LLM4vis:基于大模型的可解释可视化推荐方法


关注我们,一起学习
标题:LLM4Vis: Explainable Visualization Recommendation using ChatGPT 地址:https://arxiv.org/pdf/2310.07652.pdf 会议:EMNLP 2023 学校,公司:新加坡管理大学,微软亚洲研究院
1.导读
本文主要针对可解释可视化推荐任务提出的大模型相关方法LLMVis,现有的各种基于机器学习的方法通常需要大量的可视化对数据集(数据和标签)来进行训练,并且其结果缺乏可解释性。
简单解释下这里说的可视化推荐:为了增强可解释性,我们通常会采用可视化方法,比如折线图,点状图,柱状图等,而不同的数据适合的图不同,因此需要对数据进行判断来推荐合适的可视化方式,如果是人工筛选那会很低效。
在这里,作者提出了LLM4Vis,基于大模型LLM(如ChatGPT)的提示方法,用于执行可视化推荐,并使用很少的示例返回类似人类的解释。LLMVis包括特征描述、示范示例选择、解释生成、示范示例构建和推理。为了获得具有高质量解释的示例,本文提出了一种解释生成bootstrapping方法,通过考虑上一轮迭代结果和基于模板的提示来迭代细化生成的解释。
- 特征描述:将包含单个特征和交叉特征的表格数据转化为自然语言描述的形式
- 示例选择:由于LLM的输入长度有限,因此只能选择少量的数据,这里的数据用于上下文学习,选择的方式为聚类
- 解释生成:通过上述方式只有特征描述和选择出来的特征,但是对应的解释,这里的解释通过大模型根据特征描述生成,这里的解释是为了增强推荐的可解释性,即为什么推荐某一类的可视化方法
具体流程可以看2.1节概览。
2.方法
2.1 概览
如图1所示,LLM4Vis由几个关键步骤组成:特征描述、演示示例选择、解释生成引导、提示构建和推理。
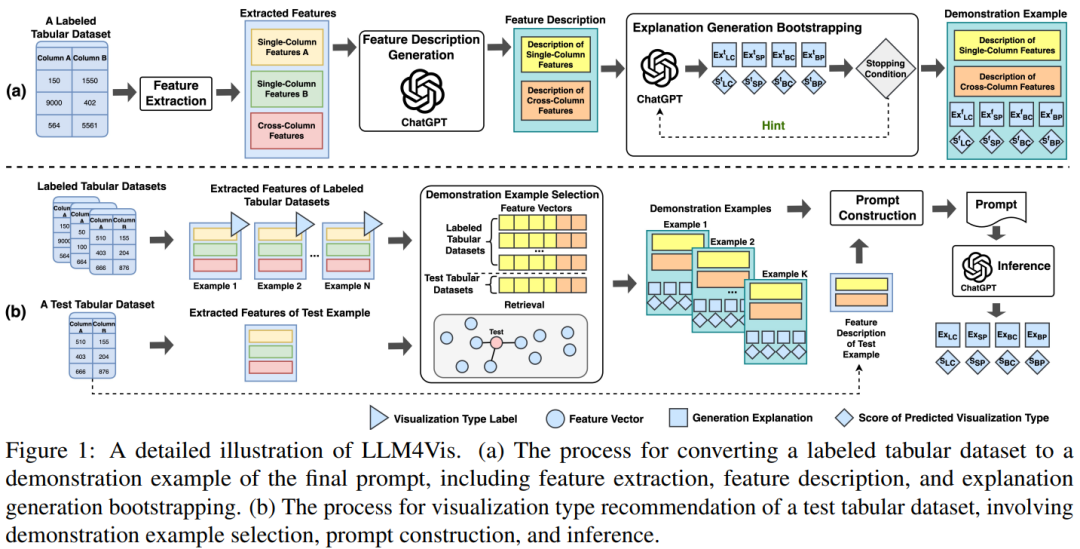
2.2 特征描述
大多数大型语言模型,如ChatGPT,都是基于文本语料库进行训练的。为了允许ChatGPT将表格数据集作为输入,
- 首先使用预定义的规则将其转换为定量表示其特征的数据特征集(感觉这里可以和人大的structgpt结合使用)。
- 然后,可以将这些特性序列化为文本描述。根据VizML和KG4Vis数据集,提取了80个交叉特征和120个单特征。将与列相关的数据特征分类为类型、值和名称。
以往的工作主要通过使用规则、模板或语言模型来执行序列化。在本文中,为了确保语法的正确性、灵活性和丰富性,遵循TabLLM提出的LLM序列化方法。提供一个提示,指示ChatGPT为每个表格数据集生成一个全面的文本描述,从单列特征和交叉特征的角度分析特征值。然后使用特征描述来构建简洁但信息丰富的演示示例。
