Linux C/C++工程中可生成ELF、动/静态库文件的通用Makefile

Linux C/C++工程中可生成ELF、动/静态库文件的通用Makefile

typecodes
发布于 2024-03-29 15:26:30
发布于 2024-03-29 15:26:30
最近写了一个*nix环境下的Makefile文件,支持编译C/C++,同时能够通过参数配置生成ELF目标文件、动态链接库(.so)和静态链接库(.a)文件。
Linux C/C++工程中可生成ELF、动/静态库文件的通用Makefile
1 Makefile文件配置说明
首先,根据生成的目标文件类型(ELF可执行文件,动态链接库文件或静态链接库文件),配置GEN_LIBS、GEN_DYN_LIB、EXCUTE_BIN、STATIC_LIBS和DYNAMIC_LIBS等变量。
其次,如果生成的目标文件依赖其它库文件,那么只要将LD_LIB_DIR设置成该动态库所在的目录,LD_LIBS设置成要链接的动态库文件名即可。更建议的做法是在当前C/C++工程的配置文件中设置LIBPATH参数为动态库所在的目录,这样就不用在设置变量LD_LIB_DIR的值了,例如:
export LIBPATH=/usr/lib64/:${LIBPATH}:/home/typecodes/lib最后需要说明的是,变量$(PROJECT_DIR)表示当前C/C++工程的根路径,可以直接将本Makefile文件中的命令# PROJECT_DIR := /home/typecodes前面的#号去掉,然后设置成自己的工程根目录即可。同样,更建议在工程的配置文件中配置,例如:
export PROJECT_DIR=/home/typecodes2 使用方法
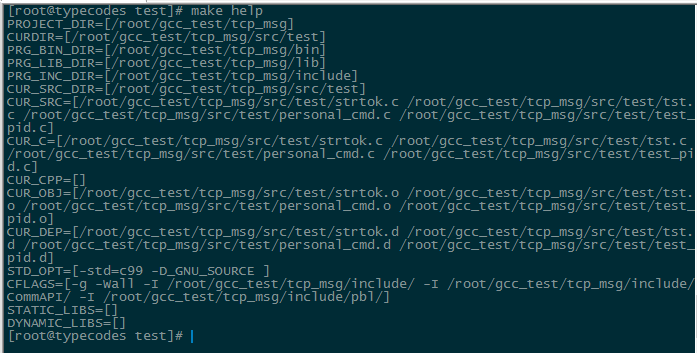
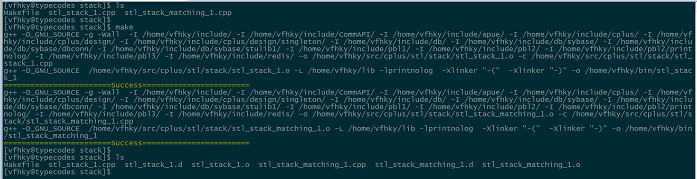
在配置好Makefile文件中的变量对应的值后,直接将该文件放置在需要编译的C/C++工程目录下面,然后执行make或者make all就可以了。伪目标clean对应的命令make clean能够清除上次执行make命令产生的影响;伪目标help对应的命令make help能够在界面上输出Makefile文件中的重要变量的值,方便调试。
执行完make命令后,在当前目录下会生成.o目标文件以及.d依赖文件,ELF可执行文件放在工程的bin目录下,动/静态库文件放在工程的lib目录下。
Linux C/C++工程中可生成ELF、动/静态库文件的通用Makefile
3 附录:Makefile文件源码
已将下面的Makefile源文件托管到两个仓库中:
1、GitHub: https://github.com/vfhky/General_Makefile;
2、Coding: https://coding.net/u/vfhky/p/General_Makefile/git。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 | ################################################################## # # FILENAME : Makefile # DESCRIPT : A general makefile to generate an ELF or a # dynamic or a static library for C/C++ project. # AUTHOR : vfhky 2015.08.07 # URI : https://typecodes.com/cseries/cppgeneralmakefile.html # ################################################################## .PHONY: all clean help all: # Some important on-off settings. You can not be too careful about them. DEBUG := y # Flag of generate a dynamic lib or a static lib: y means yes. If the target is a excutable file, it should be blank! GEN_LIBS := y # Flag of generate a dynamic lib: y means yes. It should be blank unless you want to generate a dynamic lib! GEN_DYN_LIB := y # The name of target bin file.Please let it be blank unless the target is a excutable file. EXCUTE_BIN := # Name of the static lib. It should be blank unless the target is a static lib, then the GEN_LIBS is y and GEN_DYN_LIB is blank. # STATIC_LIBS := libsrcpbl.a # Name of the dynamic lib. It should be blank unless the target is a