Nat. Rev. Drug Discov. | 定量构效关系(QSAR)建模和深度学习在药物发现中的应用

Nat. Rev. Drug Discov. | 定量构效关系(QSAR)建模和深度学习在药物发现中的应用

DrugOne
发布于 2023-12-26 18:54:24
发布于 2023-12-26 18:54:24
今天为大家介绍的是来自Artem Cherkasov团队的一篇综述。定量构效关系(QSAR)建模是60年前提出的一种方法,并广泛应用于计算机辅助药物设计中。近年来,人工智能技术(尤其是深度学习)、分子数据库的迅速增长和计算能力的显著提升,共同促进了一个新领域的出现,作者称之为“深度QSAR”。自深度QSAR在小分子药物发现领域的首次应用已有十年,这篇综述描述了这一领域的关键进展,包括在分子设计中应用深度生成和强化学习方法、用于合成规划的深度学习模型,以及在基于结构的虚拟筛选中应用深度QSAR模型。文章还关注了量子计算的出现,这一技术有望进一步加速深度QSAR应用,并强调了开源和民主化资源在支持计算机辅助药物设计中的必要性。

定量构效关系(QSAR)建模是一种将化学结构的定量描述与其生物活性或其他化学性质关联起来的方法。这个领域可以追溯到1962年Hansch等人的一篇开创性论文。自那以后,随着生物学和化学数据的大量扩展以及越来越复杂的机器学习算法的使用,这个领域取得了显著进展。此外,QSAR建模概念已经在药物设计、医疗保健、材料科学和教育等多个数据丰富的研究领域广泛应用。随着各研究领域数据集的规模和复杂性的增长,深度学习作为一种能够识别大数据中复杂模式并据此作出准确预测的机器学习类型,开始得到关注。现代深度学习的起源可以追溯到20世纪60年代中期Ivakhnenko和Lapa出版的基础书籍。过去十年里,深度学习在图像识别、自然语言处理等领域的应用尤其迅速发展,这与计算能力的大幅增加、方法论的进步和数据的扩展密切相关。深度学习在QSAR建模中的初步应用始于2012年由Kaggle主办的Merck分子活性挑战。参赛者被要求使用从化合物的化学结构生成的数值描述符来构建QSAR模型,并通过预测训练集外化合物的生物活性来评估模型。
深度QSAR模型的建模原理
深度QSAR(定量构效关系)建模是传统化学信息学任务的一个发展方向,例如传统的QSAR建模或化学相似性搜索依赖于分子描述符,这些描述符用于在不同层级(从1D到3D,甚至4D,图1)数值化地表征分子结构。然而,将深度学习适配到化学数据集需要新型的分子表示方式。在这些新方式中,传统的描述符工程(涉及生成和选择最具信息性的数值分子描述符)被分子嵌入所取代,其中分子通过人工创造的高维空间中的向量来表示,并在使用神经网络架构的学习任务中被应用。传统的机器学习方法使用基于化学结构的常规化学描述符进行模型开发前的计算,而深度学习模型则可以使用从标准化学输入数据(如分子SMILES或化学图)创建的分子嵌入,这些嵌入在学习过程中可以修改,以达到对感兴趣性质的最准确预测。因此,这些方法通常通过对特定任务的深度学习模型训练来学习与分子或原子对应的特征向量。

图 1
不同于传统QSAR建模,化学结构嵌入(可视为传统化学信息学中化学描述符计算的类似过程)和使用这种表示的学习是模型优化过程中不可分割的组成部分。最终,实践者必须决定哪种模型架构最适合手头的任务。模型可以基于人类经验启发式地设计,或通过进化算法、神经架构搜索或元学习半自动设计。近期研究表明,深度QSAR方法相对于传统QSAR方法的一个重要优势是,它们可以通过知识转移更有效地解决多目标优化任务,即同时使用不同任务可用的不同数据来提高每个任务的预测准确性。然而,也有研究显示,模型对各自的单任务QSAR模型的改进并不总是保证的:取决于针对单独目标的活性之间的相关程度,性能可能变得更好或更差。
传统的QSAR建模关注的领域,如数据整理、模型适用领域和独立模型验证,仍然是构建深度QSAR模型时需要考虑的关键领域。化学和生物数据整理的方法结合了自动和手动工作,但数据集的规模意味着现在需要能够有效处理大规模数据整理的方法。为此,研究人员正在开发自动化工作流程来处理训练和外部数据集,例如KNIME中的数据集,以确保模型的可信赖性。同样,深度QSAR模型需要严格的外部验证。这一QSAR模型开发的关键方面已在文献中被广泛讨论,且已开发出严格的模型验证工作流程。这些工作流程可以在为大数据集构建深度QSAR模型时使用,但其执行需要显著的计算资源。此外,随着用于识别新活性化合物的外部虚拟筛选集的大幅扩展,评估深度QSAR模型的适用领域(即外部数据是在训练数据集的分布内还是外部)也变得更加具有挑战性。
Deep QSAR与生成式建模

