Magiclens:新一代图像搜索技术及产品形态

Magiclens:新一代图像搜索技术及产品形态

用户3578099
发布于 2024-05-27 21:21:33
发布于 2024-05-27 21:21:33
MagicLens:Self-Supervised Image Retrieval with Open-Ended Instructions
MagicLens: 自监督图像检索与开放式指令
- 作者:Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, Ming-Wei Chang
- 单位:Google
- 官网地址:https://open-vision-language.github.io/MagicLens
- 论文地址:https://arxiv.org/abs/2403.19651
- Benchmark:https://mmmu-benchmark.github.io
“MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions” 是一项关于图像检索的新研究。这项研究的核心在于,通过使用大型多模态模型和大型语言模型,能够将图像对中的隐含关系(如网页上的"内部视图")显式化。MagicLens 是一种自监督的图像检索模型,支持开放式指令。这些模型基于一个关键的新见解:自然出现在同一网页上的图像对包含广泛的隐含关系,并且可以通过合成指令来使这些关系明确化。
MagicLens 在 36.7M 个(查询图像、指令、目标图像)三元组上进行训练,这些三元组是从网页中挖掘的,包含了丰富的语义关系。这些模型在多个图像检索任务基准测试中实现了与之前最先进(SOTA)方法可比或更好的结果,并且在多个基准测试中以 50 倍更小的模型大小超越了之前的 SOTA 方法。此外,MagicLens 能够满足由开放式指令表达的多样化搜索意图。
在数据构建方面,MagicLens 利用大型多模态模型和大型语言模型来构建高质量的三元组(查询图像、文本指令、目标图像)用于模型训练。模型训练方面,MagicLens 基于单模态编码器,这些编码器是从 CLIP 或 CoCa 初始化的,并使用简单的对比损失进行训练。具有双编码器架构的 MagicLens 能够同时处理图像和文本输入,以提供 VL 嵌入,从而实现多模态到图像和图像到图像的检索。此外,底部的单模态编码器可以重新用于文本到图像的检索,获得性能提升。
MagicLens 展示了文本指令能够使图像检索具有更丰富的关系,超出了视觉相似性。这项研究证明了即使在模型大小大幅缩小的情况下,文本指令仍然能够提高图像检索的效果。
该项工作的效果确实挺好,在工程应用方面也具有极高的实践价值,目前尚未开源。这里先详细阅读一下该工作的论文全文。
摘要
图像检索,即给定参考图像寻找所需图像,本质上包含了丰富的、多方面的搜索意图,这些意图仅通过基于图像的度量难以捕获。最近的工作利用文本指令让用户更自由地表达他们的搜索意图。然而,现有工作主要关注的是视觉上相似的图像对以及可以由一组预定义关系描述的图像对。本文的核心论点是,文本指令可以使检索到的图像具有超越视觉相似性的更丰富的关系。为了展示这一点,引入了MagicLens,这是一系列支持开放式指令的自监督图像检索模型。MagicLens建立在一个关键的新见解上:自然出现在同一网页上的图像对包含广泛的隐含关系(例如,内部视图),可以通过大型多模态模型(LMMs)和大型语言模型(LLMs)合成指令来使这些隐含关系明确化。在从网页中挖掘的包含丰富语义关系的三元组(查询图像、指令、目标图像)上进行训练,MagicLens在八个不同图像检索任务基准测试上取得了与先前最先进(SOTA)方法可比或更好的结果。值得注意的是,它在多个基准测试上以50倍更小的模型大小超越了之前的SOTA。此外,对一个未见过的140万图像数据集进行的实验进一步证明了MagicLens支持的搜索意图的多样性。
引言
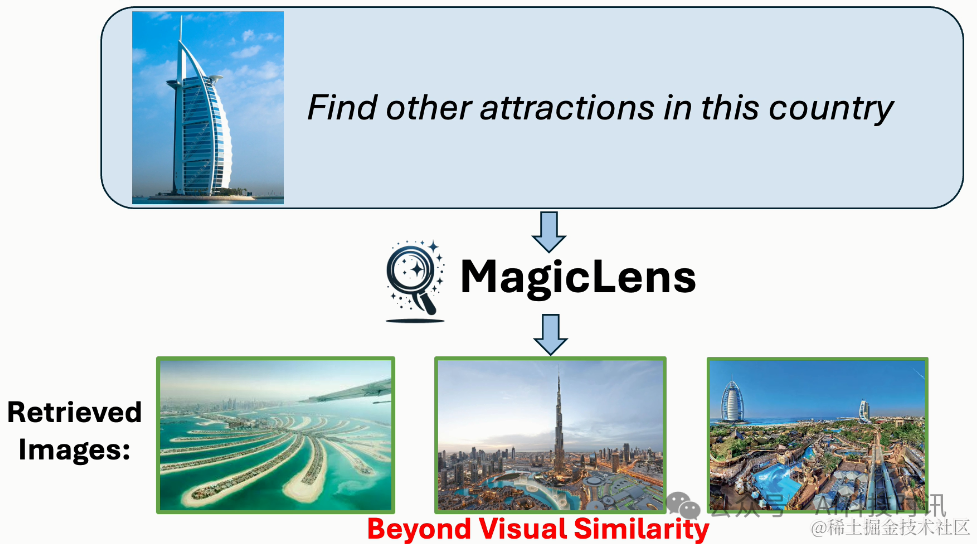
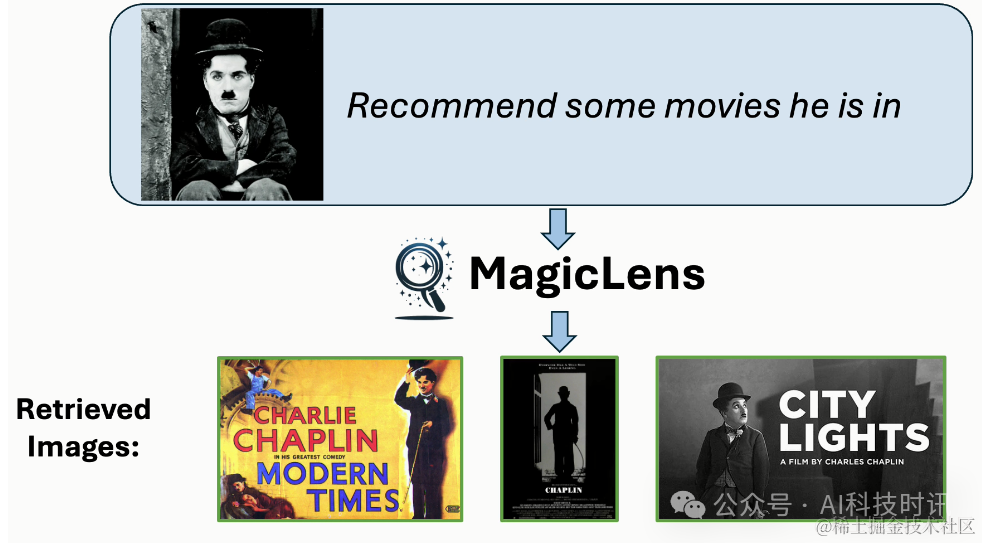
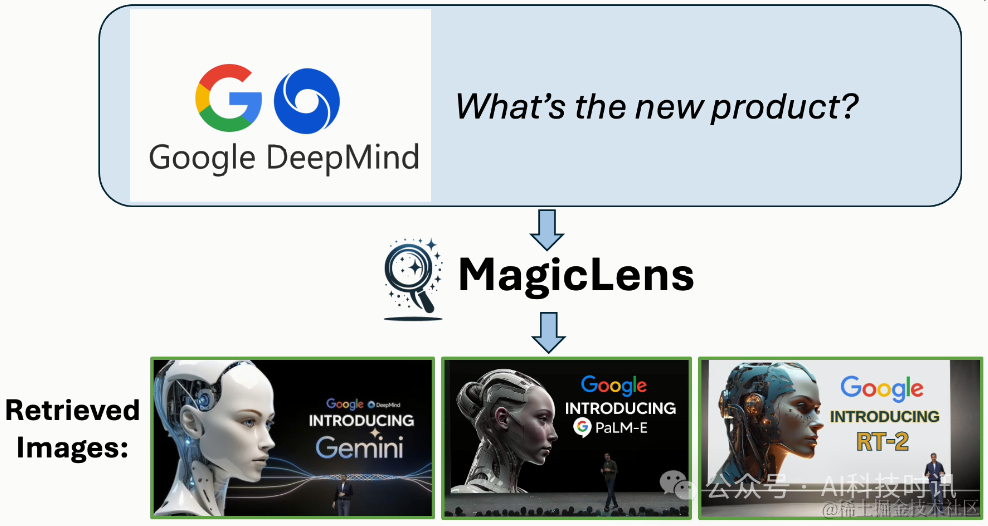
图像检索是计算机视觉领域的一个长期存在的问题(Datta等人,2008年;Gordo等人,2016年),具有广泛的现实世界应用,如视觉搜索、目标定位和重新识别。然而,自其诞生以来,这个任务就因为图像中封装的复杂和丰富的内容而受到定义模糊的困扰。相似的图像可能在关键方面有所不同,而不同的图像可以有共同点。在图像搜索场景中,用户经常为单个查询图像呈现多个搜索意图,表明仅凭图像相关性不足以获得精确的搜索结果。例如,当用迪拜的Burj Al Arab酒店的图像进行搜索时(见图1),用户可能寻找迪拜的其他景点或内部视图,每个都与查询图像有不同关系。因此,将表达搜索意图的文本指令融入其中对于提高检索精度至关重要,也是不可或缺的。理想情况下,模型应该准确捕捉和解释由开放式文本指令传达的多样化的现实世界搜索意图。
这些开放式搜索指令涵盖广泛的主题和概念,反映了用户与视觉内容互动的多样方式,要求检索系统不仅要掌握图像的视觉特征,还要掌握查询图像与期望结果之间在指令中表达的细微语义关系。然而,现有的模型要么针对一个或几个受限领域进行优化(Vo等人,2019年;Wu等人,2021年;Liu等人,2023年;Baldrati等人,2023年),其中视觉相似性的类型是作为先验手动定义的,要么调整模型架构和训练方案以利用图像-字幕数据(Chen和Lai,2023年;Saito等人,2023年;Baldrati等人,2023年;Gu等人,2024年),或者依赖从预定义指令模板构建的合成数据(Brooks等人,2023年;Gu等人,2023年)。因此,这两种研究方向都无法有效建模开放式指令,正如图1所示。

图1. 使用MagicLens和先前最先进(SOTA)方法(Gu等人,2024年)从包含140万张图像的检索池中检索到的第一张图像。尽管先前SOTA方法接受文本指令,但它主要基于查询图像的视觉相似性进行检索,忽略了文本指令的细微差别。相比之下,MagicLens在检索视觉上相似的图像以及与文本指令的更深层含义和上下文相符的图像方面表现出色——即使这些图像与查询图像不相似。例如,如果给定迪拜的Burj Al Arab酒店的查询图像和指令“在这个国家寻找其他景点”,MagicLens可以成功定位迪拜棕榈岛的图像
