中的k = 1.
package main
import (
"bytes"
"fmt"
"io/ioutil"
"strconv"
)
type LabelWithFeatures struct {
Label []byte // 标签
Features []float64 // 特征列表
}
func NewLabelWithFeatures(parsedLine [][]byte) LabelWithFeatures { // 读取样本
label := parsedLine[0]
features := make([]float64, len(parsedLine)-1)
for i, feature := range parsedLine {
// skip label
if i == 0 {
continue
}
features[i-1] = byteSliceTofloat64(feature)
}
return LabelWithFeatures{label, features} // 返回数据结构
}
var newline = []byte("\n")
var comma = []byte(",")
func byteSliceTofloat64(b []byte) float64 {
x, _ := strconv.ParseFloat(string(b), 32)
return x
}
func parseCSVFile(filePath string) []LabelWithFeatures { // 读取CSV数据,生成样本集的方法
fileContent, _ := ioutil.ReadFile(filePath)
lines := bytes.Split(fileContent, newline)
numRows := len(lines)
labelsWithFeatures := make([]LabelWithFeatures, numRows-2)
for i, line := range lines {
// skip headers
if i == 0 || i == numRows-1 {
continue
}
labelsWithFeatures[i-1] = NewLabelWithFeatures(bytes.Split(line, comma))
}
return labelsWithFeatures
}
func squareDistance(features1, features2 []float64) (d float64) {
for i := 0; i < len(features1); i++ { // 遍历所有特征
d += (features1[i] - features2[i]) * (features1[i] - features2[i]) // 特征距离平方之和
}
return
}
var trainingSample = parseCSVFile("trainingsample.csv")
func classify(features []float64) (label []byte) {
label = trainingSample[0].Label
d := squareDistance(features, trainingSample[0].Features)
for _, row := range trainingSample { // 在所有样本中 遍历查找
dNew := squareDistance(features, row.Features) // 计算未分类数据和样本间的距离
if dNew < d { // 找到距离最小的那个样本
label = row.Label // 这个样本的标签就是未分类数据的标签
d = dNew
}
}
return
}
func main() {
validationSample := parseCSVFile("validationsample.csv") // 导入样本
totalCorrect := 0
for _, test := range validationSample { // 验证集合
if string(test.Label) == string(classify(test.Features)) {
totalCorrect++ // 验证模型预测准确次数+1
}
}
fmt.Println(float64(totalCorrect) / float64(len(validationSample))) // 打印模型预测准确率
}原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号