代码开源!用Versal FPGA加速矩阵乘法


该论文主要围绕着深度学习应用对密集矩阵乘法(Matrix Multiply, MM)的大量需求展开。随着深度学习模型的复杂度不断增加,对计算资源的需求也日益增长,这促使了异构架构的兴起,这类架构结合了FPGA(现场可编程门阵列)和专用ASIC(专用集成电路)加速器,旨在应对高计算需求。
AMD/Xilinx的Versal ACAP(自适应计算加速平台)架构是此类异构架构的一个实例,它集成了通用CPU核心、可编程逻辑以及针对AI/ML优化的AI引擎处理器。一个由400个运行在1GHz的AI引擎处理器组成的阵列可以提供高达6.4 TFLOPs的32位浮点运算性能。然而,机器学习模型中的MM操作既有大规模也有小规模的,大规模MM操作能够有效地并行处理,但小规模MM操作则通常无法做到这一点。研究发现,执行BERT自然语言处理模型中的某些小规模MM层,在Versal ACAP上大型、单一的MM加速器上只能达到理论峰值性能的不到5%。
因此,如何设计加速器以充分高效地利用计算资源成为一个关键问题,尤其是在面对不同规模MM操作时,需要平衡资源分配,避免计算和带宽的浪费。这驱动了对CHARM架构及其实现框架的研究,旨在通过组合异构加速器来解决这一挑战,从而提高整体系统效率,特别是在处理同时含有大、小MM操作的深度学习应用时。
论文还提到了一些相关的先前工作,包括针对特定应用定制的处理器设计、流线型线性代数运算在FPGA上的实现、高带宽内存基加速器设计、以及针对FPGA的高性能阵列编译器等。这些背景知识共同构成了CHARM架构提出的理论和技术基础。

作者回顾了神经网络(NN)加速器领域的现有研究和设计方法,特别是那些致力于提高密集矩阵乘法(MM)运算的吞吐量和能源效率的工作。
- 神经网络加速器的一般特性:
- 大多数NN加速器采用大量处理元素(PE)和相似的存储层次结构,包括本地内存和全局共享内存,以减少昂贵的离芯片数据移动。
- 许多早期的工作侧重于数据重用机会、计算并行性和数据流选择,以优化密集矩阵运算。
- 一揽子设计的局限性:
- 很多先前的研究采用“一刀切”(one-size-fits-all)的单一设计,这种设计在处理具有大幅差异的形状和大小的层时效率低下(如Eyeriss、ShiDianNao、NPU等)。
- AutoSA是一个基于多面体的编译框架,用于生成针对密集矩阵的单一设计的流水线阵列。
- Sextans和Serpens是针对稀疏矩阵的通用单一加速器。
- 有些工作如AMD DPU和Mocha探索了通过在设备上分配多个重复加速器的任务级并行性,但没有对每个加速器进行专门设计。
- 多种加速器设计的尝试:
- DNNBuilder为特定层设计了专用加速器。
- DNNExplorer通过结合前几层的专用加速器和剩余层的单一设计,增强了DNNBuilder,但缺乏全面的工作负载分配探索。
- TETRIS和TANGRAM在神经网络各层内和跨层提出了多种数据流优化,提高了性能和能效,但缺乏高总体吞吐量下的设计空间探索(DSE)和工作负载分配。
- Herald提出了具有多个多样化加速器的架构,并探索了工作负载分配和资源划分,但选择了几个现有设计,如ShiDianNao和NVDLA,而没有为每个加速器做设计空间探索。
- CHARM与先前工作的比较:
- CHARM能够从单一、多个重复或多个多样化的加速器中做出选择,并且每个加速器都是针对不同的工作负载分配、数据流和数据并行策略进行专门设计的。
- 与先前的工作相比,CHARM涵盖了全面的设计空间探索,以实现高整体吞吐量。
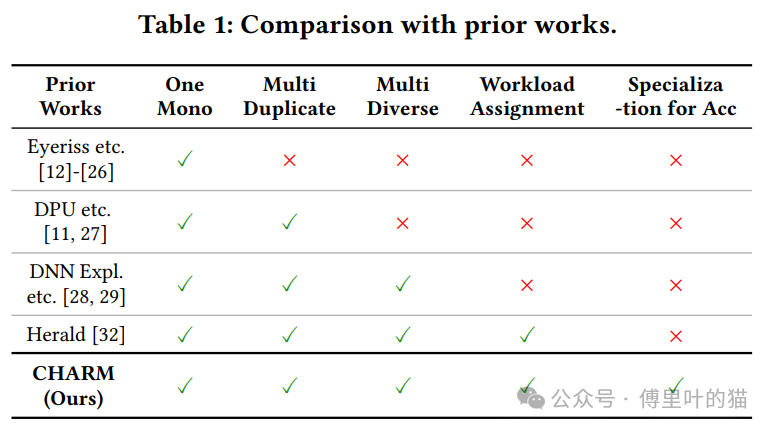
Versal ACAP架构概述:
