负载均衡的概念及算法介绍(引入一致性哈希实现负载均衡)
原创
负载均衡的概念及算法介绍(引入一致性哈希实现负载均衡)
原创
潋湄
发布于 2024-09-18 23:27:54
发布于 2024-09-18 23:27:54
随着当代开发架构下服务器的增多以及用户量的增加,如何充分利用已有服务器的资源服务尽可能多的用户成了企业厂商们思考的一个问题,而负载均衡就是解决这个问题的一大方法。
概念
什么是负载均衡?
举个例子,你是公司老板,有三个员工,你不可能把所有工作都派给一个人,而是将工作尽量平均地分给你的下属,追求一种所谓的平衡。
官方概念是:
负载均衡是一种在计算机网络中分发资源的技术,用于在多个服务器之间分配网络流量或请求,以此来优化资源使用、最大化吞吐量、最小化响应时间,避免因为单一节点负载压力过大导致服务宕机,提高服务并发量与可用性。
但是注意,我前面用了一个词,尽量平均分配,因为负载均衡它是一种思想,一种技术,它的本质其实就是平均化服务分配,提高服务可用性,但是具体实现依靠于不同的负载均衡算法,因此,选择不同的负载均衡算法会对实际的具体服务有很大影响。
负载均衡算法
常见的负载均衡架构模型有Nginx(七层负载均衡)与LVS(四层负载均衡),负载均衡算法有很多,但是并不代表哪一种是最优的,一定要根据实际场景进行选择
随机
随机选取众多服务节点中的一台执行:
1 3 4 5 1 2 4 5 1 3 5 4 1 2 4 随机性太强,可能导致某个节点服务过多导致压力过大
轮询
按照编号顺序从小到大执行,执行序列是下面这样:
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5这种算法看似比较平均,但是实际上如果有100个服务节点,不同服务器来了,每次都从编号较小的服务开始选择,可能导致编号较小的服务节点负载压力过大,同时由于不同服务的数据请求量也不同,有可能一个服务节点的服务压力是其他节点的好几倍,这时这种算法并不合适
加权轮询
是上面普通轮询的优化,加权即给每个服务节点分配不同的权重,之后根据具体服务的请求量来分配服务节点,它的理想情况是不同的服务根据他们的服务量比例请求对应的服务节点,但是实际情况下服务的请求量有很大变动,这时加权轮询并不适用
最少连接
选择当前服务最少的服务节点处理请求,适合用于服务处理时长长短不一的情况
IP哈希
通过客户端的IP地址进行哈希计算,根据哈希值将请求分配给特定的服务器,这样可以保证来自同一个IP的请求总是被分配到同一台服务器上,有利于聊天这种实际情况下的会话保持