在这篇论文中,我们介绍了MagicLens,这是一系列在广泛的(查询图像、指令、目标图像)三元组上进行训练的自监督图像检索模型,这些三元组反映了从网页中挖掘的自然语义关系,并且使用了最先进的(SOTA)基础模型进行筛选。具体来说,从同一网页上自然出现的图像对中提取图像对,形成包含丰富但自然的语义关系的正对。然后,应用大型多模态模型(Chen等人,2023b;a)和大型语言模型(Anil等人,2023年)来细化这些开放式语义关系的描述,形成开放式指令。图2展示了数据构建流程的概述。作为具体例子,一个展示尼康相机图像和尼康充电器图像的相机评论网站可能会提供一种有趣且非琐碎的关系“产品的充电器”,然后通过LMM+LLM管道进行筛选,并产生最终指令“寻找它的充电器”。这个过程产生了描绘超越单纯视觉相似性的多样化语义关系的开放式指令,结果是一个包含36.7M高质量三元组的大规模训练数据集,覆盖了广泛的分布。

图2. 数据构建的概述。收集了同一网页上自然出现的图像对,并使用PaLI+PaLM2来生成连接这两幅图像的指令
使用构建的数据集,训练了名为MagicLens的双编码器模型,这些模型根据由图像和指令组成的查询来检索图像。模型在八个基准测试上取得了与先前最先进(SOTA)方法可比或更好的结果,这些基准测试包括各种多模态到图像和图像到图像的检索任务。此外,MagicLens可以保留甚至显著提高底层单模态编码器的文本到图像检索性能。与先前SOTA方法相比,MagicLens的模型大小小了50倍,在多个基准测试上取得了更好的成绩:CIRCO(Baldrati等人,2023年)、Domain Transfer ImageNet(Saito等人,2023年)和GeneCIS(Vaze等人,2023年)。为了进一步检验模型在更现实场景中的能力,构建了迄今为止最大的检索池,包含140万未见过的图像,并使用人类编写的具有多样化指令的搜索查询进行检索。人类评估发现,MagicLens可以成功满足复杂且超越视觉搜索意图的需求,而先前SOTA方法则无法做到这一点。
本文贡献主要有三个方面:
- 为图像检索带来了新的见解:来自同一网页的自然出现的图像对是强大的自监督训练信号。基于此,提出了一种有效的方法,利用LMMs和LLMs,构建了包含36.7M三元组的训练数据。
- 引入了MagicLens,这是一系列轻量级双编码器,它们共同嵌入图像和指令对,并在构建的数据集上进行训练。在多个基准测试中,MagicLens超过了先前最先进(SOTA)方法,但模型大小只有其50分之一。
- 对一个140万规模的数据集进行了深入的人类评估和分析,这是迄今为止规模最大的。令人印象深刻的高成功率表明,MagicLens能够很好地捕捉和满足多样化的搜索意图,尤其是复杂和超越视觉意图。
相关工作
预训练多模态编码器。多模态编码器预训练(Faghri等人,2017年;Chen等人,2021年;Radford等人,2021年;Yu等人,2022年;Li等人,2021年;Kim等人,2021年;Wang等人,2023年;Li等人,2022年;2023年;Cherti等人,2023年)近年来取得了巨大成功。这些模型在大规模图像-字幕数据(Zhai等人,2022年;Schuhmann等人,2022年)上进行预训练,将不同模态的表示对齐到联合空间中,实现了零样本跨模态检索。然而,这些工作主要关注编码单个模态,而没有考虑多个模态组合表示。一些后来的工作(Hu等人,2023a;Chen等人,2023c;Wei等人,2023年)试图通过在预训练的单模态编码器顶部微调少量参数来结合文本和图像嵌入,而没有大规模联合预训练。因此,这种适应策略在对我们感兴趣的任务上的表现较差,强调了MagicLens自监督训练的重要性。
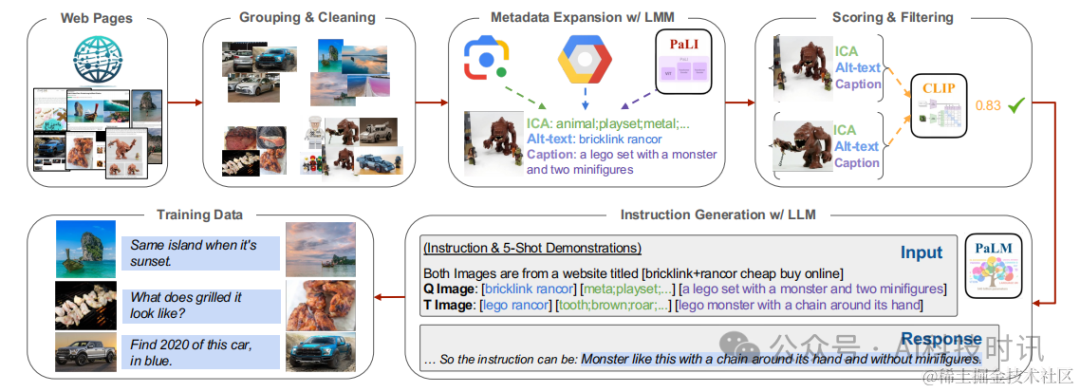
图3. 数据构建流程。通过以下步骤从网页中挖掘图像对:
- (1)将同一网页上的图像分组并清理;
- (2)使用LMM为每张图像标注元数据;
- (3)对不合格的图像对进行评分和过滤;
- (4)使用LLM为剩余的图像对生成开放式指令;
组合图像检索。组合图像检索(CIR;Vo等人,2019年)与我们的任务形式相同。然而,所有现有的基准测试(Liu等人,2021年;Baldrati等人,2023年;Wu等人,2021年)都是首先收集视觉上相似的图像,然后为图像对编写指令。这限制了这些基准测试上图像关系的丰富性以及基于/为它们开发的模型的丰富性。最近的零样本CIR工作要么设计轻量级的模态转换,要么调整训练和模型以使用现有的图像-字幕数据(Saito等人,2023年;Baldrati等人,2023年;Gu等人,2024年)。CIReVL(Karthik等人,2024年)使用LLM和LMM即时进行CIR,限制了其效率。请参阅附录B以获取这些方法的更多细节。在构建训练数据方面,CompoDiff(Gu等人,2023年)使用LLM和图像生成模型合成18M三元组,遵循与Brooks等人(2023年)相同的流程。我们数据与他们数据的关键区别在于图像质量和图像关系。如图2所示,我们的数据来自同一网页上发现的自然图像对。因此,数据覆盖了广泛的分布上的开放式图像关系,包括视觉和非视觉关系。
带指令的检索。指令调整(Ouyang等人,2022年)使模型在检索文本内容(Su等人,2023年;Asai等人,2023年)和多模态内容(Wei等人,2023年)方面具有强大的跨域和零样本泛化能力。然而,先前的努力主要关注使用手动编写的指令作为实际查询的任务前缀,在百级基础上统一不同的检索任务。相比之下,本文的方法利用了百万级的指令,这些指令自然表达了用户的搜索意图。
MagicLens
自监督训练的数据构建
网页包含多模态上下文,涉及相关主题的交织文本和图像。通过共现从同一网页中提取的图像对通常暗示了图像与特定关系之间的关联。这涵盖了广泛的图像关系,范围从视觉相似性到更微妙的联系(例如,图2)。因此,这些自然出现的图像对为图像检索模型提供了优秀的自监督训练信号。基于这一见解,提出了一种系统的数据构建流程,用于从网页中挖掘图像对,并采用LLM生成开放式指令,明确传达每对图像内的图像关系。
从网页中挖掘图像对。
- (1) 组群与清理。从Common Crawl2收集所有具有相同URL的图像,作为同一网页上的图像组,用于可能的配对。由于简单的组群不可避免地引入了噪声图像,移除了重复的、低分辨率的和广告图像,以及高度重叠的组群,这导致了大量更密集且本质相连的图像组。
- (2) 元数据扩展。为了为后续的LLM提供大量元数据扩展的详细文本信息,为图像标注了Alt-texts、图像内容注释(ICA)标签和字幕。如果图像的Alt-texts不合格,将丢弃这些图像。对于ICA标签,为每张图像标注了如一般物体和活动等实体。对于图像字幕,采用最先进的LMM-PaLI(Chen等人,2023a)来生成字幕。每种类型的元数据都从不同的角度提供了关于图像的文本信息。更多细节请参阅附录A。
- (3) 评分与过滤。在获得带有广泛元数据的图像组之后,在同一组内配对图像,并使用相关性度量的组合来消除不合格的配对。使用CLIP图像到图像的评分来评估视觉相关性,以及文本到文本的评分来评估非视觉相关性。那些在两个方面得分都低的图像对被排除在考虑之外。为了避免重复图像和重复关系的过度采样,为每个组设置最多三对图像,从而确保训练数据中图像和关系的更均匀分布(见图5)。