- Versal ACAP(Adaptive Compute Acceleration Platform)是一个高度集成的异构系统,包含AI Engine(AIE)阵列、ARM处理器和可编程逻辑(PL),旨在提供高度可配置和可适应的计算能力。
- VCK190评估板是Versal ACAP的一个实例,它集成了第一代AIE架构,具备8行50列的1GHz 7路VLIW处理器,支持高达1024位的向量运算。
- ARM处理器用于运行Linux和其他一般应用程序。
- 可编程逻辑(PL)允许设计特定应用的硬件,包括集成的数字信号处理器(DSP)。
- AIE核和ARM CPU可以使用C/C++编程,而PL可以通过RTL和C/C++代码利用High-Level Synthesis(HLS)进行编程。
- 这些组件通过I/O外设如PCIe、USB等与外部世界通信。
- AIE阵列通过AXI-Stream(AXIS)交换网络连接,支持电路交换和分组交换,提供确定性和动态路由的数据传输能力。
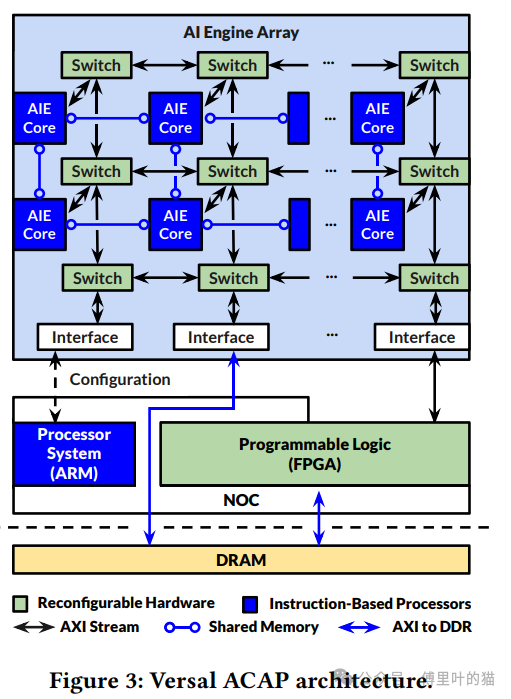
- AIE内存模型:
- 每个AIE处理器磁贴包含32KB的数据内存,能够与相邻的AIE进行数据共享。
- AIE磁贴除了与邻近磁贴共享本地内存之外,还通过AXIS交换网络与非本地AIE处理器和PL进行通信。
- VCK190板提供了从PL到AIEs和从AIEs到PL之间的高带宽连接,分别是1.2TB/s和0.9TB/s,比DDR4和PL之间的带宽高出46倍。
- AXIS交换机支持电路交换和分组交换连接,其中电路交换提供专用、确定性的通信,而分组交换则允许数据动态路由至不同目的地。
- 整体架构:
- Versal ACAP架构集成了DRAM控制器,形成一个包含网络在芯片(NoC)的异构SoC。
- VCK190板配备了一个DDR4-DIMM离芯片内存,峰值带宽为25.6GB/s。
作者又详细描述了如何在Versal ACAP架构上设计单个矩阵乘法加速器,并针对数据流和映射策略进行了阐述。以下是该部分内容的总结:
- 数据流和映射策略:
- 作者提出了一个矩阵乘法加速器的设计方法,该方法利用了数百个AI Engine (AIE)单元,通过精心规划数据流动和计算资源的分配,实现高效的密集矩阵乘法。
- 数据重用优化是设计的关键,以平衡计算和通信的需求,确保在有限的离芯片带宽下,加速器可以维持高计算效率。
- 数据重用优化:
- 通过增加片上存储来提高数据重用率,减少离芯片通信的总数据量,从而减轻离芯片带宽的压力。根据文献分析,矩阵乘法中的离芯片通信量与片上数据块大小的平方根成反比。
- 在Versal ACAP架构上,研究者使用了384个AIE和超过80%的片上统一RAM (URAM) 和块RAM (BRAM) 资源,构建了一个矩阵乘法加速器。
- 这个设计在1536×128×1024的原生数据块大小上运行,处理大型方阵矩阵乘法时可以达到2.8 TFLOPs的吞吐量。
- 然而,当映射不同大小的矩阵乘法到同一设计时,若矩阵尺寸小于512,性能会显著下降,因为每个数据块被填充到加速器的原生大小,导致计算和带宽的浪费。
- 多加速器方法:
- 作为一种替代方案,研究者探讨了实现多个具有较小原生数据块大小的加速器,每个加速器可以并行执行不同的任务。使用8个独立加速器,每个具有256×128×256的原生数据块大小,对于64大小的小型方阵矩阵乘法,这种方法可以在点C处达到7.2 GFLOPS的速度,相比于点B有大约17倍的加速。
- 然而,这种方法在处理大型矩阵乘法时,数据重用率降低,总体吞吐量几乎饱和。
- 设计挑战与解决方案:
- 实验揭示了两种相互冲突的设计目标:一方面要高效实现大型矩阵乘法,另一方面要最小化小型矩阵乘法的计算和通信开销。