URL哈希
根据请求的URL进行哈希计算,将请求分配给服务器,这种算法适用于缓存服务器的场景,因为相同的URL请求应该返回相同的内容
公平
根据具体服务节点的响应时间进行分配,如果一个服务节点的响应时间比较短,那么它接收的服务就会多一些
一致性哈希实现负载均衡
为什么会引入一致性哈希来实现负载均衡呢,一致性哈希是分布式的知识点,它主要用于将请求分配到多个节点和服务器上,正好和负载均衡的分配服务资源契合,因此很适合实现负载均衡
工作原理
一致性哈希的核心是,给不同的服务节点设立多个虚拟节点,将这些虚拟节点平均分配到一个哈希环上,之后通过它的数据分配原理与节点倾斜机制来合理分配服务节点
举个例子就好理解了,比如说现在一个环上有三个服务节点A(160),B(20),C(280),括号里为对应的权值,现在把它们分配到一个环总值为300的换上,这个环就是一个哈希环:
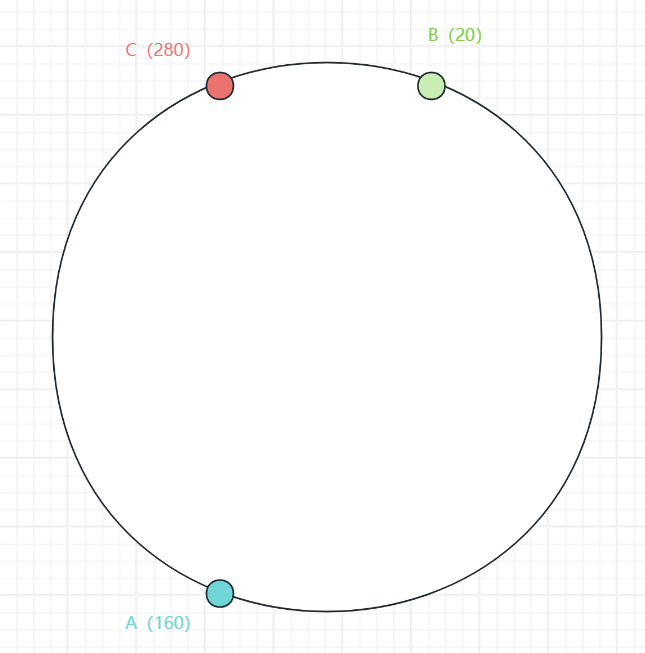
原始三个节点的哈希环
何为虚拟节点呢?其实就是为了让三个节点均匀地占满整个圆环,会给每个节点设立多个虚拟节点,让三个节点各自的节点群占满哈希环:
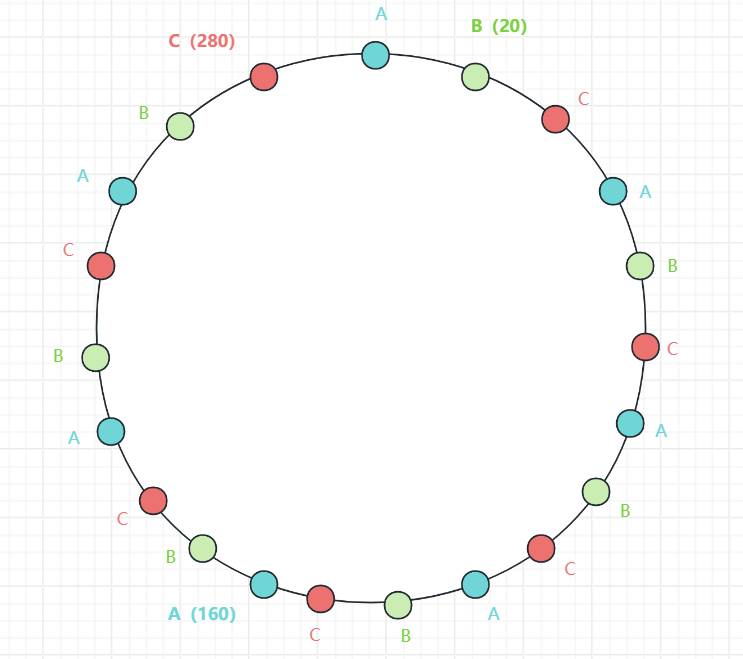
引入虚拟节点后的哈希环
这样整个环就被三个节点均匀占有了,当有请求过来时,会解析成哈希值到环上,之后沿着该环顺时针最近的服务节点就负责处理该事务,这就是一致性哈希的数据分配原理,例如有一个权值35的请求来了,这时会沿着哈希环顺时针找到第一个服务节点C,那么服务节点C便会处理这个请求
那么节点倾斜机制又是什么呢?这里要从节点加入与删除两方面说起:
节点加入:有节点加入时,一致性哈希算法会根据当前节点的哈希值在哈希环上为它生成虚拟节点,这样当有新的服务过来时,会从新节点的虚拟节点开始顺时针查找,直到遇到已有节点的虚拟节点,这一段区域内的数据都重新分配给新节点
节点删除:当某个节点删除时,会将原本删除节点负责的服务顺时针顺延到下一个服务节点上从而保证服务的可用性
优势
因此,一致性哈希的优点就在于,即使服务节点数量发生变更,也只需要迁移很小部分的数据便可以保证整体服务的完成,同时它的数据分配以及节点倾斜机制也保证了服务的稳定性,而这种思想也很适合应用于负载均衡的实现当中
以上便是负载均衡的大致介绍了,希望对你有所帮助!!!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号