开放式指令生成。有了高质量配对图像的信息丰富的元数据,LLM能够很好地理解图像内容(ICA和字幕)及其背景信息(Alt-text)。使用指令(Chung等人,2022年)、少样本演示(Brown等人,2020年)和链式思维提示(Wei等人,2022年)技术,PaLM2(Anil等人,2023年)生成连接配对图像(imageq, imaget)的开放式指令。图3展示了生成的指令,附录10显示了详细的提示和演示。最终,获得了36.7M三元组(
) 用于自监督图像检索训练。
MagicLens模型
模型设计。如图4所示,采用一个简单的双编码器架构,共享参数,并使用CoCa(Yu等人,2022年)或CLIP(Radford等人,2021年)初始化视觉和语言编码器。为了实现深度的模态集成,引入了多个自注意力层,并设计了一个单多头注意力池化器,将多模态输入压缩成一个单一的嵌入
,用于后续匹配。此外,由于检索目标仅包含图像而不包括伴随文本,使用空文本占位符“ ”将目标转换为多模态输入。用
表示多模态查询(
)的嵌入,用
表示目标(
, “ ”)的嵌入。考虑到效率,提出了MagicLens-B和MagicLens-L,分别使用基础和大型检查点进行初始化。
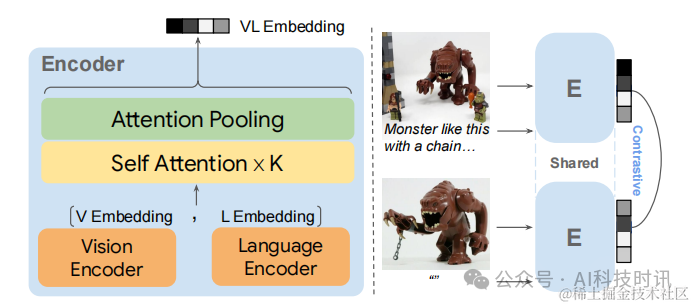
图4. MagicLens编码器(E)的模型架构和训练,它将视觉和语言嵌入作为序列输入到自注意力层中进行模态集成
模型训练。使用一个简单的对比损失来训练MagicLens,模型通过在训练批次中对比配对的查询-目标与其他目标来进行更新。特别是,由于查询图像本身(
)可以作为多模态查询(
)的具有挑战性的硬负样本,将查询图像本身和空文本组合起来编码(
)以得到
作为额外的查询负样本。为了增加负样本的数量,对于每个查询图像,使用同一批次中的所有查询负样本和其他目标负样本。正式地,对于第
个训练示例,损失函数
定义为:
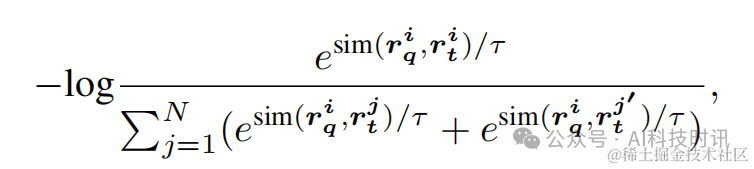
其中
表示余弦相似度函数,
,
指代采样的批次大小,
是对数缩放中的温度超参数。更多实现细节请参阅附录A。
实验
实验设置
基准测试和指标。为了全面评估MagicLens的多模态到图像检索能力,在零样本、一个检查点设置中考虑了三个相关任务:
- (1)组合图像检索(CIR)
- (2)领域迁移检索
- (3)条件图像相似性
每个任务都有不同的但有限的图像关系集合。表2显示了五个基准测试的详细统计数据。

表2. 五个评估基准测试的统计数据。平均了子任务(例如,FIQ)中的查询数量。# Index代表所有查询共享的检索池的大小,# Subset Index是每个查询专用的子集的平均大小
组合图像检索。考虑了一个领域特定的基准和一个开放域基准,以评估模型的领域适应性和其在真实世界自然图像上的能力。FIQ(Wu等人,2021年)是一个时尚领域的基准,包含三个独立的检索子任务:连衣裙、衬衫和T恤。遵循之前的工作(Saito等人,2023年;Baldrati等人,2023年;Gu等人,2024年),在其验证集上进行评估,并报告子任务平均召回率。CIRR(Liu等人,2021年)是第一个基于自然图像(Suhr等人,2019年)构建的数据集,其中查询图像和目标图像之间有九个预定义的关系。它还设计了一个子集检索设置,其中模型从每个查询的专用小子集中检索目标图像。然而,除了检索池的大小有限外,它还受到假阴性问题的困扰,正如Baldrati等人(2023年)所指出的。使用召回率(R和Rs)来评估标准检索和子集检索。相比之下,为了更好地与现实世界的大规模检索对齐,CIRCO为每个查询标注了多个真值,并使用超过120K的自然图像(Lin等人,2014年)作为索引集。因此,视CIRCO为主要的基准。由于每个查询都有多个目标,采用平均平均精度(mAP)作为评估指标。
领域迁移检索。域迁移ImageNet(DTIN;Saito等人,2023年)旨在从另一个域中检索与查询图像中显示的相同概念对象相关的图像。它由ImageNet(Deng等人,2009年)中的自然图像和ImageNet-R(Hendrycks等人,2021年)中的其他域中的图像构建而成。例如,**给定一个域关键词“卡通”和一个真实马的图像作为查询,模型期望从多个域的索引集中检索到卡通马的图像。**它覆盖了4个域、10K个对象和超过16K张图像作为索引集。遵循先前的工作(Saito等人,2023年;Karthik等人,2024年),报告子任务平均召回率。
条件图像相似性。GeneCIS(Vaze等人,2023年)是一个关键词条件下的图像相似度测量基准。它有四个子任务,涉及改变或聚焦给定图像的属性或对象。对于每个查询图像和关键词,模型需要从平均有13.8张图像的专用小子集中找到与查询图像最相似的图像,条件是给定的关键词。例如,在带有关键词“汽车”和一张图像的变化-对象子任务中,模型需要找到另一张图像,但其中包含额外的汽车。
Baseline基线。考虑了几个基线:(1)PALARVA(Cohen等人,2022年),(2)Pic2Word(Saito等人,2023年),(3)SEARLE(Baldrati等人,2023年),(4)ContextI2W(Tang等人,2024年),(5)LinCIR(Gu等人,2024年),(6)CIReVL(Karthik等人,2024年)(7)CompoDiff(Gu等人,2023年)和(8)PLI(Chen & Lai,2023年)。这些方法的详细描述见附录B。
多模态到图像检索
表1显示了三个任务在五个基准测试上的结果,从中可以得出以下观察结果:
- 首先,在可比的模型大小下,基于CLIP和CoCa的MagicLens在四个开放域基准测试上大幅超越了先前最先进模型,尤其是CoCa基础的MagicLens-L在具有挑战性的CIRCO(mAP@5从12.6提高到34.1)和DTIN(R@10从12.9提高到48.2)上的表现,这显示了MagicLens的强大能力。在附录C中提供了完整结果,并在第5.2节中进行了详细的参数效率分析。
- 其次,通过比较MagicLens-L和MagicLens-B,发现在五个基准测试上普遍存在性能提升。这表明构建的数据质量很高,可以受益于更大的模型。此外,这一观察结果还显示了得益于简单双编码器模型架构和对比损失的可扩展性。
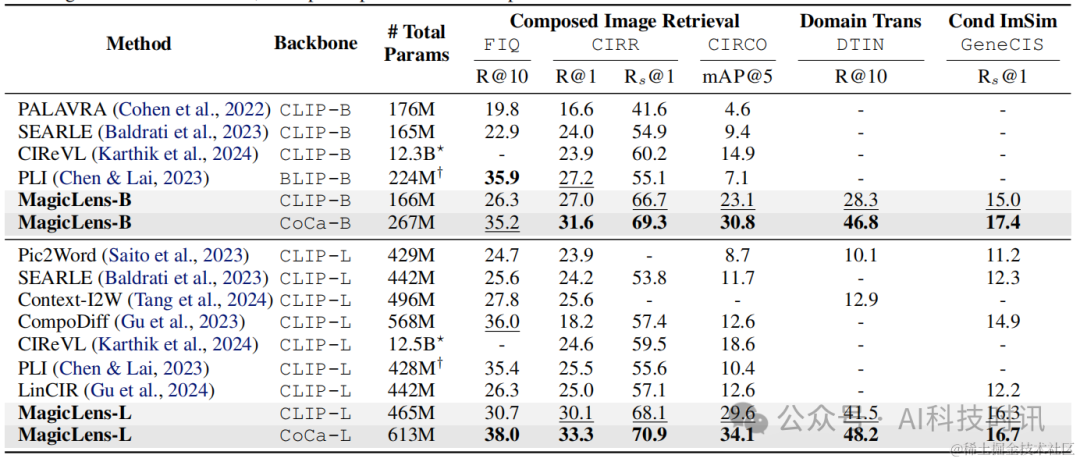
表1. 在三个多模态到图像检索任务上的五个基准测试上的性能比较。基线的成果来自原始论文。在最佳结果上使用粗体标记,在第二佳结果下划线。⋆CIReVL使用包括ChatGPT在内的多个模型组件进行检索,报告了已知大小的组件的参数数量。†PLI没有发布代码,所以只进行了估计
图像到图像检索
尽管MagicLens模型是针对
任务格式进行训练的,但它们可以通过为所有
提供固定的文本指令自然地覆盖
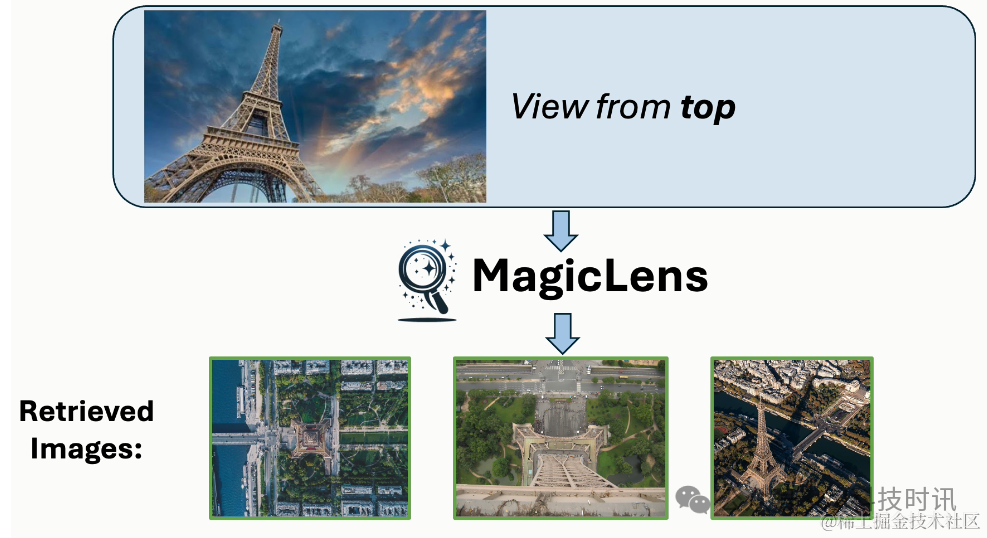