图 2
传统上,QSAR模型用于虚拟筛选化学数据库,以识别可以购买并进行测试的感兴趣分子。然而,药物化学的进步需要发现新的化学实体。从头开始(de novo)生成新分子涉及分子结构的构建、评分和优化。近期,利用结合生成化学的深度QSAR在这些任务上取得了进步。用于de novo分子设计的方法包括基于规则和无规则的方法,这两种方法都被证明能识别新的生物活性化合物。基于规则的方法使用分子构建块集和化学转化(如虚拟反应方案)来生成结构。相比之下,无规则的“生成”深度学习方法从训练数据的学习统计分布中抽样新分子,无需在化学术语中明确表示其分子结构,这个分子设计过程很难以易于解释的方式描述。许多生成药物设计方法基于深度神经网络(图2)。最著名的方法是化学语言模型,它利用分子的SMILES字符串文本表示来学习字符串的内在语法,并生成对应于新颖现实分子的新字符。此外还有其他生成学习架构,包括结合基于规则和无规则网络的混合方法。上述所有方法通常从神经网络在模型训练期间学习到的分子结构的潜在表示中抽样新分子;即,它们充当统计结构生成器。在分子构建过程中或之后的某个时刻,提出的设计分子将根据期望的功能进行评估和优先排序;即,它们的生物活性和/或其他属性。生成分子的目标属性的虚拟评估是设计过程中最关键和最容易出错的部分。新分子的评分可以通过多种方式进行,包括使用外部QSAR模型或用具有期望活性的参考分子丰富训练数据、迭代调整生成模型的参数以优先构建具有期望属性的分子(例如,通过一次性或少量学习、迁移学习或强化学习),或直接使用生成模型学习到的概率作为评估标准。
目前,在生成化学领域,结合外部评分的化学语言模型似乎占据主导地位,这可能归因于相应软件工具的可用性。因此,用于评估分子生物活性的深度QSAR模型最近与化学语言模型结合使用,既可以作为单独的外部工具对生成分子按其活性进行排名,也可以作为模型内置的评分函数,引导化学结构生成朝向具有期望性质的分子。虽然通过生成分子设计方法提出的化合物的实验验证研究仍然不多,但也开始出现。与传统的QSAR模型类似,当应用于数据质量差、缺乏适当验证或应用于超出领域数据的情况时,深度QSAR模型的性能和准确性会下降。为了增加生物活性预测的信心,可以使用模型集成,结合多数投票方法进行预测。计算模型能在几秒至几小时内向药物化学家提供潜在的新药候选物,因此,在这个过程中,合成化学物进行后续实验评估仍然是一个时间限步骤。药物和材料设计的机器人平台的快速发展刺激了高效化学信息学工具的创建,以规划和指导有机合成。这些工具旨在评估化合物的合成可行性,并在可用的起始材料和目标分子之间提出可行的合成路线。
机器学习模型在分子构建和合成规划方面的发展为完全自动化的分子设计提供了新的机会。在这种全自动化设计中,机器人平台能够在不需要人类干预的情况下,就要合成的分子的结构和相关合成计划做出决策。这种方法可以与深度QSAR模型自然地结合,指导具有期望生物学和理化性质的化合物的合成。这种模型整合的独特之处在于,需要即时处理自动化化学生成的数据,并将模型预测转化为新的合成指令。在自动化设计和合成具有期望属性、纯度、产量和生物活性的化合物的过程中,优化多个目标显然是必要的。这些系统产生的大量数据表明,特别擅长处理大数据集和多任务优化的深度QSAR模型的使用将会增长。已经有关于这种全自动化系统的原型被报告出来。作者预计,人工智能驱动的化学合成的方法和软件的快速改进,将开启一个由深度QSAR辅助的人工智能驱动的合成化学的新时代。
基于结构筛选中的Deep QSAR应用
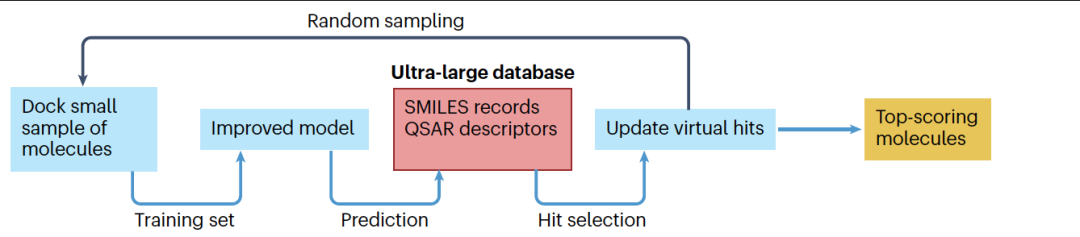
图 3
