
为什么神经网络工作得这么好?
我理解用正反两种方法训练梯度下降的神经网络的所有计算步骤,但我试着思考为什么它们比logistic回归更好。
就目前而言,我能想到的就是:
( A)神经网络可以学习它自己的参数
( B)有比简单的logistic回归更多的权重,从而允许了更复杂的假设。
有人能解释为什么神经网络在一般情况下工作得这么好吗?我是一个相对初学者。

回答 8
Stack Overflow用户
发布于 2016-07-26 09:52:38
神经网络可以有大量的自由参数(相互关联的单元之间的权重和偏差),这使它们能够灵活地拟合高度复杂的数据(如果训练正确的话),而其他模型过于简单,无法拟合。这种模型的复杂性带来了训练这样一个复杂网络的问题,并确保得到的模型概括到它所训练的例子(通常,神经网络需要大量的训练数据,而其他模型则不需要)。
传统的logistic回归被限制在使用线性分类器的二进制分类中(尽管多类分类可以很容易地通过一-vs、一-vs等方法实现,并且存在允许非线性分类任务的逻辑回归的核心变体)。因此,一般情况下,logistic回归通常应用于更简单、线性可分离的分类任务,在这些任务中可以获得少量的培训数据。
像logistic回归和线性回归这样的模型可以被认为是简单的多层感知器(关于如何使用的一种解释,请查看本站 )。
总之,模型的复杂性使神经网络能够解决更复杂的分类任务,并具有更广泛的应用(尤其是应用于原始数据,如图像像素强度等),但它们的复杂性意味着需要大量的训练数据,训练它们可能是一项困难的任务。
Stack Overflow用户
发布于 2018-07-05 11:54:51
最近,Naftali Tishby博士关于信息瓶颈的观点在学术界得到了广泛的应用,以解释深层神经网络的有效性。他的视频解释了这个想法(下面的链接)可能相当密集,所以我将尝试给出核心想法的精馏/一般形式,以帮助建立直觉。
https://www.youtube.com/watch?v=XL07WEc2TRI
为了使你的思维有基础,将MNIST任务中的数字分类。为此,我只讨论简单的完全连接的神经网络(而不是通常用于MNIST的卷积神经网络)。
NN的输入包含隐藏在其中的输出的信息。需要一些函数才能将输入转换为输出表单。很明显。建立更好的直觉所需的思维的关键区别在于将输入看作是一个包含“信息”的信号(我不想在这里深入到信息论中)。其中一些信息与手头的任务相关(预测输出)。把输出看作是一个有一定数量的“信息”的信号。神经网络试图“连续细化”和压缩输入信号的信息,以匹配所需的输出信号。将每一层看作是切断输入信息不必要的部分,并在通过网络的过程中保存和/或转换输出信息。完全连通的神经网络将输入信息转化为最终隐层的一种形式,从而使输入信息与输出层线性分离。
这是对神经网络的一个很高层次和最基本的解释,我希望它能帮助你更清楚地看到它。如果有什么地方你想让我澄清,请告诉我。
are . within的工作中还有其他一些重要的部分,比如小批量噪声如何帮助训练,以及如何将神经网络层的权重看作是在问题的约束范围内进行随机游走。这些部分更详细一些,我建议你先玩一下神经网络,然后上一门关于信息论的课程来帮助你建立理解。
Stack Overflow用户
发布于 2018-07-16 22:43:22
假设您有一个大型数据集,并且您希望为此构建一个二进制分类模型,那么现在您已经指出了两个选项。
- Logistic回归
- 神经网络(现在考虑FFN )
神经网络中的每个节点都将与激活函数相关联,例如,让我们选择Sigmoid,因为Logistic回归也在内部使用sigmoid进行决策。
让我们看看当应用于数据时逻辑回归的决策是如何的。
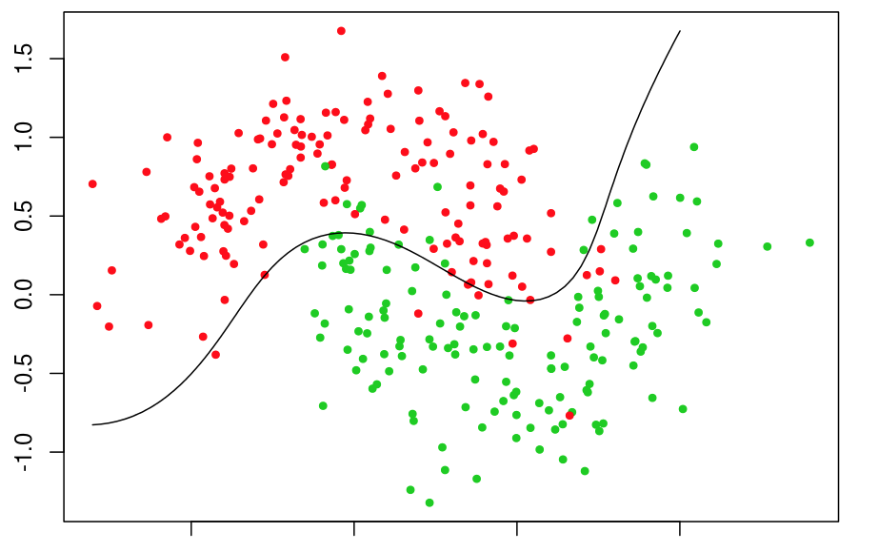
看到红色边界上的一些绿点了吗?
现在让我们看看神经网络的决策边界(请原谅我使用了不同的颜色)。
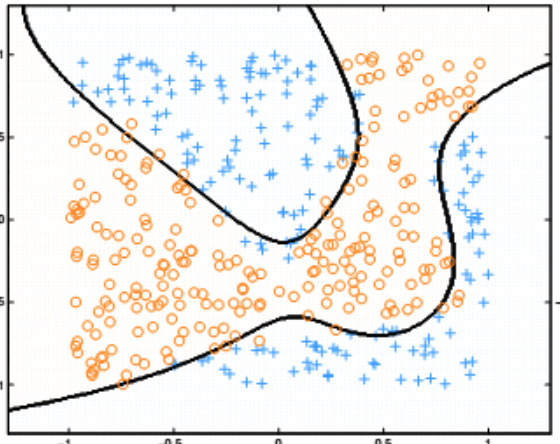
为什么会发生这种事?为什么神经网络的决策边界如此灵活,给出的结果比Logistic回归更准确?
或者你问的问题是“为什么神经网络工作得这么好?”是因为它是隐藏的单位或隐藏的层和它们的表现力。
让我这样说。你有一个logistic回归模型和一个神经网络,其中包括100个神经元的Sigmoid激活。现在每个神经元将等价于一个logistic回归。
现在假设100个后勤单位一起训练来解决一个问题,而不是一个logistic回归模型。由于这些隐藏层的存在,使得决策边界扩展,得到了更好的结果。
当你在实验的时候,你可以增加更多的神经元,看看决策边界是如何变化的。logistic回归与单神经元神经网络是一致的。
以上给出的只是一个例子。神经网络可以训练成非常复杂的决策边界。
https://stackoverflow.com/questions/38595451
复制


















腾讯云开发者