任务。作为一个案例研究,考虑了零样本素描基础图像检索(ZS-SBIR)任务,其中模型需要根据素描检索自然图像。简单地为所有查询图像使用“找到它的自然图像”指令,MagicLens可以执行这样的任务。
遵循这个领域之前的零样本SOTA方法(Liu等人,2019年;Lin等人,2023年),考虑了三个基准测试,分别是TU-Berlin(Zhang等人,2016年)、Sketchy(Yelamarthi等人,2018年)和QuickDraw(Dey等人,2019年)。
- TU-Berlin包含30个类别、2,400个素描查询和27,989张自然图像作为索引集;
- Sketchy包含21个在ImageNet-1K中未见的类别和12,694个查询,索引集包含12,553张自然图像
- QuickDraw包含30个类别、92,291个查询和54,146个大小的索引集。
对于每个数据集,都报告了先前SOTA工作(Lin等人,2023年)中使用的mAP和精度指标。
值得注意的是,与之前使用针对每个数据集单独训练的检查点并在上述保留测试集上进行评估的零样本方法不同,在所有基准测试上使用相同的检查点进行评估。结果报告在表4中,可以发现本文提出的模型在保持单一检查点设置的情况下显著优于先前的SOTA方法,这展示了MagicLens模型的强大泛化能力和它们能够覆盖的多样性任务。
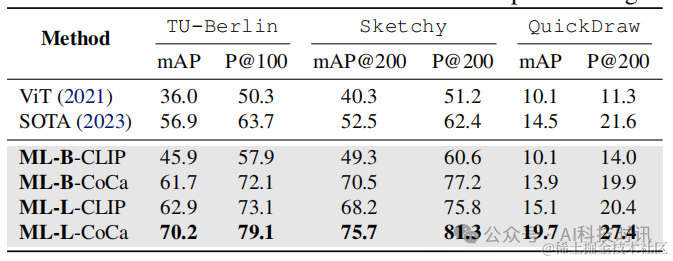
表4. 在三个图像到图像检索基准测试上的结果。基线的成果来自Lin等人(2023年),每个基准测试使用单独的检查点,而MagicLens(ML)模型在单一检查点设置下跨基准测试进行评估
文本到图像检索
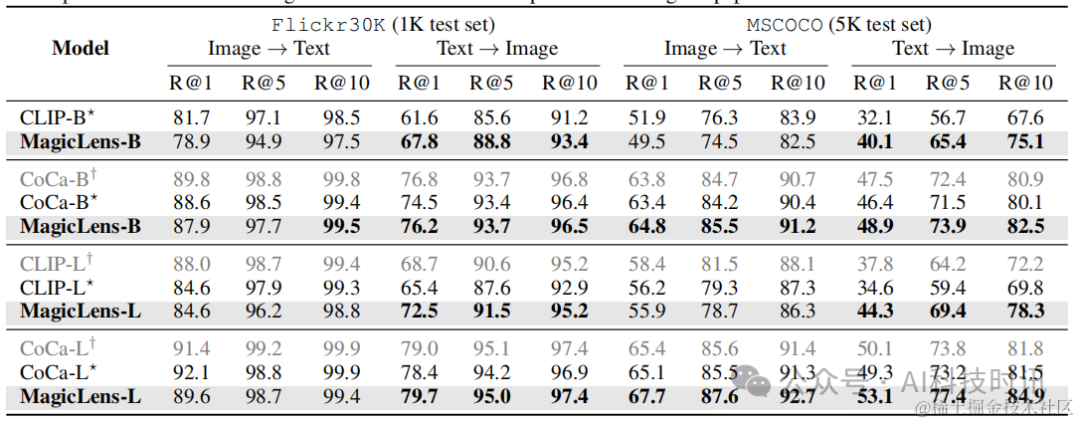
由于MagicLens模型基于视觉和语言编码器构建,这些编码器在训练后仍然可以用于图像→文本和文本→图像检索任务。因此,在Flickr30k(Plummer等人,2015年)和MSCOCO(Chen等人,2015年)上评估MagicLens的编码器,使用与先前工作(Radford等人,2021年;Yu等人,2022年)相同的数据集划分和评估指标。
表3显示了原始编码器与经过MagicLens训练更新的编码器之间的比较。对于文本→图像任务,可以观察到在两个数据集上所有指标的一致性和非琐碎的改进。对于图像→文本任务,观察到轻微的下降。这些观察结果表明,本文的训练方案可以增强文本到图像检索的编码器,也可以得出同样的结论关于CLIP,详细见表17。改进可能源于多模态到图像训练任务需要深入理解文本指令,从而改善了语言编码器。这些文本到图像的结果表明,MagicLens可以成功处理三种图像检索任务形式,并取得了所有强结果,考虑到上述其他任务的表现。
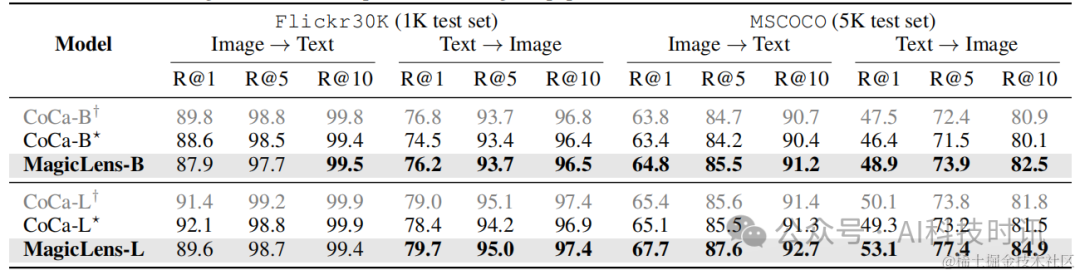
表3. 零样本图像-文本检索结果。如果它们比初始化检查点更好,则结果用粗体标记。⋆CoCa重新制作并用于MagicLens。†CoCa在原始论文中报告
分析
数据分析
与现有训练数据的比较。先前的数据构建方法,包括CompoDiff(Gu等人,2023年)和InstructPix2Pix(IP2P;Brooks等人,2023年),使用合成的图像对和本质上基于模板的指令来训练图像检索模型。考虑到数据可用性和CompoDiff采用与IP2P类似的创建流程,本文使用IP2P数据作为基线,探索不同训练数据对下游模型的影响。将一个基于CoCa的MagicLens-B模型,该模型在所有IP2P数据(1M)上训练,与一个在相同大小的下采样数据上训练的模型进行比较,使用相同的训练方案。表5显示,MagicLens + Ours在所有五个基准测试上均优于使用IP2P数据的其变体(MagicLens + IP2P)。这证明了我们的数据,包括自然图像和无模板指令,可以实现更强大的图像检索模型。详细比较请参阅附录C。

图5. IP2P数据和我们的数据的Word分布
此外,将这两种模型与IP2P训练的CompoDiff进行比较,CompoDiff是一种专门为使用合成图像设计的检索模型。尽管CompoDiff具有特定的设计,但MagicLens + IP2P仍然优于CompoDiff + IP2P。此外,它在CIRCO、DTIN和GeneCIS上的结果优于先前可比大小的SOTA基线。这表明了我们的训练方案的优势,因为模型即使在使用次优数据训练时也能取得相当不错的结果。
为了提供更多见解,在图5中分别可视化了IP2P和我们的数据中的指令词汇。正如所看到的,IP2P数据由于其基于模板的性质,具有大量如“turn”和“make”的指令关键词。此外,它还有很多“photograph”和“painting”这样的粗粒度关键词。相比之下,由于从一个网页中控制采样(如第3.1节所述),数据具有更多样化和均匀分布的关键词,覆盖了如“brand”这样的细粒度标签。
数据扩展。为了探究数据规模对模型的影响,在随机采样的0.2M、0.5M、1M、5M、10M、25M和整个36.7M三元组上训练CoCa-based MagicLens-B。五个基准测试及其平均性能的结果在图6中展示。随着数据大小的增加,MagicLens的平均性能得到提升,尤其是在达到10M之前。这表明了扩展数据的有效性。
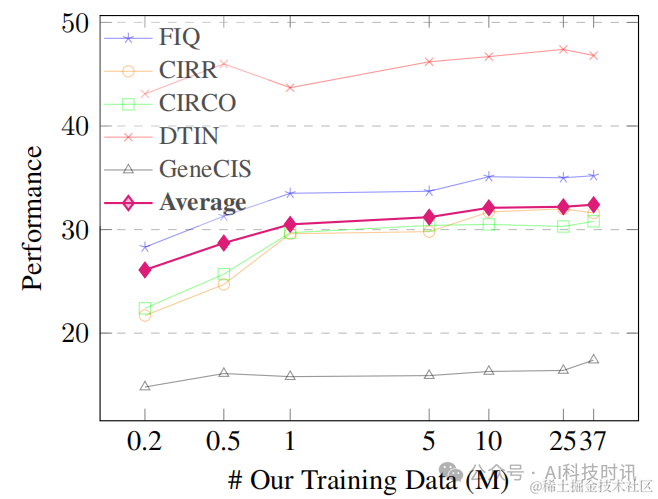
图6.基于coca的magiclen-b在不同大小的数据训练时的性能
训练期间指令的影响。之前工作中使用的指令(Brooks等人,2023年;Gu等人,2023年)是基于模板的,而我们的指令是无模板的。为了探究不同指令对下游模型的影响,也为在第3.1节中收集的自然出现的图像对合成基于模板的指令。具体来说,由于每张图像都有大量信息丰富的元数据,利用LLM确定关键元数据来填充预定义的句子结构。对于无模板指令,LLM被特别引导以生成多样且连贯的指令,不遵循任何固定的模板。在附录中的图10中展示了不同指令的具体例子。
表6比较了两个基于CoCa的MagicLens-B模型的性能。它们都使用1M三元组进行训练,使用相同的图像对,但上述提到的不同指令。无模板指令明显导致更强的模型,如在所有基准测试上相对于其他模型的结果一致更好所证明的。这表明自然表达和多样的指令可以更好地激发模型理解图像关系并遵循指令。

表6. 使用基于模板和无模板指令训练的CoCa-based MagicLens-B在1M规模的结果
模型分析
模型大小与性能。先前最先进的方法(Gu等人,2024年;2023年)考虑使用更大型的视觉和语言编码器(Cherti等人,2023年)或实时使用LMMs和LLMs(Karthik等人,2024年)以获得性能收益。然而,在实际部署中还应考虑模型大小和相关效率。在图7中,可视化了各种模型在GeneCIS、CIRCO和DTIN基准测试上的模型大小与性能之间的关系。
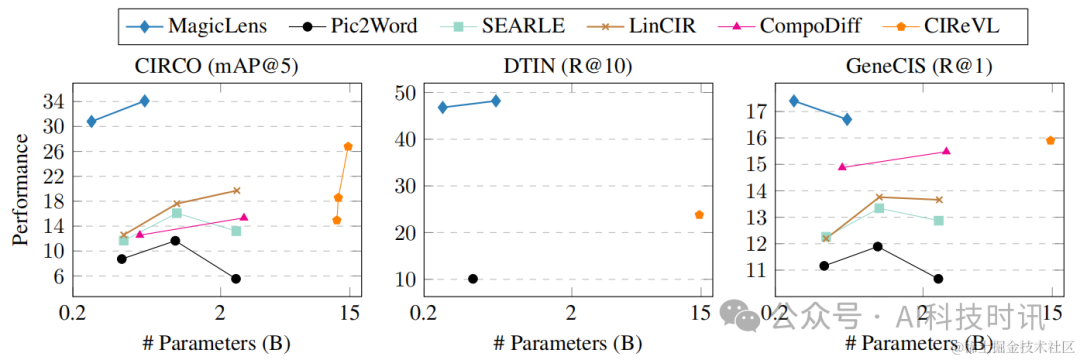