dynamic lib, then the GEN_LIBS is y and GEN_DYN_LIB is y. DYNAMIC_LIBS := libsrcpbl.so # Environment settings. The value of PROJECT_DIR shoule be set in the *nix system as the the absolute dir path of your project. # PROJECT_DIR := /home/typecodes #CURDIR := $(PROJECT_DIR)/src/pbl CURDIR := $(shell pwd) PRG_BIN_DIR := $(PROJECT_DIR)/bin PRG_LIB_DIR := $(PROJECT_DIR)/lib PRG_INC_DIR := $(PROJECT_DIR)/include # Cross compile tools defined. You needn't modify these vars below generally. AS := as LD := ld CC := gcc CXX := g++ CPP := $(CC) -E AR := ar rcs NM := nm STRIP := strip RANLIB := ranlib STD_OPT := -std=c99 -D_GNU_SOURCE CC += $(STD_OPT) CXX += $(STD_OPT) # *nix system tools defined. You needn't modify these vars below generally. CP := cp SED := sed FIND := find MKDIR := mkdir -p XARGS := xargs MV := mv RM := rm -rf # Get .c, .cpp source files by searching from current directory. CUR_SRC_DIR = $(shell ls -AxR $(CURDIR)|grep ":"|tr -d ':') CUR_SRC := $(foreach subdir,$(CUR_SRC_DIR),$(wildcard $(subdir)/*.c $(subdir)/*.cpp)) #CUR_SRC := $(shell find . -name "*.c" -o -name "*.cpp"|sed -e 's,./,,') CUR_C := $(filter %.c, $(CUR_SRC)) CUR_CPP := $(filter %.cpp, $(CUR_SRC)) # Get the include files, object files, dependent files by searching from PRG_INC_DIR. CUR_INC_DIR = $(shell ls -AxR $(PRG_INC_DIR)|grep ":"|tr -d ':') CUR_INC := $(foreach subdir,$(CUR_INC_DIR),$(subdir)/*.h) SRC_H := $(filter %.h, $(CUR_INC)) #CUR_OBJ := $(addprefix $(PRG_BIN_DIR)/,$(strip $(CUR_CPP:.cpp=.o) $(CUR_C:.c=.o))) #CUR_OBJ := $(addprefix $(PRG_BIN_DIR)/,$(notdir $(CUR_CPP:.cpp=.o) $(CUR_C:.c=.o))) CUR_OBJ := $(strip $(CUR_CPP:.cpp=.o) $(CUR_C:.c=.o)) #CUR_DEP := $(addprefix $(PRG_BIN_DIR)/,$(notdir $(CUR_CPP:.cpp=.d) $(CUR_C:.c=.d))) CUR_DEP := $(strip $(CUR_CPP:.cpp=.d) $(CUR_C:.c=.d)) # Create directory in the header files, bin and library directory. $(foreach dirname,$(sort $(PRG_INC_DIR) $(PRG_BIN_DIR) $(PRG_LIB_DIR)),\ $(shell $(MKDIR) $(dirname))) # Complie and link variables. LD_LIBS means the dynamic or static library needed for the object file. CFLAGS := $(if $(DEBUG),-g -Wall, -O2 -Wall) CFLAGS += $(if $(GEN_DYN_LIB), $(addprefix -fPIC -I ,$(sort $(dir $(SRC_H)))), $(addprefix -I ,$(sort $(dir $(SRC_H))))) CXXFLAGS = $(CFLAGS) LDFLAGS := LD_LIB_DIR := #-L $(PRG_LIB_DIR) LD_LIBS := #-lsrcpbl -lmysqlclient XLD_FLG := -Xlinker "-(" $(LDFLAGS) -Xlinker "-)" # Add vpath. vpath %.h $(sort $(dir $(SRC_H))) vpath %.c $(sort $(dir $(CUR_C))) vpath %.cpp $(sort $(dir $(CUR_CPP))) # Generate depend files. ifneq "$(MAKECMDGOALS)" "clean" sinclude $(CUR_DEP) endif # Gen_depend(depend-file,source-file,object-file,cc). This command-package is used to generate a depend file with a postfix of .d. define gen_depend @set -e; \ $(RM) $1; \ $4 $(CFLAGS) -MM $2 | \ $(SED) 's,($(notdir $3)): ,$3: ,' > $1.tmp; \ $(SED) -e 's/#.*//' \ -e 's/^^:*: *//' \ -e 's/ *\$$//' \ -e '/^$$/ d' \ -e 's/$$/ :/' < $1.tmp >> $1.tmp; \ $(MV) $1.tmp $1; endef # Rules to generate objects file(.o) from .c or .cpp files. $(CURDIR)/%.o: %.c @$(call gen_depend,$(patsubst %.o,%.d,$@),$,$@,$(CC))<br $(CC) $(CFLAGS) -o $@ -c $< $(CURDIR)/%.o: %.cpp @$(call gen_depend,$(patsubst %.o,%.d,$@),$,$@,$(CXX))<br $(CXX) $(CXXFLAGS) -o $@ -c $< # Gen_excbin(target,CUR_OBJ,cc). This command-package is used to generate a excutable file. define gen_excbin ULT_BIN += $(PRG_BIN_DIR)/$1 $(PRG_BIN_DIR)/$1: $2 $3 $(LDFLAGS) $$^ $(LD_LIB_DIR) $(LD_LIBS) $(XLD_FLG) -o $$@ endef # Gen_libs(libs,CUR_OBJ,cc). This command-package is used to generate a dynamic lib or a static lib. define gen_libs ULT_LIBS += $(PRG_LIB_DIR)/$1 $(PRG_LIB_DIR)/$1: $2 $3 $(if $(GEN_DYN_LIB),-shared $$^ $(CXXFLAGS) $(LD_LIB_DIR) $(LD_LIBS) $(XLD_FLG) -o $$@,$$@ $$^) endef # Call gen_excbin to generate a excutale file. $(foreach bin,$(EXCUTE_BIN),$(eval $(call gen_excbin,$(bin),$(CUR_OBJ),$(CXX)))) # Call gen_libs to generate a dynamic lib. $(foreach lib,$(DYNAMIC_LIBS),$(eval $(call gen_libs,$(lib),$(CUR_OBJ),$(CXX)))) # Call gen_libs to generate a static lib. $(foreach lib,$(STATIC_LIBS),$(eval $(call gen_libs,$(lib),$(CUR_OBJ),$(AR)))) all: $(ULT_BIN) $(ULT_LIBS) clean: -$(FIND) $(CURDIR) -name "*.o" -o -name "*.d" | $(XARGS) $(RM) -$(RM) $(ULT_BIN) -$(RM) $(ULT_LIBS) help: @echo PROJECT_DIR=$(PROJECT_DIR) @echo CURDIR=$(CURDIR) @echo PRG_BIN_DIR=$(PRG_BIN_DIR) @echo PRG_LIB_DIR=$(PRG_LIB_DIR) @echo PRG_INC_DIR=$(PRG_INC_DIR) @echo CUR_SRC_DIR=$(CUR_SRC_DIR) @echo CUR_SRC=$(CUR_SRC) @echo CUR_C=$(CUR_C) @echo CUR_CPP=$(CUR_CPP) @echo CUR_OBJ=$(CUR_OBJ) @echo CUR_DEP=$(CUR_DEP) @echo STD_OPT=$(STD_OPT) @echo CFLAGS=$(CFLAGS) @echo STATIC_LIBS=$(STATIC_LIBS) @echo DYNAMIC_LIBS=$(DYNAMIC_LIBS) |
|---|
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2015-08-14 ,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号