2.3 示例选择
由于最大输入长度的限制,ChatGPT提示只能容纳少量的演示示例。因此,需要从大量标记数据中选择好的样本。
- 首先通过将每个表格数据集的特征转换为向量。
- 然后使用聚类算法从标记集中选择具有代表性的示例子集。聚类算法创建C个聚类,从每个聚类中选择R个有代表性的例子,得到大小为M=C×R的子集作为检索集。
- 最后基于检索集中向量表示的余弦相似性得分,检索与目标数据示例具有最高相似性得分的K个训练数据示例。
2.4 解释生成
每个标记的数据示例
只带有一个标签
,但没有演示示例中需要使用的解释。通过设计提示prompt,利用LLM,如ChatGPT的内置知识为每个样本生成适当的可视化和解释。指示ChatGPT以JSON格式生成,其中key对应于四种可能的可视化类型
(LC:折线图、SP:散点图、BC:条形图、BP:方框图),值为推荐分数
。提示ChatGPT在迭代过程中为其对每个可视化类型的预测生成解释
。
使用零样本提示和表格数据集的特征描述,要求ChatGPT为所有可视化类型生成分数
,并提供支持将这些分数分配给每个可视化类型的解释
。这些分数的总和要求为1。
随后,通过迭代细化过程来修改这些分数和解释,该迭代细化过程在真实标签Y上的打分最高,且超过第二高分数至少0.1时终止。最后的解释和分数用
和
表示。然而,如果真实的可视化类型不满足上述条件,作者开发了一个提示,并将其附加到初始零样本提示,以指示ChatGPT产生更准确的输出。提示模板示例如下:“{a}可能比{b}更合适。但是,以前的分数是{c}”。{a}槽用于基本事实标签,{b}槽用于具有最高分数的不正确标签,{c}槽用于每个可视化类型的先前预测分数。
2.3 提示构造和推理
在从测试数据样本的检索集中检索到K个最近的标记样本,以及它们的特征描述、精细解释和精细分数后,每个演示示例都由特征描述、任务说明、推荐的带分数的可视化类型和解释构成。然后,我们将测试数据示例的功能描述合并到预定义的模板中。接下来,构建的演示示例和测试数据示例的完整模板被连接起来,并输入到ChatGPT中,以执行可视化类型建议。最后,从ChatGPT输出中提取推荐的可视化和解释。
3.结果
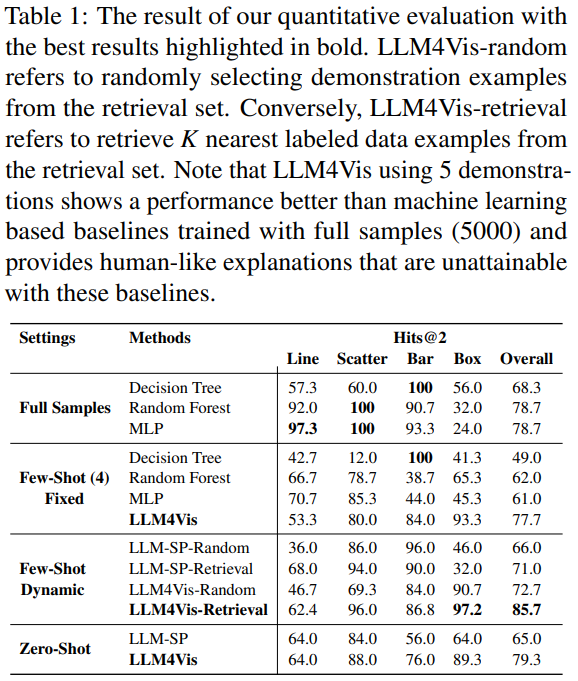
image.png
交流群:点击“联系作者”--备注“研究方向-公司或学校” 欢迎|论文宣传|合作交流 往期推荐 RecSys最佳短文 | 微信如何优化用户留存? 「StructGPT」面向结构化数据的大模型推理框架 用大模型LLM进行异构知识融合构建推荐系统 CIKM'23 | 统一的搜索推荐冷启动基础模型
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号