图7. 模型大小与性能。MagicLens-B在三个任务上优于SOTA CIReVL,即使模型大小小50倍
GeneCIS和CIRCO的结果来自Gu等人(2024年;2023年),使用了CLIP-Large、OpenCLIP-Huge和OpenCLIP-Giant后端(Radford等人,2021年;Cherti等人,2023年)。CIReVL(Karthik等人,2024年)在DTIN和GeneCIS上的结果并未被作者完全报告。省略了ChatGPT的大小,只计算CIReVL的其他模型组件的参数(例如,BLIP2-FLANT5-XXL + OpenCLIP-Giant)。
尽管CoCa-based MagicLens-B(267M)的模型大小比其他基线(例如,CIReVL为14.6B)小50倍,但它在这些基准测试上取得了更好的性能,尤其是在DTIN上有显著优势。这一观察结果证明了我们的模型中参数共享设计引入的高参数效率以及我们的数据在实现性能强大而参数小型模型方面的强大优势。详细结果见附录表14、15和16。
对比损失Contrastive Loss的消融实验。与标准对比损失相比,在训练期间将查询图像作为硬负样本。为了探究这一设计的影响,训练了一个不包含这些硬负样本的CoCa-based MagicLens-B,并在表7中报告了结果。可以看到,没有查询负样本时,MagicLens在所有基准测试上的性能都下降了,在CIRR、CIRCO和DTIN基准测试上的下降尤为显著。此外还发现,在很多情况下,这个模型在检索时倾向于将查询图像本身排在其他图像之前,无论给定的指令是什么。这表明,区分紧密相似的图像对于提高模型的指令理解能力至关重要。重要的是,尽管使用查询负样本似乎限制了MagicLens找到相同图像的能力,但图1中的第一个例子显示,MagicLens可以泛化到在训练期间未见的指令,并成功检索到相同图像。

表7. 在训练期间将查询图像作为负样本的CoCa-based MagicLens-B的消融研究(Qry Neg)
模型架构的消融实验。在表8中提供了探索的其他模型架构的结果。在CrossAttn模型架构中,探索了各种形式的交叉注意力,报告了使用文本嵌入来关注串联的图像和文本嵌入的最佳变体。然而,即使这个架构的最佳变体也无法在大多数基准测试上达到自注意力性能。
还探索了在训练过程中冻结从CoCa(Yu等人,2022年)初始化的主干编码器的影响。FrozenEnc的结果始终不如完全训练的MagicLens。这证明了仅仅在单模态编码器的顶部训练额外层是不够的,无法产生最强大的模型。
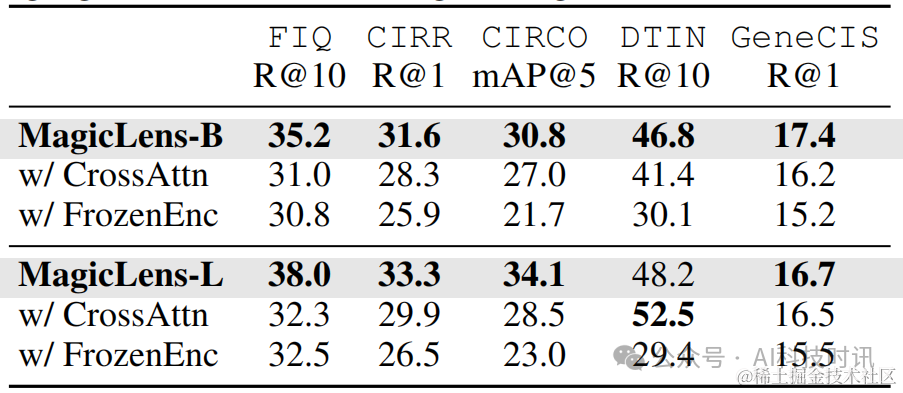
表8. MagicLens变体的结果。CrossAttn表示使用交叉注意力而不是自注意力进行模态集成的模型。FrozenEnc表示在训练期间冻结主干视觉和语言编码器的模型
在1.4M开放域图像语料库上的检索
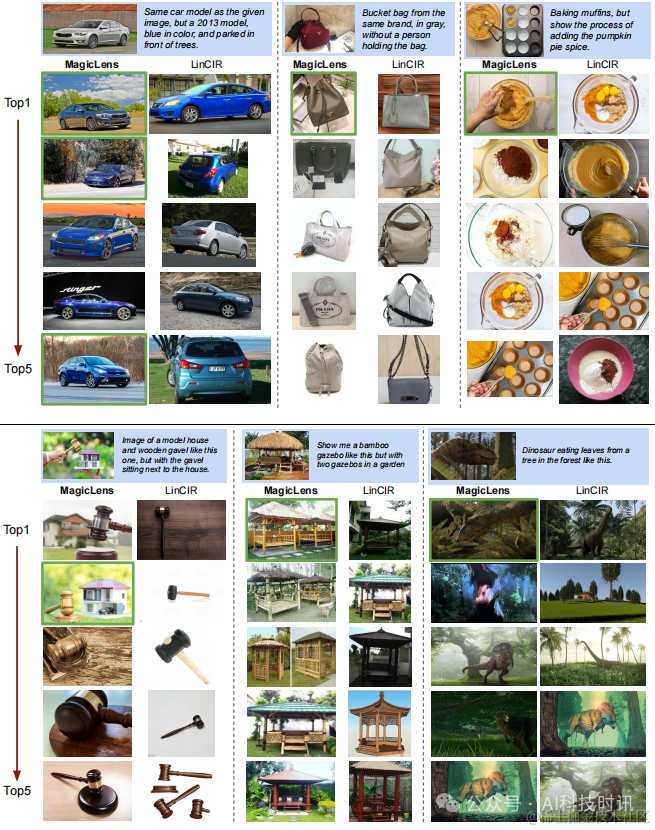
为了模拟更现实的图像检索场景,保留了140万未见的图像作为索引集,使其成为迄今为止最大的检索池。然后收集了150张图像,并将它们分为三组不同的手工编写指令:简单、复杂和超越视觉。简单和复杂的指令都用于搜索视觉上相似的图像,但它们在复杂性上有所不同。简单指令仅描述给出的图像中唯一的视觉差异(例如,同一产品不同颜色),而复杂指令有多处差异(例如,图8中的汽车和包的例子)。超越视觉的指令旨在找到与查询图像没有视觉相似性的图像(例如,在图1中“找到其他景点”的指令)。
表9比较了CoCa-based MagicLens-L和代码可用的先前最佳模型(LinCIR;Gu等人,2024年),两者都使用ViT-L后端。对于每个查询,应用一对一的人类评估来选择完全满足指令的模型检索的图像。如果两个模型都成功或都不成功,评估者会将它们标记为平局。可以观察到LinCIR可以处理简单指令,但在复杂指令上表现不佳,在超越视觉的指令上几乎完全失败。相比之下,我们的方法可以满足所有种类指令表达的多样化搜索意图,尤其在复杂(61.3对24.0)和超越视觉(80对4.7)指令上表现突出。

表9. 在包含140万图像的保留索引集上的一对一比较(胜率)。每个设置有50个带有手工编写指令的查询。结果是三位评估者的平均值
定性研究
图8展示了在包含140万图像的保留索引集上的top-1检索结果。即使是在包含多个条件的复杂指令(例如汽车和包的例子)下,MagicLens仍然能够准确理解搜索意图并检索所需图像。蛋糕的例子展示了MagicLens可以理解图像之间复杂的时序关系,这要归功于自然出现的图像对引入的关系多样性。然而,给定3D解剖查询时,MagicLens检索的图像可能不是普遍首选,因为指令以头部为例。这表明当指令表达不清晰时,我们的模型可能会返回合格而非完美的示例。更多定性研究请参阅附录D中的图11。
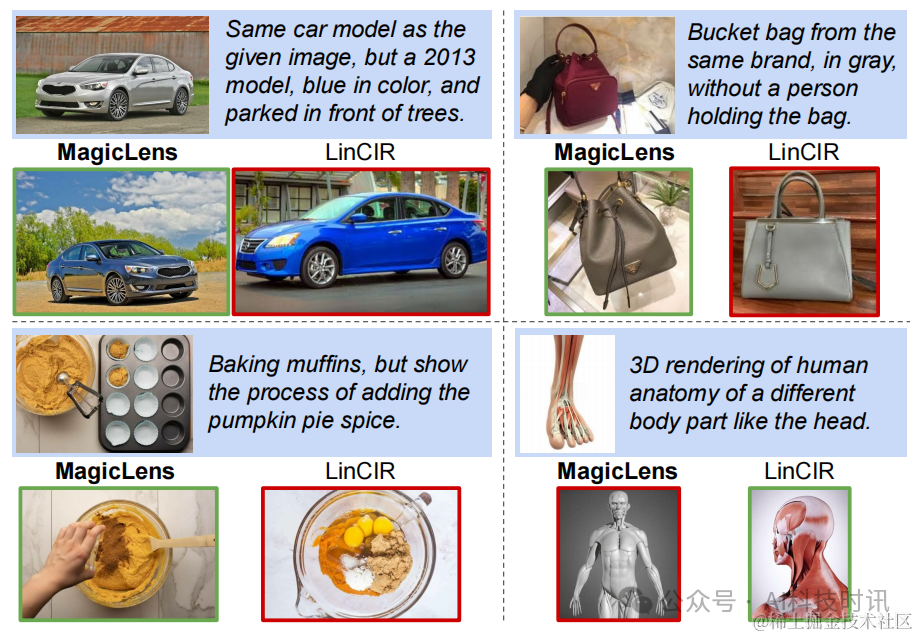
图8. CoCa-based MagicLens-L和LinCIR在包含140万图像的保留索引集上的top-1检索图像。带有蓝色背景的查询,而正确和错误的检索图像分别用绿色和红色轮廓标记。LinCIR未能正确检索汽车、包和蛋糕查询的结果,即使考虑其top-5结果(见附录中的图11)
图9展示了使用DTIN基准的域转移检索的视觉案例研究。每个域中呈现的文本指令是“在{域}中找到这个对象”,其中使用了相同的查询图像。所有top-2检索结果都是正确的,突出了MagicLens在理解概念图像关系方面的有效性。
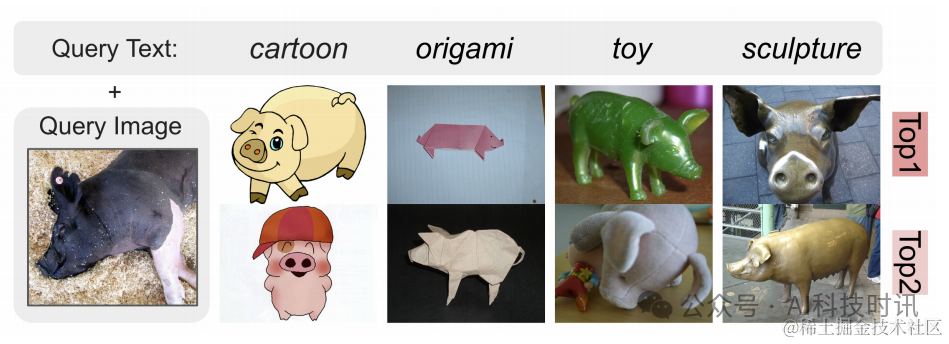
图9. 在DTIN基准上,对同一查询图像在四个域上的top-2检索结果
结论
本文介绍了MagicLens,这是一系列遵循开放式文本指令进行自监督训练的图像检索模型。尽管MagicLens的模型大小是先前最先进(SOTA)方法的50分之一,但在包括CIRCO、GeneCIS和DTIN在内的多个基准测试上,MagicLens取得了更好的结果。在140万检索图像库的人类评估显示,MagicLens能够很好地满足由开放式指令表达的多样化搜索意图,尤其是复杂和非视觉意图,这表明MagicLens在实际搜索场景中具有强大的能力和潜力。支持开放式指令的检索模型可能会对其他视觉-语言任务(如视觉问答(Antol等人,2015年;Chen等人,2023c年))和其他增强的多模态检索模型(Chen等人,2022年;Hu等人,2023b年)产生潜在益处。更重要的是,希望构建大规模合成自监督训练数据的方法可以为其他研究方向,如多模态检索、多模态表示学习等提供启示。
影响声明
本研究通过挖掘自然出现的图像对,为自监督训练信号提供了新的见解,并开发了遵循开放式指令的图像检索模型,以满足多样化的搜索意图。它可能使各种搜索场景成为可能,并具有实际应用的潜力,通过为用户提供更准确的搜索结果。因此,我们不认为我们的工作与重大伦理或社会问题相关。