虚拟筛选大型分子库(通常超过100万种化合物)是一种常用方法,用于在有适合的蛋白质靶标结构信息时识别潜在的配体。这些计算方法通常涉及两个步骤:将分子对接到结合位点以实现真实的构象,并根据这些构象进行排名,从而支持关于哪些化合物进入实验测试的决策。因此,分子对接方法的常见目标包括预测配体的构象和它们的结合评分,这些评分预期与实验测量的结合亲和力相关。在传统的对接方法中,对接评分只能在预测了配体构象之后才能计算;因此,即使在当前的计算能力下,对接和评分包含数十亿分子的超大化学库仍然非常具有挑战性。最近,随着一种名为“深度对接”的方法的出现,对超大化合物库快速计算对接评分的挑战得到了解决。
2006年,人们首次尝试使用QSAR建模和主动学习方法从计算成本较低的化学描述符中预测虚拟筛选库中小分子化合物的对接评分,这种方法被称为渐进式对接。这种方法利用从虚拟筛选库中选定的一小部分小分子通过对特定蛋白质靶标的对接产生的评分。这些小分子的对接评分被用作目标属性(取代传统的生物活性测量),以构建QSAR模型,然后用于估计尚未处理的配体的对接结果,并迭代移除预测有不利评分的条目,以节省计算成本。渐进式对接在约90,000种分子上进行了测试,这些分子通过对接程序Glide与当时可用的多个蛋白结构进行筛选。对于这些靶标,使用蛋白质独立的配体描述符来估计尚未对接化合物的连续Glide SP值,同时只使用数据库的10%或20%进行训练。使用这些线性QSAR模型估计Glide SP评分,实现了虚拟筛选速度提高2.6倍,同时保持了高达99%的命中恢复率。几年后发布的NNscore方法引入了非线性QSAR建模来评估对接评分。随后Svensson等人提出了使用构象预测器准确模拟对接评分的可能性。Apache Spark实施的另一种迭代方法采用了与渐进式对接非常相似的策略,其中作者迭代地对接了大型虚拟筛选库中的配体集,形成逐渐变化的训练集,用于模型构建,并使用这些模型预测原始库中剩余配体的对接评分,以逐渐排除低评分分子并优先考虑高评分分子。
虽然早期研究表明使用简单的配体描述符计算对接评分是一个有趣的方向,但两到四倍加速在处理十亿或更多化合物的分子库时仍然不够。只有在深度学习方法出现后,这些方法才变得可行。2020年初,研究人员开发了一种利用深度QSAR建模加速超大化学库筛选的深度对接方法(图3)。深度对接结合了主动深度学习和简单的、与蛋白质无关的二维指纹化学描述符,特别适合于使用标准计算资源进行giga大小化学库的虚拟筛选。例如,深度对接使得可以使用仅60个CPU核心进行Glide对接和4个GPU核心进行深度神经网络训练,评估ZINC15数据库中的14亿化合物对SARS-CoV-2 Mpro的活性。ZINC15数据库的前1000个命中(对应于585个不同的化学框架)被公开,其中许多后来被独立确认为活性化合物。重要的是,该过程的快速性使得在世界卫生组织宣布COVID-19大流行的当天就能发布初步结果。
编译 | 曾全晨
审稿 | 王建民
参考资料
Tropsha, A., Isayev, O., Varnek, A. et al. Integrating QSAR modelling and deep learning in drug discovery: the emergence of deep QSAR. Nat Rev Drug Discov (2023).
https://doi.org/10.1038/s41573-023-00832-0
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-12-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号