- 为了在实际应用中同时实现这两点,研究者提出了一种设计思路,即为大型矩阵乘法分配更多资源,同时为小型矩阵乘法分配较少资源,从而在时间线上同时计算。
通过上述设计和优化,CHARM旨在解决Versal ACAP架构上密集矩阵乘法加速器的效率和资源分配问题,尤其关注于处理大小不一的矩阵乘法操作,以提高整体系统性能。
CHARM Architecture
- 目标:
- 设计一个系统,它能够在处理各种规模的MM操作时,同时优化计算和通信效率,特别是在处理大型和小型MM操作共存的深度学习应用中。
- 设计思想:
- 提出一种方法,即为大型MM操作分配更多资源,同时为小型MM操作分配较少资源,通过这种方式同时计算,以减少计算和带宽的浪费。
- 实现:
- 构建了一个包含多个加速器的系统,其中每个加速器都有不同的原生数据块大小,以适应不同规模的MM操作。例如,大型MM操作使用较大的加速器,而小型MM操作则使用较小的加速器。
CHARM Framework
- 组成部分:
- CHARM框架包含多个模块,如CHARM Diverse Accelerator Composer (CDAC)、CHARM Automatic Code Generation (CACG)和CHARM Runtime System (CRTS)。
- 功能:
- CDAC:使用基于排序的两步搜索算法来寻找最优的CHARM设计,使得在多项式时间复杂度内完成设计空间探索,而不是指数时间复杂度。
- CACG:自动生成AIE、PL和主机CPU的源代码文件,以简化系统实现过程。
- CRTS:在主机CPU中运行,负责调度不同任务的内核到各个加速器上,以优化任务延迟和整体系统吞吐量。
- 创新点:
- 提供了详细的系统化数据移动和计算分析,特别是在Versal ACAP架构上。
- 自动化代码生成和运行时系统,简化了开发流程,提高了效率。
- 结果:
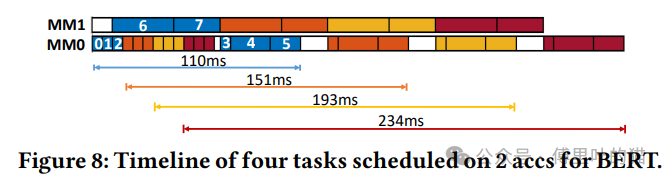
- 通过在VCK190板上部署CHARM框架,加速了包括BERT、ViT、NCF和MLP在内的四个应用,实现了显著的吞吐量提升,相较于单一加速器设计,获得了倍数级别的性能增益。
论文结果总结
- CHARM架构的有效性:
- CHARM架构成功地解决了大型和小型矩阵乘法操作在Versal ACAP架构上的效率问题,通过设计多样化的加速器,每个加速器针对特定规模的矩阵乘法进行了优化。
- 性能提升:
- 实验结果表明,与单一的大型加速器设计相比,CHARM在处理BERT、ViT、NCF和MLP等多个深度学习应用时,能够显著提高总体吞吐量,分别实现了1.46 TFLOPs、1.61 TFLOPs、1.74 TFLOPs和2.94 TFLOPs的推断吞吐量,性能提升分别达到了5.29倍、32.51倍、1.00倍和1.00倍。
- 资源和带宽优化:
- 通过资源分配和数据流优化,CHARM能够最大化每个加速器的计算效率,减少计算和带宽的浪费,尤其是对于小型矩阵乘法。
- 自动化工具和框架:
- 提供了包括CHARM DSE(Design Space Exploration)、CHARM多样化的加速器组合器(CDAC)、CHARM自动代码生成(CACG)和CHARM运行时系统(CRTS)在内的自动化工具和框架,大大简化了系统设计和实现过程。
- 开源工具和透明度:
- CHARM团队开源了所有工具和代码,提供了详细的步骤指南,使其他研究人员和开发者能够轻松地重现研究结果和学习CHARM的设计理念,促进学术界和工业界的交流与合作。

这篇论文中的代码也在GitHub上开源了,网址为:
https://github.com/arc-research-lab/CHARM/tree/main
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号