致谢
感谢Jinhyuk Lee、William Cohen、Jonathan Berant、Kristina Toutanova、Boqing Gong以及其他来自Google DeepMind成员给予的建设性反馈。
参考
- Anil, R., Dai, A. M., Firat, O., Johnson, M., Lepikhin, D., Passos, A., Shakeri, S., Taropa, E., Bailey, P., Chen, Z.,Chu, E., Clark, J. H., Shafey, L. E., Huang, Y., MeierHellstern, K., Mishra, G., Moreira, E., Omernick, M.,Robinson, K., Ruder, S., Tay, Y., Xiao, K., Xu, Y., Zhang, Y., Abrego, G. H., Ahn, J., Austin, J., Barham, P., Botha, J., Bradbury, J., Brahma, S., Brooks, K., Catasta, M., Cheng, Y., Cherry, C., Choquette-Choo, C. A., Chowdhery, A., Crepy, C., Dave, S., Dehghani, M., Dev, S., Devlin, J., D´ıaz, M., Du, N., Dyer, E., Feinberg, V., Feng,F., Fienber, V., Freitag, M., Garcia, X., Gehrmann, S., Gonzalez, L., Gur-Ari, G., Hand, S., Hashemi, H., Hou,L., Howland, J., Hu, A., Hui, J., Hurwitz, J., Isard, M., Ittycheriah, A., Jagielski, M., Jia, W., Kenealy, K., Krikun,M., Kudugunta, S., Lan, C., Lee, K., Lee, B., Li, E., Li, M., Li, W., Li, Y., Li, J., Lim, H., Lin, H., Liu, Z., Liu,F., Maggioni, M., Mahendru, A., Maynez, J., Misra, V., Moussalem, M., Nado, Z., Nham, J., Ni, E., Nystrom, A.,Parrish, A., Pellat, M., Polacek, M., Polozov, A., Pope, R., Qiao, S., Reif, E., Richter, B., Riley, P., Ros, A. C.,Roy, A., Saeta, B., Samuel, R., Shelby, R., Slone, A., Smilkov, D., So, D. R., Sohn, D., Tokumine, S., Valter,D., Vasudevan, V., Vodrahalli, K., Wang, X., Wang, P., Wang, Z., Wang, T., Wieting, J., Wu, Y., Xu, K., Xu, Y.,Xue, L., Yin, P., Yu, J., Zhang, Q., Zheng, S., Zheng, C., Zhou, W., Zhou, D., Petrov, S., and Wu, Y. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C. L., & Parikh, D. (2015). VQA: Visual Question Answering. In Proceedings of ICCV.
- Asai, A., Schick, T., Lewis, P., Chen, X., Izacard, G., Riedel, S., Hajishirzi, H., & Yih, W.-t. (2023). Task-aware Retrieval with Instructions. In Findings of ACL.
- Baldrati, A., Agnolucci, L., Bertini, M., & Del Bimbo, A. (2023). Zero-shot Composed Image Retrieval with Textual Inversion. In Proceedings of ICCV.
- Brooks, T., Holynski, A., & Efros, A. A. (2023). Instructpix2pix: Learning to Follow Image Editing Instructions. In Proceedings of CVPR.
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., & Amodei, D. (2020). Language Models are Few-Shot Learners. In Proceedings of NeurIPS.
- Chen, J. & Lai, H. (2023). Pretrain like your Inference: Masked Tuning Improves Zero-Shot Composed Image Retrieval. arXiv preprint arXiv:2311.07622.
- Chen, J., Hu, H., Wu, H., Jiang, Y., & Wang, C. (2021). Learning the Best Pooling Strategy for Visual Semantic Embedding. In Proceedings of CVPR.
- Chen, W., Hu, H., Chen, X., Verga, P., & Cohen, W. W. (2022). Murag: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text. In Proceedings of EMNLP.
- Chen, X., Fang, H., Lin, T.-Y., Vedantam, R., Gupta, S., Dollar, P., & Zitnick, C. L. (2015). Microsoft Coco Captions: Data Collection and Evaluation Server. arXiv preprint arXiv:1504.00325.
- Chen, X., Djolonga, J., Padlewski, P., Mustafa, B., Changpinyo, S., Wu, J., Ruiz, C. R., Goodman, S., Wang, X., Tay, Y., et al. (2023a). Pali-x: On Scaling up a Multilingual Vision and Language Model. arXiv preprint arXiv:2305.18565.
- Chen, X., Wang, X., Changpinyo, S., Piergiovanni, A., Padlewski, P., Salz, D., Goodman, S., Grycner, A., Mustafa, B., Beyer, L., Kolesnikov, A., Puigcerver, J., Ding, N., Rong, K., Akbari, H., Mishra, G., Xue, L., Thapliyal, A. V., Bradbury, J., Kuo, W., Seyedhosseini, M., Jia, C., Ayan, B. K., Ruiz, C. R., Steiner, A. P., Angelova, A., Zhai, X., Houlsby, N., & Soricut, R. (2023b). PaLI: A jointly-scaled multilingual language-image model. In Proceedings of ICLR.
- Chen, Y., Hu, H., Luan, Y., Sun, H., Changpinyo, S., Ritter, A., & Chang, M. (2023c). Can pre-trained vision and language models answer visual information-seeking questions? In Proceedings of EMNLP.
- Cherti, M., Beaumont, R., Wightman, R., Wortsman, M., Ilharco, G., Gordon, C., Schuhmann, C., Schmidt, L., & Jitsev, J. (2023). Reproducible scaling laws for contrastive language-image learning. In Proceedings of CVPR.
- Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., Webson, A., Gu, S. S., Dai, Z., Suzgun, M., Chen, X., Chowdhery, A., Castro-Ros, A., Pellat, M., Robinson, K., Valter, D., Narang, S., Mishra, G., Yu, A., Zhao, V., Huang, Y., Dai, A., Yu, H., Petrov, S., Chi, E. H., Dean, J., Devlin, J., Roberts, A., Zhou, D., Le, Q. V., & Wei, J. (2022). Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Cohen, N., Gal, R., Meirom, E. A., Chechik, G., & Atzmon, Y. (2022). “this is my unicorn, fluffy”: Personalizing frozen vision-language representations. In Proceedings of ECCV.
- Datta, R., Joshi, D., Li, J., & Wang, J. Z. (2008). Image retrieval: Ideas, influences, and trends of the new age. ACM Comput. Surv..
- Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In Proceedings of CVPR.
- Dey, S., Riba, P., Dutta, A., Llados, J., & Song, Y.-Z. (2019). Doodle to search: Practical zero-shot sketch-based image retrieval. In Proceedings of CVPR.
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2021). An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of ICLR.
- Faghri, F., Fleet, D. J., Kiros, J. R., & Fidler, S. (2017). Vse++: Improving visual-semantic embeddings with hard negatives. arXiv preprint arXiv:1707.05612.
- Gordo, A., Almazán, J., Revaud, J., & Larlus, D. (2016). Deep image retrieval: Learning global representations for image search. In Proceedings of ECCV.
- Gu, G., Chun, S., Kim, W., Jun, H., Kang, Y., & Yun, S. (2023). Compodiff: Versatile composed image retrieval with latent diffusion. arXiv preprint arXiv:2303.11916.
- Gu, G., Chun, S., Kim, W., Kang, Y., & Yun, S. (2024). Language-only training of zero-shot composed image retrieval. In Proceedings of CVPR.
- Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., Song, D., Steinhardt, J., & Gilmer, J. (2021). The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of ICCV.
- Hu, H., Luan, Y., Chen, Y., Khandelwal, U., Joshi, M., Lee, K., Toutanova, K., & Chang, M.-W. (2023a). Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities. In Proceedings of CVPR.
- Hu, Z., Iscen, A., Sun, C., Wang, Z., Chang, K.-W., Sun, Y., Schmid, C., Ross, D. A., & Fathi, A. (2023b). Reveal: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory. In Proceedings of CVPR.
- Jia, C., Yang, Y., Xia, Y., Chen, Y.-T., Parekh, Z., Pham, H., Le, Q., Sung, Y.-H., Li, Z., & Duerig, T. (2021). Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of ICML.
- Karthik, S., Roth, K., Mancini, M., & Akata, Z. (2024). Vision-by-language for training-free compositional image retrieval. In Proceedings of ICLR.
- Kim, W., Son, B., & Kim, I. (2021). Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of ICML.
- Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., & Hoi, S. C. H. (2021). Align before fuse: Vision and language representation learning with momentum distillation. In Proceedings of NeurIPS.
- Li, J., Li, D., Xiong, C., & Hoi, S. (2022). BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of ICML.
- Li, J., Li, D., Savarese, S., & Hoi, S. (2023). BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of ICML.
- Lin, F., Li, M., Li, D., Hospedales, T., Song, Y.-Z., & Qi, Y. (2023). Zero-shot everything sketch-based image retrieval, and in explainable style. In Proceedings of CVPR.
- Lin, T., Maire, M., Belongie, S. J., Hays, J., Perona, P., Ramanan, D., Dollár, P., & Zitnick, C. L. (2014). Microsoft COCO: Common objects in context. In Proceedings of ECCV.
- Liu, Q., Xie, L., Wang, H., & Yuille, A. (2019). Semantic-aware knowledge preservation for zero-shot sketch-based image retrieval. In Proceedings of ICCV.
- Liu, Z., Rodriguez-Opazo, C., Teney, D., & Gould, S. (2021). Image retrieval on real-life images with pre-trained vision-and-language models. In Proceedings of ICCV.
- OpenAI. (2022). ChatGPT. URL https://openai.com/blog/chatgpt.
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell,
附录
A. 实现细节
图像清理和配对。使用通用爬虫,并将具有相同URL的图像视为来自同一网站的图像。如果两张图像的CLIP图像嵌入分数超过0.98,将其视为相同图像并移除。如果两个组有高比例的重复图像(80%),随机移除其中一个组。保留的最小分辨率是288x288,这与使用的CoCa模型的输入大小相匹配。用于过滤的具体阈值,设置了0.82作为CLIP图像到图像相似性的阈值和0.9作为文本到文本相似性(基于字幕)的阈值。此外,为了确保图像的独特性,目标图像必须具有与自身高度相似(0.32)且与查询图像低相似(0.18)的独特ICA标签。只有满足这些要求的图像对才会被保留用于指令生成阶段。
指令生成。通过使用各种工具和LMMs为LLM提供大量元数据扩展,包括Alt-texts、图像内容注释(ICA)标签和图像字幕。具体来说,类似于Sharma等人(2018年)的方法,使用Google自然语言API对候选Alt-texts进行词性、情感和色情标注。如果图像的Alt-texts仅包含稀有标记,或者被情感/色情检测器触发,将丢弃这些图像。对于ICA标签,利用Google视觉API为每张图像标注实体,如一般物体、位置和活动。平均而言,每张图像有25.2个精细的ICA标签。此外,在表10中为指令生成提供了指令和两个详细的演示。
指令 | 为了演示如何根据提供的ALT文本、文本标签和字幕创建一个有趣的文本查询,可以假设有两张不同的图像,并基于这些图像的元数据来生成查询。图像1:- ALT文本:一个正在滑雪的人- 文本标签:滑雪,户外,冬季活动- 字幕:滑雪者在雪山上的照片图像2:- ALT文本:一个在沙滩上晒太阳的人- 文本标签:海滩,晒太阳,休闲- 字幕:一个人在沙滩上享受阳光基于上述信息,可以创建一个查询,例如:"找到一张图像,其中有人在滑雪,而不是在沙滩上晒太阳。"这个查询结合了通用和不太具体的相似性(滑雪)和目标图像独有的所有差异(不是在沙滩上晒太阳)。这样的查询既简洁又具有指导性,可以帮助用户找到与源图像相似但内容不同的图像。 |
演示 | 根据提供的示例,可以看到两个图像都是关于保时捷汽车的定制插画,源图像是一幅保时捷Cayman GT4的插画,目标图像则是一幅1972年保时捷911蓝色的插画。因此,查询应该专注于图像的类型(保时捷汽车的定制插画),同时具体指明不同的车型和年份(1972年的保时捷911)以及颜色(蓝色)。查询可以是:"寻找一幅以相同插画风格展示的蓝色1972年保时捷911的图像。"同样,第二个例子中的两个图像都是关于Rapunzel的涂色页,源图像展示了Rapunzel在船上的场景,而目标图像则展示了Rapunzel与Flynn和头上的花朵。因此,查询应该专注于图像的类型(Rapunzel的涂色页),同时具体指明不同的场景(Rapunzel与Flynn和头上的花朵,而不是在船上,没有灯笼)。查询可以是:"寻找一幅关于Rapunzel的涂色页,但不含船或灯笼,且角色头发中的花朵更加清晰。"通过这样的查询,用户可以利用源图像的信息,同时通过文本指令指导搜索,找到与源图像相似但内容不同的图像。 |
Table 10. 使用PaLM2 (Anil et al., 2023)生成查询的详细提示
模型。在提出的数据构建流程中,最终收集了36,714,118个三元组用于预训练。对于模型架构,在视觉和语言编码器之上设计了4个随机初始化的自注意力层。此外,使用了一个注意力池化层(Yu等人,2022年)来获取最终的嵌入。遵循Jia等人(2021年)和Yu等人(2022年)的方法,在CoCa-based MagicLens的训练过程中,将图像分辨率设置为288×288,补丁大小为18×18。对于CLIP-based MagicLens,将图像分辨率设置为224×224,并使用ViT-B16和ViT-L14。对于CLIP和CoCa,使用对比图像嵌入和对比文本嵌入,这些将作为自注意力层中固定长度为2的序列进行拼接。新添加的自注意力层的数量为4,
是可学习的,初始化为0.07。将批量大小设置为2048,并在Adafactor(Shazeer和Stern,2018年)和早停EarlyStop机制下训练模型,最大训练步数为50,000步。对于新引入的参数和重新使用的CLIP或CoCa参数,学习率分别设置为2e-5和2e-6。在64和128个TPU上分别训练基础模型和大模型。两个模型的训练过程持续了六小时,并基于CIRR和CIRCO的验证集性能选择最佳检查点。
B.基线
考虑了各种基线,并详细描述如下:
- (1) PALARVA (Cohen等人,2022年)
- (2) Pic2Word (Saito等人,2023年)
- (3) SEARLE (Baldrati等人,2023年)
- (4) ContextI2W (Tang等人,2024年)
- (5) LinCIR (Gu等人,2024年) 训练了一个额外的映射网络,将给定的参考图像编码为伪词令牌。然后,它可以与实际的查询文本结合,用于文本到图像的检索。这些方法依赖于图像-字幕对来训练映射网络。此外,LinCIR引入了仅文本数据以提高映射能力。
- (6) CIReVL (Karthik等人,2024年) 是一种训练自由的方法,使用BLIP-2和FLANT5-XXL (Li等人,2023年) 进行查询图像字幕生成,使用ChatGPT (OpenAI,2022年) 进行目标图像字幕生成,使用CLIP (Radford等人,2021年;Cherti等人,2023年) 进行最终的文本到图像检索。这样的复杂检索流水线可能会限制它们的推理速度和在现实世界场景中的潜在实用性。
- (7) CompoDiff (Gu等人,2023年) 将查询文本视为条件,以指导图像嵌入的生成,并在18M合成数据上训练模型。
- (8) PLI (Chen & Lai,2023年) 在图像-字幕数据中损坏图像,并将原始图像视为目标,以在预训练阶段模拟CIR任务。
C.所有结果
在五个多模态到图像基准测试上的结果
表12、13和14展示了三个CIR基准测试(Wu等人,2021年;Liu等人,2021年;Baldrati等人,2023年)的完整结果。在表15和表16上报告了各种模型在DT和GeneCIS上的性能。一些先前的方法可能使用了更大的编码器(Gu等人,2023年;2024年)并开发了一个包括LLMs(OpenAI,2022年)和LMMs(Li等人,2023年)的检索流水线以获得性能提升。尽管如此,他们的结果仍然不如MagicLens,进而支持了图7中声称的参数效率。

表11. 在相同1M规模下,使用IP2P数据和构建数据训练的CoCa-based MagicLens-B的详细性能。

表12. FIQ基准测试(Wu等人,2021年)的完整结果。† PLI没有发布代码,所以只进行了估计
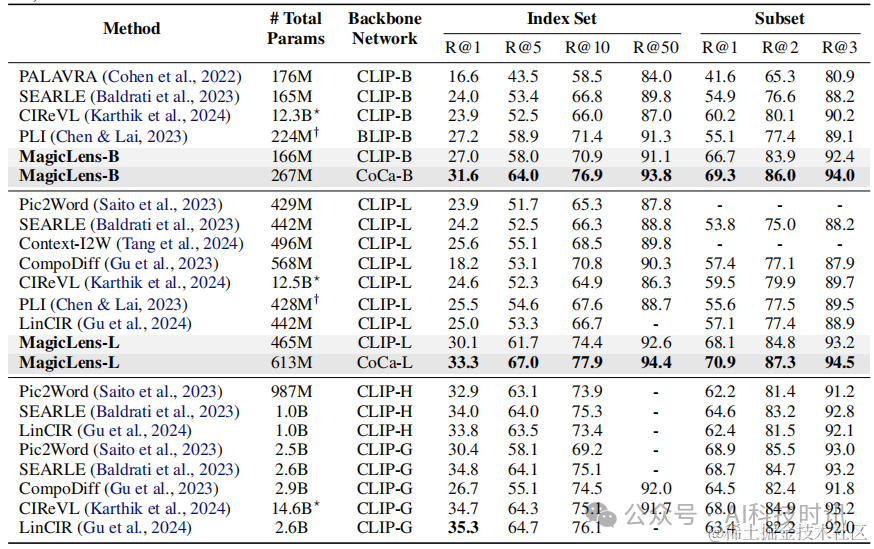
表13. CIRR基准测试(Liu等人,2021年)的完整结果。CLIP-H和CLIP-G是OpenCLIP(Cherti等人,2023年)的检查点。⋆CIReVL使用多个模型组件,我们省略了ChatGPT并报告其他组件的参数数量(例如,BLIP2-FLANT5-XXL + CLIP-G)。†PLI没有发布代码,所以只进行了估计
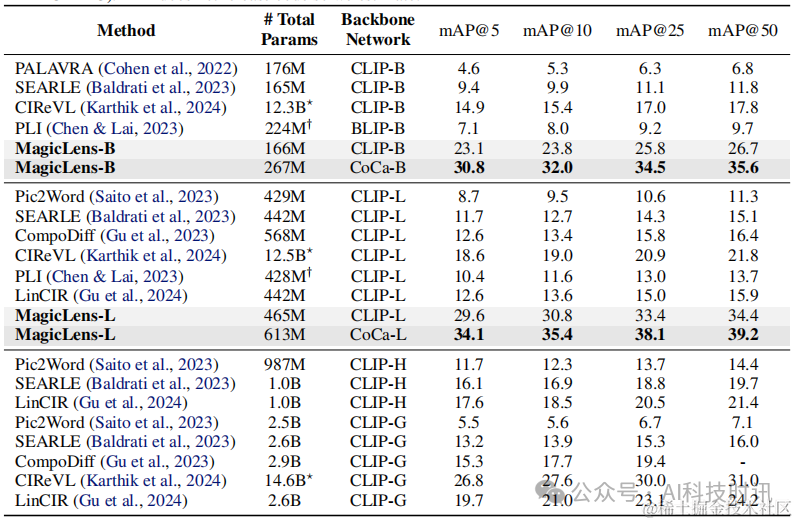
表14. CIRCO基准测试(Baldrati等人,2023年)的完整结果。CLIP-H和CLIP-G是OpenCLIP(Cherti等人,2023年)的检查点。⋆CIReVL使用多个模型组件,我们省略了ChatGPT并报告其他组件的参数数量(例如,BLIP2-FLANT5-XXL + CLIP-G)。†PLI没有发布代码,所以进行了估计
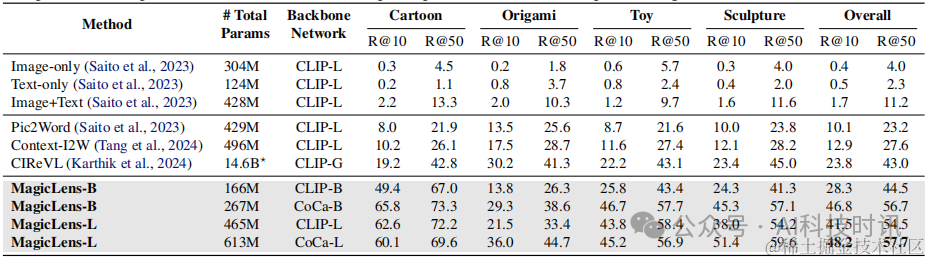
表15. DTIN基准测试(Saito等人,2023年)的完整结果。CLIP-G是OpenCLIP(Cherti等人,2023年)的检查点。⋆CIReVL使用多个模型组件,省略了ChatGPT并报告其他组件的参数数量(例如,BLIP2-FLANT5-XXL + CLIP-G)
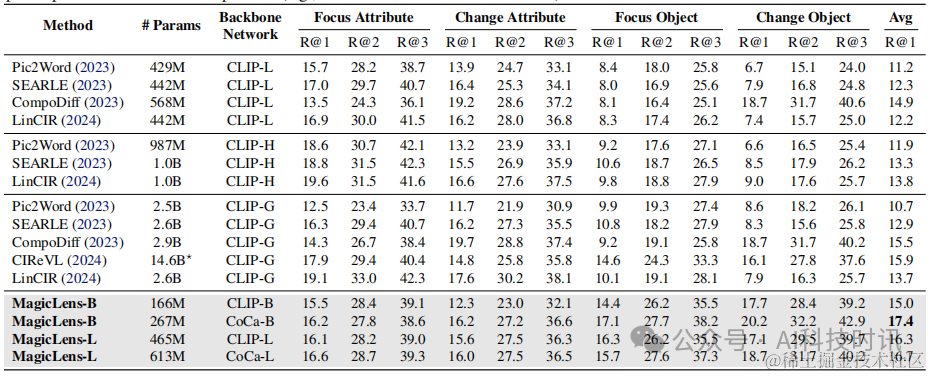
表16. GeneCIS基准测试(Vaze等人,2023年)的完整结果。⋆CIReVL使用多个模型组件,我们省略了ChatGPT并报告其他组件的参数数量(例如,BLIP2-FLANT5-XXL + CLIP-G)
数据训练比较
表11详细比较了使用IP2P数据和数据训练的CoCa-based MagicLens-B。
文本到图像检索与基于CLIP的MagicLens
在表17中列出了原始CLIP和MagicLens更新后的主干CLIP编码器的文本到图像检索结果。在基础和大模型上,文本到图像检索性能显著提升,而图像到文本检索能力略有下降。这与第4.4节中关于CoCa的结论相一致。
表格17. 零样本图像-文本检索结果。如果结果比初始化检查点更好,则用粗体标记。⋆CLIP和CoCa重新制作并用于MagicLens。†CLIP和CoCa在原始论文中报告。
基于模板的指令示例
在图10中提供了同一图像对上不同指令的具体示例。

图10. 同一图像对上基于模板和无模板指令的示例
D. 更多定性研究
展示基于CoCa的MagicLens-L和代码可用的最先进LinCIR(Gu等人,2024年)的详细top-5检索结果,如图11所示。
- 对于包查询,MagicLens可以检索同一品牌的包(第三和第四张图像),即使它们与查询图像没有共享的视觉线索(品牌标志)。
- 给定房子和法槌查询,模型成功找到了一个有趣的现实世界场景,并在前两个结果中找到了完美的示例,但LinCIR未能满足查询。这可能源于单个伪令牌对具有多个对象的图像的有限表示能力。
- 在凉亭示例上的成功表明,MagicLens可以理解简单的数字关系。

|

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号